Функции и области видимости
По синтаксису описания функций PHP, на мой взгляд, довольно близок к идеальной концепции, которую многие программисты лелеют в своем воображении[E49] . Вот несколько основных достоинств этой концепции:
r вы можете использовать параметры по умолчанию (а значит, функции с переменным числом параметров);
r области видимости переменных внутри функций представляются в древовидной форме, как и в других языках программирования;
r существует удобная инструкция return, которой так не хватает в Паскале;
r тип возвращаемого значения может быть любым;
r как мы увидим дальше, функции можно использовать не только по их прямому назначению, но и для автоматизации создания "библиотекарей" и даже написания своего собственного интерфейса библиотечных файлов.
К сожалению, разработчики PHP не предусмотрели возможность создания локальных функций (то есть одной внутри другой), как это сделано, скажем, в Паскале или в Watcom C++. Однако кое-какая эмуляция локальных функций все же есть: если функцию B() определить в теле функции A(), то она, хоть и не став локальной, все же будет "видна"
для программы ниже своего определения. Замечу для сравнения, что похожая схема существует и в языке Perl. Впрочем, как показывает практика программирования на Си (вот уже 30 лет), это не такой уж серьезный недостаток.
В системе определения функций в PHP есть и еще один небольшой недочет, который особенно неприятен тем, кто до этого программировал на других языках. Дело в том, что все переменные, которые объявляются и используются в функции, по умолчанию локальны для этой функции. При этом существует только один (и при том довольно некрасивый) способ объявления глобальных переменных — инструкция global (на самом деле есть и еще один, через массив $GLOBALS, но об этом чуть позже). С одной стороны, это повышает надежность функций в смысле их независимости от основной программы, а также гарантирует, что они случайно не изменят и не создадут глобальных переменных. С другой стороны, разработчики PHP вполне могли бы предугадать нужность инструкции, по которой все переменные функции становились бы по умолчанию глобальными — это существенно упростило бы программирование сложных сценариев.
Функции изменения регистра
Довольно часто нам приходится переводить какие-то строки, скажем, в верхний регистр, т.е. делать все прописные буквы в строке заглавными. В принципе, для этой цели можно было бы воспользоваться функцией strtr(), рассмотренной выше, но она все же будет работать не так быстро, как нам иногда хотелось бы. В PHP есть функции, которые предназначены специально для таких нужд. Вот они.
string strtolower(string $str)
Преобразует строку в нижний регистр. Возвращает результат перевода.
Надо заметить, что при неправильной настройке локали (про локаль будет рассказано чуть позже, а пока скажу только, что это набор правил по переводу символов из одного регистра в другой, переводу даты и времени, денежных единиц и т. д.) функция будет выдавать, мягко говоря, странные результаты при работе с буквами кириллицы. Возможно, в несложных программах, а также если нет уверенности в поддержке соответствующей локали операционной системой, проще будет воспользоваться "ручным"
преобразованием символов, задействуя функцию strtr():
$st=strtr($st,
"ÀÁÂÃÄÅЁÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙsÛÜÝÞß", "àáâãäåёæçèéêëìíîïðñòóôõö÷øùúûüýþÿ");
Главное достоинство данного способа — то, что в случае проблем с кодировкой для восстановления работоспособности сценария вам придется всего лишь преобразовать его в ту же кодировку, в которой у вас хранятся документы на сервере.
string strtoupper(string $str)
Переводит строку в верхний регистр. Возвращает результат преобразования. Эта функции также прекрасно работает со строками, составленными из "английских"
букв, но с "русскими" буквами может возникнуть все та же проблема.
Функции манипулирования целыми файлами
На самом деле всех перечисленных выше функций достаточно для реализации обмена с файлами любой сложности. Однако часто бывает нужно работать с файлами не построчно (или поблочно), а целиком. Функции, описанные в этом разделе, как раз для этого и предназначены.
bool copy(string $src, string $dst)
Копирует файл с именем $src в файл с именем $dst. При этом, если файл $dst на момент вызова существовал, осуществляется его перезапись. Функция возвращает true, если копирование прошло успешно, а в случае провала — false.
bool rename(string $oldname, string $newname)
Переименовывает (или перемещает, что одно и то же) файл с именем $oldname в файл с именем $newname. Если файл $newname уже существует, регистрируется ошибка, и функция возвращает false. То же происходит и при всех прочих неудачах. Если же все прошло успешно, возвращается true.

Функция не выполняет переименование файла, если его новое имя расположено в другой файловой системе (на другой смонтированной системе в Unix или на другом диске в Windows). Так что никогда не используйте rename() для получения загруженного по HTTP файла (о загрузке подробно рассказано в пятой части книги) — ведь временный каталог /tmp вашего хостинг-провайдера скорее всего располагается на отдельном разделе диска.
bool unlink(string $filename)
Удаляет файл с именем $filename. В случае неудачи возвращает false, иначе — true.

На самом-то деле файл удаляется только в том случае, если число "жестких" ссылок на него стало равным 0. Правда, эта схема специфична для Unix-систем.
list File(string $filename)
Считывает файл с именем $filename целиком и возвращает массив-список, каждый элемент которого соответствует строке в прочитанном файле. Функция работает очень быстро — гораздо быстрее, чем если бы мы использовали fopen()
и читали файл по одной строке. Неудобство этой функции состоит в том, что символы конца строки (обычно \n), не вырезаются из строк файла, а также не транслируются, как это делается для текстовых файлов.
array get_meta_tags(string $filename, int $use_include_path=false);
Функция открывает файл и ищет в нем все тэги <meta> до тех пор, пока не встретится закрывающий тэг </head>. Если очередной тэг <meta> имеет вид:
<meta name="íàçâàíèå" content="ñîäåðæèìîå">
то пара название=>содержимое
добавляется в результирующий массив, который под конец и возвращается. Функцию удобно использовать для быстрого получения всех метатегов из указанного файла (что работает гораздо быстрее, чем соответствующее использование fopen() и затем чтение и разбор файла по строкам). Если необязательный параметр $use_include_path
установлен, то поиск файла осуществляется не только в текущем каталоге, но и во всех тех, которые назначены для поиска инструкциями include и require.
Функции округления
mixed abs(mixed $number)
Возвращает модуль числа. Тип параметра $number
может быть float
или int, а тип возвращаемого значения всегда совпадает с типом этого параметра.
double round(double $val)
Округляет $val до ближайшего целого и возвращает результат, например:
$foo = round(3.4); // $foo == 3.0
$foo = round(3.5); // $foo == 4.0
$foo = round(3.6); // $foo == 4.0
int ceil(float $number)
Возвращает наименьшее целое число, не меньшее $number. Разумеется, передавать в $number целое число бессмысленно.
int floor(float $number)
Возвращает максимальное целое число, не превосходящее $number.
Функция count()
Мы можем определить размер (число элементов) в массиве при помощи стандартной функции count():
$num=count($Names); // òåïåðü â $num — ÷èñëî ýëåìåíòîâ â ìàññèâå
Сразу отмечу, что count() работает не только с массивами, но и с объектами и даже с обычными переменными (для последних count() всегда равен 1, как будто переменная — это массив с одним элементом). Впрочем, ее очень редко применяют для чего-либо, отличного от массива — разве что по-ошибке.
Функция отправки письма
bool mail(string $to, string $subject, string $msg [,string $headers])
Функция mail() посылает сообщение с телом $msg (это может быть "многострочная строка", т. е. переменная, содержащая несколько строк, разделенных символом перевода строки) [E81]по адресу $to. Можно задать сразу нескольких получателей, разделив их адреса пробелами в параметре $to. Пример:
mail("rasmus@lerdorf.on.ca ca.ok@oklab.ru,
"My Subject",
"Line 1\nLine 2\nLine 3"
);
В случае, если указан четвертый параметр, переданная в нем строка вставляется между концом стандартных почтовых заголовков (таких как To, Content-type и т. д.) и началом текста письма. Обычно этот параметр используется для задания дополнительных заголовков письма. Пример:
mail("ssb@guardian.no dk@dizain.ru",
"the subject",
"Line 1\nLine 2\nLine 3",
"From: webmaster@$SERVER_NAME\n".
"Reply-To: webmaster@$SERVER_NAME\n".
"X-Mailer: PHP/" . phpversion()
);
Необходимо добавить, что этот пример довольно-таки неказист. Гораздо лучше было бы включить указанные заголовки прямо в тело письма $msg
(в начало тела), отделив их от самого письма пустой строкой (прямо как в стандарте HTTP). То же самое применимо и к параметру $subject: лучше задавать в нем всегда пустую строку и указывать заголовок Subject в самом письме. Всегда старайтесь поступать таким образом. Далее будет ясно, зачем.
Генерация функций
В последнем примере мы рассмотрели, как можно создать 100 функций с разными именами, написав программу длиной в 2 строчки. Это, конечно, впечатляет, но мы должны жестко задавать имена функций. Почему бы не поручить эту работу PHP, если нас не особо интересуют получающиеся имена?
Листинг 24.2. Генерация "анонимных" функций
$Funcs=array();
for($i=0; $i<=100; $i++) {
$id=uniqid("F");
eval("function $id() { return $i*$i; }");
$Funcs[]=$id;
}
Теперь мы имеем список $Funcs, который содержит имена наших сгенерированных функций. Как нам вызвать какую-либо из них? Это очень просто:
echo $Funcs[12](); // âûâîäèò 144
Однако мы могли бы написать с тем же результатом и
echo Func12();
при том условии, если бы воспользовались кодом генерации функций из листинга 24.1. Кажется, что так короче? Тогда не торопитесь. Все хорошо, если мы точно знаем, что надо вызвать 12-ю функцию, но как же быть, если номер хранится в переменной — например, в $n? Вот решение:
echo $Funcs[$n](); // âûâîäèò ðåçóëüòàò ðàáîòû $n-é ôóíêöèè
Не правда ли, просто? Выглядит явно лучше, чем такой код:
$F="Func$n";
$F();

Тут нам не удастся обойтись без временной переменной $F (вариант с дополнительной eval() тоже не подойдет, т. к. у функции могут быть строковые параметры, и придется перед всеми кавычками ставить слэши, чтобы поместить их в параметр функции eval().
Оказывается, в PHP версии 4 существует функция, которая поможет нам упростить генерацию "анонимных"
функций, подобных полученным в примере из листинга 24.2. Называется она create_function().
string create_function(string $args, string $code)
Создает функцию с уникальным именем, выполняющую действия, заданные в коде $code (это строка, содержащая программу на PHP). Созданная функция будет принимать параметры, перечисленные в $args. Перечисляются они в соответствии со стандартным синтаксисом передачи параметров любой функции. Возвращаемое значение представляет собой уникальное имя функции, которая была сгенерирована. Вот несколько примеров:
$Mul=create_function('$a,$b', 'return $a*$b;');
$Neg=create_function('$a', 'return -$a;');
echo $Mul(10,20); // выводит 200
echo $Neg(2); // выводит -2
Не пропустите последнюю точку с запятой в конце строки, переданной вторым параметром create_function()!
Давайте теперь перепишем наш пример из листинга 24.2 с учетом create_function(). Это довольно несложно. Обратите внимание, насколько сократился код.
$Funcs=array();
for($i=0; $i<=100; $i++)
$Funcs[]=create_function("","return $i*$i;");
echo $Funcs[12](); // выводит 144
И последний пример применения анонимных функций — в программах сортировки с использованием пользовательских функций:
$a=array("orange", "apple", "apricot", "lemon");
usort($a,create_function('$a,$b', 'return strcmp($a,$b);'));
foreach($a as $key=>$value) echo "$key: $value<br>\n";
Генерация кода во время выполнения
Так как PHP в действительности является транслирующим интерпретатором, в нем заложены возможности по созданию и выполнению кода программы прямо во время ее выполнения. То есть мы можем писать сценарии, которые в буквальном смысле создают сами себя, точнее, свой код! Это незаменимо при написании шаблонизаторов и функций, занимающихся динамическим формированием писем. Мы поговорим о таких функциях в части V книги.
Генератор данных
Конечно, это еще далеко не весь сценарий. Вы, наверное, заметили, что сердце шаблона — цикл foreach вывода записей — использует непонятно откуда взявшуюся переменную $Book, по контексту — двумерный массив. Кроме того, при отправке формы тоже ведь нужно предусмотреть некоторые действия (а именно, добавление записи в книгу).
Мы видим, что где-то должен быть скрыт весь этот код. Он, действительно, располагается в отдельном файле с именем gbook.php. Отличительная черта этого файла — то, что в нем нет никакого намека на то, как нужно форматировать результат работы сценария. Именно поэтому я называю его генератором данных (листинг 30.2).
Листинг 30.2. Генератор данных: gbook.php
<?
define("GBook","gbook.dat"); // имя файла с данными гостевой книги
// Загружает гостевую книгу с диска. Возвращает содержание книги.
function LoadBook($fname)
{ $f=@fopen("gbook.dat","rb"); if(!$f) return array();
$Book=Unserialize(fread($f,100000)); fclose($f);
return $Book;
}
// Сохраняет содержимое книги на диске.
function SaveBook($fname,$Book)
{ $f=fopen("gbook.dat","wb");
fwrite($f,Serialize($Book));
fclose($f);
}
// Исполняемая часть сценария.
// Сначала — загрузка гостевой книги.
$Book=LoadBook(GBook);
// Обработка формы, если сценарий вызван через нее.
// Если сценарий запущен после нажатия кнопки Добавить...
if(!empty($doAdd)) {
// Добавить в книгу запись пользователя — она у нас хранится
// в массиве $New, см. форму в шаблоне. Запись добавляется,
// как водится, в начало книги.
$Book=array(time()=>$New)+$Book;
// Записать книгу на диск.
SaveBook(GBook,$Book);
}
// Все. Теперь у нас в $Book хранится содержимое книги в формате:
// array (
// время_добавления => array(
// (или id) name => имя_пользователя,
// text => текст_пользователя
// ),
// . . .
// );
// Вот теперь загружаем шаблон страницы.
include "gbook.htm";
?>
Как видим, исполняемая часть довольно небольшая и, действительно, занимается лишь подготовкой данных для их последующего вывода в шаблоне. Шаблон рассматривается этой составляющей как обычный PHP-файл, который она подключает при помощи инструкции include. Ясно, что весь код шаблона (хотя его и очень мало) выполнится в том же контексте, что и генератор данных, а значит, ему будет доступна переменная $Book.
Логически весь код можно разбить на 3 части. Первая из них — задание конфигурации сценария, в нашем случае она состоит всего лишь в определении одной-единственной константы GBook, хранящей имя файла гостевой книги. Во второй части, которую можно назвать "прикладным интерфейсом" гостевой книги, содержатся описания функций, достаточных для работы с гостевой книгой. Это, конечно, функции загрузки и сохранения наполнения книги на диске. Наконец, третья часть генератора данных обрабатывает запросы пользователей на добавление данных в книгу.
Таким образом, для работы нашего сценария нужны три файла: генератор данных, шаблон книги и файл с записями книги. В принципе, это минимум, если только не привлекать для хранения записей базу данных (что, безусловно, лучше в больших программах). Однако в нашем случае проще как раз работать с файлами, поэтому я на них и остановился.
Обратите внимание: для того чтобы теперь переделать гостевую книгу так, чтобы она использовала базу данных, а не файл, достаточно изменить всего лишь 2 функции: LoadBook() и SaveBook(). Ни других частей генератора данных, ни, тем более, шаблона это не затронет. На самом деле, такой подход не является случайностью: он очень тесно связан с трехуровневой схемой построения интерактивных сценариев, о которой мы скоро будем говорить.
в переменной QUERY_STRING сохраняется значение
r
Формат: GET сценарий?параметры HTTP/1.0
r Переменные окружения: REQUEST_URI; в переменной QUERY_STRING сохраняется значение параметры, в переменной REQUEST_METHOD — ключевое слово GET.
Этот заголовок является обязательным (если только не применяется метод POST) и определяет адрес запрашиваемого документа на сервере. Также задаются параметры, которые пересылаются сценарию (если сценарию ничего не передается, или же это обычная статическая страница, то все символы после знака вопроса и сам знак опускаются). Вместо строки HTTP/1.0 может быть указан и другой протокол — например, HTTP/1.1. Именно его соглашения и будут учитываться сервером при обработке данных, поступивших от пользователя, и других заголовков.
Строка сценарий?параметры задается в том же самом формате, в котором она входит в URL. Неплохо было бы назвать эту строку как-нибудь более реалистично, чтобы учесть возможность присутствия в ней командных параметров. Такое название действительно существует и звучит как URI (Universal Resource Identifier — Универсальный идентификатор ресурса). Очень часто его смешивают с понятием URL (вплоть до того, что это происходит даже в официальной документации по стандартам HTTP). Давайте договоримся, что в будущем я всегда буду называть словом URL полный
путь к некоторой Web-странице вместе с параметрами, и условимся, что под словом URI будет пониматься его
часть, расположенная после имени (или IP-адреса) хоста и номера порта.
Главный модуль шаблонизатора
Основной код шаблонизатора, который и выполняет всю работу, помещен в библиотеку Template.phl. Она содержит все функции, которые могут потребоваться в шаблонах и блочных страницах. Главная функция модуля— RunUrl() — "запускает" страницу, путь к которой (относительно корневого каталога сервера) передается в параметрах. Результат работы этой функции — содержимое блока Output, порожденного страницей.
В листинге 30.14 приводится полный код шаблонизатора с комментариями.
Листинг 30.14. Модуль шаблонизатора: Template.phl
<?
// Константы, задающие некоторые значения по умолчанию
define("DefGlue"," | "); // символ склейки по умолчанию
define("Htaccess_Name",".htaccess"); // имя .htaccess-файла
// Имена "стандартных" блоков
define("BlkTemplate","template"); // шаблон страницы
define("BlkOutput","output"); // этот блок выводится в браузер
define("BlkDefGlue","defaultglue"); // символ для "склейки" по умолчанию
// Рабочие переменные
$GLOBALS["BLOCK"]=array(); // массив тел всех блоков
$GLOBALS["BLOCK_INC"]=array(); // аналог $INC библиотекаря
$GLOBALS["CURBLOCK_URL"]=false; // URL текущего обрабатываемого файла
$GLOBALS["bSingleLine"]=0; // обрабатываемый файл — .htaccess?
// В следующем массиве перечислены имена функций-фильтров,
// которые будут вызваны для каждого блока, когда получено его
// содержимое. Вы, возможно, захотите добавить сюда и другие
// фильтры (например, исполняющие роль простейшего макропроцессора,
// заменяющего одни тэги на другие). Формат функций:
// void FilterFunc(string $BlkName, string &$Value, string $BlkUrl)
$GLOBALS["BLOCKFILTERS"]=array(
"_FBlkTabs",
"_FBlkGlue"
//*** Здесь могут располагаться имена ваших функций-фильтров.
);
// Возвращает тело блока по его имени. Регистр символов не учитывается.
function Blk($name)
{ return @$GLOBALS["BLOCK"][strtolower($name)];
}
// Добавляет указанный URL в список путей поиска. При этом путь
// автоматически преобразуется в абсолютный URL (за текущий каталог
// принимается каталог текущего обрабатываемого файла).
function Inc($url)
{ global $CURBLOCK_URL,$SCRIPT_NAME;
$CurUrl=$CURBLOCK_URL; if(!$CurUrl) $CurUrl=$SCRIPT_NAME;
if($url[0]!="/") $url=abs_path($url,dirname($CurUrl));
$GLOBALS["BLOCK_INC"][]=$url;
}
// Устанавливает имя текущего блока и, возможно, его значение.
// Все данные, выведенные после вызова этой функции, будут принадлежать
// телу блока $name. Если задан параметр $value, тело сразу
// устанавливается равным $value, а весь вывод просто проигноруется.
// Это удобно для коротких однострочных блоков, особенно расположенных
// в файлах .htaccess. Из того, что было выведено программой в
// стандартный поток, будут удалены начальные и концевые пробелы,
// а также вызовутся все функции-фильтры. Окончанием вывода,
// принадлежащего указанному блоку, считается конец файла либо начало
// другого блока (то есть еще один вызов Block()).
function Block($name=false, $value=false)
{ global $BLOCK,$bSingleLine,$CURBLOCK_URL;
// Объявляем некоторые флаги состояния
static $Handled=false; // в прошлый раз вывод был перехвачен
static $CurBlock=false; // имя текущего обрабатываемого блока
// Если имя блока задано, перевести его в нижний регистр
if($name!==false) $name=strtolower(trim($name));
// Вывод был перехвачен. Значит, что до этого вызова уже
// была запущена функция Block(). Теперь блок, который
// она обрабатывала, закончился, и его надо добавить в массив
// блоков (или же проигнорировать этот вывод).
if($Handled) {
// Имя предыдущего блока было задано?
if($CurBlock!==false) {
// Добавляем в массив блоков.
$BLOCK[$CurBlock]=trim(ob_get_contents());
// Если блок однострочный (из файла .htaccess), то
// удаляем все строки, кроме первой.
if(@$bSingleLine)
$BLOCK[$CurBlock]=ereg_Replace("[\r\n].*","",$BLOCK[$CurBlock]);
// Запускаем фильтры
_ProcessContent($CurBlock,$BLOCK[$CurBlock],$CURBLOCK_URL);
}
// Завершаем перехват потока вывода
ob_end_clean(); $Handled=0;
}
// Если имя блока задано (а это происходит практически всегда),
// значит, функция была вызвана нормальным образом, а не только для
// того, чтобы завершить вывод последнего блока (см. функцию Load()).
if($name!==false) {
// Перехватываем поток вывода
ob_start(); $Handled=1;
// Тело явно не задано, значит, нужно его получить путем
// перехвата выходного потока. Фактически, сейчас мы просто
// говорим системе, что текущий блок — $name, и что как только
// она встретит другой блок или конец файла, следует принять
// выведенные данные и записать их в массив.
if($value===false) {
$CurBlock=$name;
} else {
// Тело задано явно. Записать блок в массив, но все равно
// перехватить выходной поток (чтобы потом его проигнорировать).
_ProcessContent($name,$value,$CURBLOCK_URL);
$BLOCK[$name]=$value;
$CurBlock=false;
}
}
}
// Загружает файл с URL $name и добавляет блоки, которые в нем
// находились, к списку существующих блоков. Параметр $name может
// задавать относительный URL, в этом случае производится его
// поиск в глобальном массиве $INC (том же самом, который использует
// библиотекарь). Если в качестве $name задано не имя файла, а имя
// каталога, то анализируется файл .htaccess, расположенный
// в этом каталоге. На момент загрузки файла текущий каталог
// изменяется на тот, в котором расположен файл.
function Load($name)
{ global $BLOCK,$bSingleLine,$CURBLOCK_URL,$BLOCK_INC;
// Перевести все пути в $INC в абсолютные
AbsolutizeINC();
// Если путь относительный, ищем по $BLOCK_INC
$fname=false;
if($name[0]!='/') {
// Перебираем все каталоги включения
foreach($BLOCK_INC as $v) {
$fname=Url2Path("$v/$name"); // Определяем имя файла
if(file_exists($fname)) { $name="$v/$name"; break; }
}
// Если не нашли, $fname остается равной false
} else {
// Абсолютный URL — перевести его в имя файла
$fname=Url2Path($name);
}
// Обрабатываем файл, имя которого вычислено по URL.
// Сначала проверяем, существует ли такой файл.
if($fname===false || !file_exists($fname))
die("Couldn't open \"$name\"!");
// Это каталог — значит, используем .htaccess
$Single=false;
if(@is_dir($fname)) {
$name.="/".Htaccess_Name;
$fname.="/".Htaccess_Name;
$Single=1;
}
// Если файла до сих пор не существует (это может случиться, когда
// мы предписали использовать .htaccess, а его в каталоге нет),
// "мирно" выходим. Ничего страшного, если в каталоге нет .htaccess'а.
if(!file_exists($fname)) return;
// Запускаем файл. Для этого сначала запоминаем текущее состояние
// и каталог, затем загружаем блоки файла (просто выполняем файл),
// а в конце восстанавливаем состояние.
$PrevSingle=$bSingleLine; $bSingleLine=@$Single;
$SaveDir=getcwd(); chdir(dirname($fname));
$SaveCBU=$CURBLOCK_URL; $CURBLOCK_URL=$name;
// Возможно, в файле присутствуют начальные пробелы или другие
// нежелательные символы (например, в .htaccess это может
// быть знак комментария). Все они включатся в блок с
// именем _PreBlockText (его вряд ли целесообразно использовать).
Block("_PreBlockText");
// Делаем доступными все глобальные переменные.
foreach($GLOBALS as $k=>$v) if(!@Isset($$k)) global $$k;
// Запускаем файл.
include $fname;
// Сигнализируем, что блоки закончились (достигнут конец файла).
// При этом чаще всего будет осуществлена запись данных последнего
// блока файла в массив.
Block();
chdir($SaveDir);
$CURBLOCK_URL=$SaveCBU;
$bSingleLine=$PrevSingle;
}
// Главная функция шаблонизатора. Обрабатывает указанный файл $url
// и возвращает тело блока Output. В выходной поток ничего не печатается
// (за исключением предупреждений, если они возникли).
function RunUrl($url)
{ global $BLOCK;
// Собираем все блоки.
_CollectBlocks($url);
// Находим и запускаем главный шаблон. Мы делаем это в последнюю
// очередь, чтобы ему были доступны все блоки, из которых состоит
// страница. Шаблон — обычный блочный файл. В нем обязательно должен
// присутствовать блок Output.
$tmpl=@$BLOCK[BlkTemplate];
if(!$tmpl) {
die("Cannot find the template for <b>$url</b> ".
"(have you defined <tt>".BlkTemplate."</tt> block?)");
}
Load($tmpl);
// Возвращаем блок Output.
if(!isSet($BLOCK[BlkOutput])) {
die("No output from template <b>$tmpl</b> ".
"(have you defined <tt>".BlkOutput."</tt> block?)");
}
return $BLOCK[BlkOutput];
}
// Эта функция предназначена для внутреннего использования. Она собирает
// блоки из файла, соответствующего указанному $url, в том числе и блоки
// из всех .htaccess-файлов "надкаталогов".
function _CollectBlocks($url)
{ global $BLOCK;
$url=abs_path($url,dirname($GLOBALS["SCRIPT_NAME"]));
// Если путь — не /, то обратиться к "надкаталогу".
if(strlen($url)>1) _CollectBlocks(dirname($url));
// Загрузить блоки самого файла.
Load($url);
}
// Запускает все фильтры для блока.
function _ProcessContent($name,&$cont,$url)
{ foreach($GLOBALS["BLOCKFILTERS"] as $F)
$F($name,$cont,$url);
}
// "Склеивание" блоков.
// Если тело блока начинается с [name], то оно не просто
// записывается в массив блоков, а "пристыковывается" к значению,
// уже там находящемуся, причем в качестве символа-соединителя
// выступает тело блока с именем name. Если строка name не задана
// (то есть указаны []), используется блок с именем DefaultGlue,
// а если этого блока нет, то соединитель по умолчанию — " | ".
function _FBlkGlue($name,&$cont,$url)
{ global $BLOCK;
if(ereg("^\\[([^]])*]",$cont,$P)) {
$c=substr($cont,strlen($P[0])); // тело блока после [name]
$n=$P[1]; // имя соединителя
// Есть с чем "склеивать"?
if(!empty($BLOCK[$name])) {
$glue=@$BLOCK[$n];
if(!Isset($glue)) $glue=@$BLOCK[BlkDefGlue];
if(!Isset($glue)) $glue=DefGlue;
$cont=$BLOCK[$name].$glue.$c;
}
// "Склеивать" нечего — просто присваиваем.
else $cont=$c;
}
}
// Удаление начальных символов табуляции из тела блока.
// Теперь можно выравнивать HTML-код в документах с помощью табуляции.
// Это оказывается чрезвычайно удобным, если мы используем тэги,
// например, в таком контексте:
// < ?foreach($Book as $k=>$v) {? >
// <tr>
// <td>< ?=$Book['name']? ></td>
// <td>< ?=$Book['text']? ></td>
// </tr>
// < ?}? >
function _FBlkTabs($name,&$cont,$url)
{ // используем регулярное выражение в формате PCRE, т. к. это —
// единственный приемлемый способ решения задачи
$cont=preg_replace("/^\t+/m","",$cont);
}
?>
Глобальные переменные
Если вы, прочитав последние строки, уже начали испытывать сочувствие к функциям в PHP (или, если вы прикладной программист, сочувствие к разработчикам PHP), то спешу вас заверить: разумеется, в PHP есть способ, посредством которого функции могут добраться и до любой глобальной переменной в программе (не считая, конечно, передачи параметра по ссылке). Однако для этого они должны проделать определенные действия, а именно: до первого использования в своем теле внешней переменной объявить ее "глобальной" (листинг 11.10):
Листинг 11.10. Использование global
function Silly()
{ global $i;
$i=rand();
echo $i;
}
for($i=0; $i!=10; $i++) Silly();
Вот теперь-то переменная $i будет везде едина: что в функции, что во внешнем цикле (для последнего это приведет к немедленному его "зацикливанию", во всяком случае, на ближайшие несколько минут, пока rand() не выкинет 10). А вот еще один пример, который показывает удобство использования глобальных переменных внутри функции (листинг 11.11):
Листинг 11.11. Пример функции
$Monthes[1]="ßíâàðü";
$Monthes[1]="Февраль";
... è ò. ä.
$Monthes[12]="Äåêàáðü";
. . .
// Âîçâðàùàåò íàçâàíèå ìåñÿöà ïî åãî íîìåðó. Íóìåðàöèÿ íà÷èíàåòñÿ ñ 1! function GetMonthName($n)
{ global $Monthes;
return $Monthes[$n];
}
. . .
echo GetMonthName(2); // выводит "Февраль"
Согласитесь, массив $Monthes, содержащий названия месяцев, довольно объемист. Поэтому описывать его прямо в функции было бы, мягко говоря, неудобно. В то же время функция GetMonthName() представляет собой довольно преемлемое средство для приведения номера месяца к его словесному эквиваленту (что может потребоваться во многих программах). Она имеет единственный и понятный параметр: это номер месяца. Как бы мы это сделали без глобальных переменных?
Графические примитивы
Здесь мы рассмотрим минимальный набор функций для работы с картинками. Приведенный список функций не полон и постоянно расширяется вместе с развитием GD. Но все же он содержит те функции, которые вы будете употреблять в 99% случаев. За полным списком функций обращайтесь к документации или на http://ru.php.net.
Григорианский[E79] календарь
Григорианский календарь — это как раз тот самый календарь, который мы постоянно используем в своей жизни. В России он был введен Петром I в 1700 году.
Описываемые далее три функции представляют большой интерес, если вам понадобится автоматически формировать календари в сценариях. Все они имеют дело с так называемым Julian Day Count (JDC). Что это такое?
Каждой дате соответствует свой JDC. Ведь, фактически, JDC — это всего лишь число дней, прошедших с определенной даты (кажется, где-то с 4714-го года до нашей эры[E80] ).
Зачем это нужно? Например, нам заданы две даты в формате "дд.мм.гггг". Нужно вычислить количество дней между этими датами. Поставленная задача как раз легко решается через перевод обеих дат в JDC и определение разности получившихся величин.
int GregorianToJD(int $month, int $day, int $year)
Преобразует дату в формат JDC. Допустимые значения года для григорианского календаря — от 4714 года до нашей эры до 9999 года нашей эры.
string JDToGregorian(int $julianday)
Преобразует дату в формате JDC в строку, выглядящую как месяц/число/год. Наверняка затем вы захотите разбить эту строку на составляющие, чтобы работать с ними по отдельности. Для этого воспользуйтесь функцией explode():
$jd = GregorianToJD(10,11,1970);
echo "$jd<br>\n";
$gregorian = JDToGregorian($jd);
echo "$gregorian<br>\n";
$list=explode($gregorian,"/");
mixed JDDayOfWeek(int $julianday, int $mode)
Последняя функция этой серии — JDDayOfWeek() — тоже совершенно незаменима: она возвращает день недели, на который приходится указанная JDC-дата. Фактически, это единственное, чего нам не хватало бы для формирования календарика. Параметр $mode задает, в каком виде должен быть возвращен результат:
r 0 — номер дня недели (0 — воскресенье, 1 — понедельник, и т. д.);
r 1 — английское название дня недели;
r 2 — сокращение английского названия дня недели.
В PHP существует еще множество функций для работы с другими календарями — в том числе с Республиканским, Юлианским и т. д. Объем книги не позволяет привести здесь их описания.
Группирующие скобки
Последний пример наводит на рассуждения о том, нельзя ли как-нибудь сгруппировать отдельные символы, чтобы не писать по несколько раз одно и то же. В нашем примере строка abc встречается в выражении аж 3 раза. Но мы не можем написать выражение так: abc1|22|333, потому что оператор |, естественно, пытается применить себя к как можно более длинной последовательности команд.
Именно для цели управления оператором альтернативы (но не только) и служат группирующие круглые скобки (...). Нетрудно догадаться по смыслу, что выражение из последнего примера можно записать с их помощью так: abc(1|22|333).
Конечно, скобки могут иметь произвольный уровень вложенности. Это бывает полезно для сложных выражений, содержащих много условий, а также для еще одного применения круглых скобок, которое мы сейчас и рассмотрим.
Группы символов
Было бы глупо, если бы RegEx позволял нам задавать части искомых строк только непосредственно, как это было рассмотрено выше. Поэтому существуют несколько спецсимволов, обозначающих сразу группу букв. Эта возможность— один из краеугольных камней, основ регулярных выражений. Самый важный из таких знаков — точка "." — обозначает один любой символ. Например, выражение a.b имеет совпадение для строк azb или aqb, но не "срабатывает"
для, скажем, aqwb èëè ab. Позже мы рассмотрим, как можно заставить точку обозначать ровно один (или, к примеру, ровно пять) любых символов.
Но это далеко не все. Возможно, вы захотите искать не любой символ, а один из нескольких указанных. Для этого наши символы нужно заключить в квадратные скобки. К примеру, выражение a[xXyY]c соответствует строкам, в которых есть подстроки из трех символов, начинающиеся с а, затем одна из букв x, X, y, Y и, наконец, буква c. Если нужно вставить внутрь квадратных скобок символ [ или ], то следует просто поставить перед ним обратный слэш (напоминаю, в строках PHP — два
слэша), чтобы отменить его специальное действие.
Если букв-альтернатив много, и они идут подряд, то не обязательно перечислять их все внутри квадратных скобок — достаточно указать первую из них, потом поставить дефис и затем — последнюю. Такие группы могут повторяться. Например, выражение [a-z] обозначает любую букву от a до z включительно, а выражение [a-zA-Z0-9_] задает любой алфавитно-цифровой символ.
Существует и другой, иногда более удобный способ задания больших групп символов. В языке RegEx в скобках [ и ] могут встречаться не только одиночные символы, но и специальные выражения. Эти выражения определяют сразу группу символов. Например, [:alnum:]
задает любую букву или цифру, а [:digit:] — цифру. Вот полный список таких выражений:
r [:alpha:] — буква;
r [:digit:] — цифра;
r [:alnum:] — буква или цифра;
r [:space:] — пробельный символ;
r [:blank:] — пробельный символ или символы с кодом 0 и 255;
r [:cnrtl:] — управляющий символ;
r [:graph:] — символ псевдографики;
r [:lower:] — символ нижнего регистра;
r [:upper:] — символ верхнего регистра;
r [:print:] — печатаемый символ;
r [:punct:] — знак пунктуации;
r [:xdigit:] — цифра или буква от A до Z.
Как видим, все эти выражения задаются в одном и том же виде — [:что_то:]. Хочу еще раз обратить ваше внимание на то, что они могут встречаться только внутри квадратных скобок. Например, допустимы такие регулярные выражения:
abc[[:alnum:]]+ // abc, затем îäíà èëè áîëåå áóêâà èëè öèôðà
abc[[:alpha:][:punct]0] // abc, далее буква, знак пунктуации или 0
но совершенно недопустимы следующее:
abc[:alnum:]+ // íå ðàáîòàåò!
Еще одно привлекательное свойство выражений [:что_то:]
заключается в том, что они автоматически учитывают настройки локали, а значит, правильно работают с "русскими" буквами (конечно, если перед этим была вызвана функция setlocale()
с верными параметрами). Таким образом, выражение [[:alpha:]]+ удовлетворяет любому слову как на английском, так и на русском языке. Добиться этого при помощи "обычного" использования [...]
было бы очень тяжело.
Характеристика языка PHP
Дочитав до этого места, вы уже должны проникнуться мыслью, что писать сценарии на Си, мягко говоря, неудобно. (Если подобного ощущения у вас нет, значит, я плохо написал первую часть и ее придется переделывать…).
Так на чем же писать? Многие тут же ответят: "Конечно, на том, на чем обычно пишут сценарии — на Perl!". Да, это распространенная точка зрения. Однако у Perl, наряду с его неоспоримыми достоинствами, существуют и недостатки. Причем недостатки весьма серьезные. Вот один из них: Perl не приспособлен непосредственно для программирования сценариев. Это в некотором роде универсальный язык, поэтому он не поддерживает напрямую того, чего бы нам хотелось. А вот и второй: у Perl синтаксис не способствует читабельности программы. Он не похож ни на Си, ни на Паскаль (а эти языки замечательно зарекомендовали себя как самодокументирующиеся[В. О.5] ). Вообще, я сам принадлежу к той категории людей, которые очень болезненно воспринимают непродуманный синтаксис языка программирования, отсюда и мое отношение к Perl...
PHP — язык, специально нацеленный на работу в Интернете, язык с универсальным (правда, за некоторыми оговорками) и ясным синтаксисом, удивительно похожим на Си, сочетающий достоинства Perl и Си. И хотя этот язык еще довольно молодой, он (точнее, его интерпретатор) установлен уже на порядка миллиона серверов по всему миру, и цифра продолжает расти. Новое поколение PHP — четвертое — должно вообще стереть все преимущества Perl перед PHP, как с точки зрения быстродействия обработки программ (а третья версия PHP сильно отставала от Perl при обработке больших циклов), так и с точки зрения синтаксиса. Наконец, большинство PHP-сценариев (особенно не очень больших размеров) работают быстрее аналогичных им программ, написанных на Perl (конечно, если сравнивать с обычными Perl-сценариями, а не программами, запускаемыми под управлением mod_perl).
Думаю, у PHP есть лишь один серьезный недостаток, который менее выражен у Perl: это — его медлительность при работе с большими и сложными сценариями. Однако работы по преодолению этой трудности давно ведутся и, если верить разработчикам PHP, версия 4 является уже компилятором, построенным примерно на том же принципе, что и компилятор Perl. Давайте поговорим на последнюю тему чуть подробнее.
Here-документ
В четвертой версии PHP появился и еще один способ записи строковых констант, который исторически называется here-документом (встроенный документ). Фактически он представляет собой альтернативу для записи многострочных констант. Выглядит это примерно так:
$a=<<<MARKER
Äàëåå èäåò êàêîé-òî òåêñò,
âîçìîæíî, ñ ïåðåìåííûìè, êîòîðûå èíòåðïîëèðóþòñÿ:
íàïðèìåð, $name áóäåò èíòåðïîëèðîâàíà çäåñü.
MARKER;
Строка MARKER может быть любым алфавитно-цифровым идентификатором, не встречающимся в тексте here-документа в виде отдельной строки. Синтаксис накладывает 2 ограничения на here-документы:
r после <<<MARKER и до конца строки не должны идти никакие непробельные символы;
r завершающая строка MARKER; должна оканчиваться точкой с запятой, после которой до конца строки не должно быть никаких инструкций.
Эти ограничения настолько стесняют свободу при использовании here-документов, так что, думаю, вам стоит совсем от них отказаться. Например, следующий код работать не будет, как бы нам этого ни хотелось (функция strip_tags() удаляет тэги из строки):
echo strip_tags(<<<EOD);
Êàêîé-òî òåêñò ñ <b>òýãàìè [В. О.32] </b> — ýòîò ïðèìåð ÍÅ ðàáîòàåò!
EOD;
Надеюсь, в будущем разработчики PHP изменят ситуацию к лучшему, но пока они этого не сделали.
Хэш-функции
string md5(string $st)
Возвращает хэш-код строки $st, основанный на алгоритме корпорации RSA Data Security под названием "MD5 Message-Digest Algorithm". Хэш-код — это просто строка, практически уникальная [E57] для каждой из строк $st. То есть вероятность того, что две разные
строки, переданные в $st, дадут нам одинаковый хэш-код, стремится к нулю.
Я где-то читал об одном опыте, в котором принимали участие более 1000 мощных компьютеров, на протяжении года генерировавшие хэш-коды для строк, и за все время не было обнаружено ни одного совпадения MD5-кодов для различных строк. Более того, математически доказано, что они могли бы с тем же результатом заниматься этим на протяжении еще нескольких тысяч лет.
В то же время, если длина строки $st может достигать нескольких тысяч символов, то ее MD5-код занимает максимум 32 символа.
Для чего нужен хэш-код и, в частности, алгоритм MD5? Например, для проверки паролей на истинность. Пусть, к примеру, у нас есть система со многими пользователями, каждый из которых имеет свой пароль. Можно, конечно, хранить все эти пароли в обычном виде, или зашифровать их каким-нибудь способом, но тогда велика вероятность того, что в один прекрасный день этот файл с паролями у вас украдут. Если пароли были зашифрованы, то, зная метод шифрования, не составит особого труда их раскодировать. Однако можно поступить другим способом, при использовании которого даже если файл с паролями украдут, расшифровать его будет математически невозможно. Сделаем так: в файле паролей будем хранить не сами пароли, а их (MD5) хэш-коды. При попытке какого-либо пользователя войти в систему мы вычислим хэш-код только что введенного им пароля и сравним его с тем, который записан у нас в базе данных. Если коды совпадут, значит, все в порядке, а если нет — что ж, извините...
Конечно, при вычислении хэш-кода какая-то часть информации о строке $st
безвозвратно теряется. И именно это позволяет нам не опасаться, что злоумышленник, получивший файл паролей, сможет его когда-нибудь расшифровать. Ведь в нем нет самих паролей, нет даже их каких-то связных частей!
Алгоритм MD5 специально был изобретен для того, чтобы как раз и обеспечить описанную выше схему. Так как все же есть вероятность того, что у разных строк MD5-коды совпадут, то, чтобы не дать возможность злоумышленнику войти в систему, перебирая пароли с бешеной скоростью, алгоритм MD5 работает довольно медленно. И его нельзя никак убыстрить, потому что это будет уже не MD5. Так что даже на самых мощных компьютерах вряд ли получится перебирать более нескольких тысяч паролей в секунду, а это совсем маленькая скорость, капля в океане возможных MD5-кодов.
int crc32(string $str)
Функция crc32() вычисляет 32-битную контрольную сумму строки $str. То есть, результат ее работы — 32-битное (4-байтовое) целое число. Эта функция работает гораздо быстрее md5(), но в то же время выдает гораздо менее надежные "хэш-коды"
для строки. Так что, теперь, чтобы получить методом случайного подбора для двух разных строк одинаковые "хэш-коды", вам потребуется не триллион лет работы самого мощного компьютера, а всего лишь… год-другой. Впрочем, если не использовать генератор случайных чисел, а разобраться в алгоритме вычисления 32-битной контрольной суммы, эту же задачу легко можно решить буквально за секунду, потому что алгоритм crc32 имеет неизмеримо большую предсказуемость, чем MD5.
string crypt(string $str [,string $salt])
Алгоритм шифрования DES до недавнего времени был стандартным для всех версий Unix и использовался как раз для кодирования паролей пользователей (тем же самым способом, о котором мы говорили при рассмотрении функции md5()).
Но в последнее время MD5 постепенно начал его вытеснять. Это и понятно: MD5 гораздо более надежен. Рекомендую и вам везде применять md5() вместо
crypt(). Впрочем, функция crypt() все же может понадобиться вам в одном случае: если вы хотите сгенерировать хэш-код для другой программы, которая использует именно алгоритм DES (например, для сервера Apache).
Õэш-код для одной и той же строки, но с различными значениями $salt (кстати, это должна быть обязательно двухсимвольная строка) дает разные результаты. Если параметр $salt пропущен, PHP сгенерирует его случайным образом, так что не удивляйтесь работе следующего примера:
$st="This is the test";
echo crypt($st)."<br>"; // можем получить, íàïðèìåð, 7N8JKLKbBWEhg
echo crypt($st)."<br>"; // а здесь появится, íàïðèìåð, Jsk746pawBOA2
Как видите, два одинаковых вызова crypt()
без второго параметра выдают совершенно разные хэш-коды. За деталями работы функции обращайтесь к документации PHP.
Хост
Хост— с точки зрения пользователя как будто то же, что и узел. В общем-то, эти понятия очень часто смешивают. Это обусловлено тем, что любой узел является хостом. Но хост — совсем не обязательно отдельный узел, если это — виртуальный хост. Часто хост имеет собственное уникальное доменное имя. Иногда (обычно просто чтобы не повторяться) я буду называть хосты серверами, что, вообще говоря, совершенно не верно. Фактически, все, что отличает хост от узла — это то, что он может быть виртуальным. Итак, еще раз: любой узел — хост, но не любой хост — узел, и именно так я буду понимать хост в этой книге.
Хостинг
Те услуги, которые предоставляют клиентам хостинг-провайдеры.
Хостинг-провайдер (хостер)
Организация, которая может создавать хосты (виртуальные или обычные) в Интернете и продавать их различным клиентам, обычно за определенную плату. Существует множество хостинг-провайдеров, различающихся по цене, уровню обслуживания, поддержке telnet-доступа (то есть доступа в режиме терминала к операционной системе машины) и т.д. Они могут оказывать услуги по регистрации доменного имени в Интернете, а могут и не оказывать. При написании этой книги я рассчитывал, что читатель собирается воспользоваться услугами такого хостинг-провайдера, который предоставляет возможность использования PHP (их сейчас большинство). Если вы еще не выбрали хостинг-провайдера и только начинаете осваивать Web-программирование, не беда: во второй части книги подробно рассказано, как можно установить и настроить собственный Web-сервер на любом компьютере с установленной операционной системой Windows. (Это можно сделать даже на той самой машине, на которой будет работать браузер — ведь драйверу протокола TCP совершенно безразлично, где выполняется процесс, к которому будет осуществлено подключение, хоть даже и на том же самом компьютере.) Используя этот сервер, вы сможете немного потренироваться. Кроме того, он незаменим при отладке тех программ, которые вы в будущем планируете разместить на настоящем хосте в Интернете.
HTTP_ACCEPT
В этой переменной перечислены все (во всяком случае, так говорится в документации) MIME-типы данных, которые могут быть восприняты браузером. Как мы уже замечали, современные браузеры частенько ленятся и передают строку */*, что означает, что они якобы понимают любой тип.
HTTP_HOST
Доменное имя Web-сервера, на котором запустился сценарий. Эту переменную окружения довольно удобно использовать, например, для генерации полного пути, который требуется в заголовке Location, чтобы не привязываться к конкретному серверу (вообще говоря, чем меньше сценарий задействует "зашитую" в него информацию об имени сервера, на котором он запущен, тем лучше — в идеале ее не должно быть вовсе).
HTTP_REFERER
Задает имя документа, в котором находится форма, запустившая CGI-сценарий. Эту переменную окружения можно задействовать, например, для того, чтобы отслеживать перемещение пользователя по вашему сайту (а потом, например, где-нибудь распечатывать статистику самых популярных маршрутов).
HTTP_USER_AGENT
Идентифицирует браузер пользователя. Если в данной переменной окружения присутствует подстрока MSIE, то это— Internet Explorer, в противном случае, если в наличии лишь слово Mozilla, — Netscape.
Идентификатор сессии
Мы уже говорили с вами, зачем нужен идентификатор сессии (SID). Фактически, он является именем временного хранилища, которое будет использовано для хранения данных сессии между запусками сценария. Итак, один SID — одно хранилище. Нет SID, нет и хранилища, и наоборот.
В этом месте очень легко запутаться. В самом деле, как же соотносится идентификатор сессии и имя группы? А вот как: имя — это всего лишь собирательное название для нескольких сессий (то есть, для многих SID), запущенных разными пользователями. Один и тот же клиент никогда
не будет иметь два различных SID
в пределах одного имени группы. Но его браузер вполне может работать (и часто работает) с несколькими SID, расположенными логически в разных "пространствах имен".
Итак, все SID уникальны и однозначно определяют сессию на компьютере, выполняющем сценарий — независимо от имени сессии. Имя же задает "пространство имен", в которое будут сгруппированы сессии, запущенные разными пользователями. Один клиент может иметь сразу несколько активных пространств имен (то есть несколько имен групп сессий).
string session_id([string $sid])
Функция возвращает текущий идентификатор сессии SID. Если задан параметр $sid, то у активной сессии изменяется идентификатор на $sid. Делать это, вообще говоря, не рекомендуется.
Фактически, вызвав session_id() до session_start(), мы можем подключиться к любой (в том числе и к "чужой") сессии на сервере, если знаем ее идентификатор. Мы можем также создать сессию с угодным нам идентификатором, при этом автоматически установив его в Cookies пользователя. Но это — не лучшее решение,
— предпочтительнее переложить всю "грязную работу"
на PHP.
Идентификатор сессии и имя группы
Что же, теперь мы уже можем начать писать кое-какие сценарии. Но вскоре возникнет небольшая проблема. Дело в том, что на одном и том же сайте могут сосуществовать сразу несколько сценариев, которые нуждаются в услугах поддержки сессий PHP. Они "ничего не знают"
друг о друге, поэтому временные хранилища для сессий должны выбираться не только на основе идентификатора пользователя, но и на основе того, какой из сценариев запросил обслуживание сессии.
Идеология
Большинство сценариев пишутся на различных языках программирования без всякого отделения кода от шаблона страницы. Зачем же тогда нам это нужно? Что заставляет нас искать новые пути в Web-программировании?
Причина всего одна. Это— желание поручить разработку качественного и сложного сценария сразу нескольким людям, чтобы каждый из них занимался своим делом, которое, как предполагается, он знает лучше всего. Одна группа людей (назовем ее "программисты") занимается тем, что касается взаимодействия программы с пользователем и обработки данных. Другая же группа (для простоты я буду говорить о ней как о "дизайнерах"), наоборот, отвечает лишь за эстетическую часть работы. Разумеется, программисты и дизайнеры — не единственные категории, которые нужно сформировать при создании крупных сайтов. Безусловно, требуется еще одно лицо, которое бы "связывало" и координировало их между собой. Им может быть человек, не имеющий выдающихся достижений ни в Web-дизайне, ни в Web-программировании, но в то же время наделенный хорошей интуицией и знаниями. Если этого человека нет, кому-то все равно придется выполнять его работу (например, одному из программистов), что, конечно же, будет немного противоречить желаниям последнего. В результате работа над проектом затянется и, возможно, "обрастет" излишними сложностями технического характера.
Я убежден, что нельзя быть одновременно хорошим программистом и выдающимся дизайнером в указанном только что понимании. Эти две профессии взаимоисключают друг друга, поскольку требуют совершенно разных складов мышления. Если у вас нет раздвоения личности, вы без труда определите для себя, к какой категории людей принадлежите сами.
Зачем нам вообще понадобилось распределять разработку Web-сценариев по нескольким направлениям? Отвечаю последовательно. Во-первых, так создаются гораздо более качественные программы и Web-страницы. Во-вторых, сроки выполнения работы значительно сокращаются за счет организации параллельного выполнения задания. Если вас это все равно не убедило, вспомните о том, что именно так организуются практически все крупные Web-студии по всему миру.
Что же получается, если в своих сценариях вы будете смешивать код и оформление сценария? Фактически, его поддержкой и доработкой не сможет заняться никто, кроме вас самого. В самом деле: программиста будет раздражать постоянно встречающиеся вставки HTML-кода, а дизайнера — опасность случайно изменить какую-нибудь важную функцию программы. Иными словами, такой метод (да и можно ли назвать его методом?) совершенно не подходит при разработке мало-мальски крупных проектов.
С горечью отмечаю, что разработчики PHP практически не приблизили нас к решению проблемы отделения кода от шаблона страницы. Создается впечатление, что они преследовали как раз противоположные цели: максимально упростить совмещение HTML и PHP за счет снижения функциональности последнего. Когда мы будем разбирать код шаблонизатора ниже в этой главе, вы увидите, на какие "увертки" нам придется пойти, чтобы обойти все "подводные камни", невольно расставленные для нас авторами PHP.
Имя группы сессий
Что, не совсем понятно? Хорошо, тогда рассмотрим пример. Пусть разработчик A написал сценарий счетчика, приведенный в листинге 25.1. Он использует переменную $count, и не имеет никаких проблем. До тех пор, пока разработчик B, ничего не знающий о сценарии A, не создал систему статистики, которая тоже использует сессии. Самое ужасное, что он также регистрирует переменную $count, не зная о том, что она уже "занята". В результате, как всегда, страдает пользователь: запустив сначала сценарий разработчика B, а потом— A, он видит, что данные счетчиков перемешались. Непорядок!
Нам нужно как-то разграничить сессии, принадлежащие одному сценарию, от сессий, принадлежащих другому. К счастью, разработчики PHP предусмотрели такое положение вещей. Мы можем давать группам сессий непересекающиеся имена, и сценарий, знающий имя своей группы сессии, сможет получить к ней доступ. Вот теперь-то разработчики A и B могут оградить свои сценарии от проблем с пересечениями имен переменных. Достаточно в первой программе указать PHP, что мы хотим использовать группу с именем, скажем, sesA, а во второй — sesB.
string session_name([string $newname])
Эта функция устанавливает или возвращает имя группы сессии, которая будет использоваться PHP для хранения зарегистрированных переменных. Если $newname
не задан, то возвращается текущее имя. Если же этот параметр указан, то имя группы будет изменено на $newname, при этом функция вернет предыдущее имя.
Session_name() лишь сменяет имя текущей группы и сессии, но не создает новую сессию и временное хранилище! Это значит, что мы должны в большинстве случаев вызывать session_name(имя_группы) еще до ее инициализации — вызова session_start(), в противном случае мы получим совсем не то, что ожидали.
Если функция session_name()
не была вызвана до инициализации, PHP будет использовать имя по умолчанию — PHPSESID.
Кстати говоря, имя группы сессий, устанавливаемое рассматриваемой функцией, — это как раз имя того самого Cookie, который посылается в браузер клиента для его идентификации. Таким образом, пользователь может одновременно активизировать две и более сессий — с точки зрения PHP он будет выглядеть как два ли более различных пользователя. Однако не забывайте, что, случайно установив в сценарии Cookie, имя которого совпадает с одним из имен группы сессий, вы "затрете" Cookie.
Вот простой пример применения этой функции.
<?
session_name("CounterScript"
session_start();
session_register("count");
$count=@$count+1;
?>
В текущей сессии Вы открыли эту страницу <?=$count?> раз(а).
Рекомендую всегда указывать имя группы сессии вручную, не полагаясь на значение по умолчанию. За это вам скажут спасибо разработчики других сценариев, когда они захотят использовать вашу программу вместе со своими.
Имя хоста
Следом за протоколом идет имя узла, на котором размещается запрашиваемая страница (в нашем примере— www.somehost.com). Это может быть не только доменное имя хоста, но и его IP-адрес. В последнем случае, как нетрудно заметить, мы сможем обращаться только к узлам (невиртуальным хостам), потому что лишь они однозначно идентифицируются указанием их IP-адреса.
Имя и расширение файла
Задача: для имени файла в $fname установить расширение out независимо от его предыдущего расширения.
Решение:
$fname=ereg_Replace(
'([[:alnum:]])(\\.[[:alnum:].]*)?$',
'\\1.out',
$fname
);
Обратите внимание на довольно интересную структуру этого выражения: мы не можем просто "привязать"
его к концу строки при помощи $, что обусловлено спецификой работы RegEx. Мы также привязываем начало выражения к любой букве или цифре, которой оканчивается имя файла.
Имя каталога и файла
Цель: разбить полное имя файла $path на имя каталога $dir и и имя файла $fname.
Средства:
$fname = ereg_Replace(".*[\\/]","",$path);
$dir = ereg_Replace("[\\/]?[^\\/]*$","",$path);
Информационные функции
Прежде всего давайте познакомимся с двумя функциями, одна из которых выводит текущее состояние всех параметров PHP, а вторая — версию интерпретатора.
int phpinfo()
Эта функция, которая в общем-то не должна появляться в законченной программе, выводит в браузер[DK117] большое количество различной информации, касающейся настроек PHP и параметров вызова сценария. Именно, в стандартный выходной поток (то есть в браузер пользователя) печатается:
r версия PHP;
r опции, которые были установлены при компиляции PHP;
r информация о дополнительных модулях;
r переменные окружения, в том числе и установленные сервером при получении запроса от пользователя на вызов сценария;
r версия операционной системы;
r состояние основных и локальных настроек интерпретатора;
r HTTP-заголовки;
r лицензия PHP.
Как видим, вывод довольно объемист. Воочию в этом можно убедиться, запустив такой сценарий:
<?
phpinfo();
?>
Надо заметить, что функция phpinfo() в основном применяется при первоначальной установке PHP для проверки его работоспособности. Думаю, для других целей использовать ее вряд ли целесообразно — слишком уж много информации она выдает.
string phpversion()
Функция phpversion(), пожалуй, могла бы по праву занять первое место на соревнованиях простых функций, потому что все, что она делает — возвращает текущую версию PHP.[DK118]
int getlastmod()
Завершающая функция этой серии — getlastmod() — возвращает время последнего изменения файла, содержащего сценарий. Она не так полезна, как это может показаться на первый взгляд, потому что учитывает время изменения только главного файла, того, который запущен сервером, но не файлов, которые включаются в него директивами require или include. Время возвращается в формате timestamp (то есть, это число секунд, прошедших с 1 января 1970 года до момента модификации файла), и оно может быть затем преобразовано в читаемую форму, например:
echo "Ïîñëåäíåå èçìåíåíèå: ".date("d.m.Y H:i.s.", getlastmod());
// Âûâîäèò ÷òî-òî âðîäå 'Ïîñëåäíåå èçìåíåíèå: 13.11.2000 11:23.12'
Инициализация объекта. Конструкторы
До сих пор мы не особенно задумывались, каким образом были созданы объекты $Obj1 и $Obj2 и к какой таблице они прикреплены. Однако вполне очевидно, что эти объекты не должны существовать сами по себе — это просто не имеет смысла. Поэтому нам, наравне с уже описанными методами, придется написать еще один — а именно, метод, который бы:
r "привязывал"
только что созданный объект-таблицу к таблице в MySQL;
r сбрасывал индикатор ошибок;
r заполнял свойство Fields;
r делал другую работу по инициализации объекта.
Назовем это метод, например, Init():
class MysqlTable {
. . .
// Привязывает объект-таблицу к таблице с именем $TblName
function Init($TblName)
{ $this->TableName=$TblName;
$this->Error=0;
получаем и заполняем $this->Fields
}
}
. . .
$Obj=new MysqlTable; $Obj->Init("test");
А вдруг между вызовами new и Init() случайно произойдет обращение к таблице? Или кто-то по ошибке забудет вызвать Init()
для созданного объекта (что обязательно случится, дайте только время)? Это приведет к непредсказуемым последствиям. Поэтому, как и положено в ООП, мы можем завести метод вместо Init(), который будет вызываться автоматически сразу же после инструкции new
и проводить работы по инициализации объекта. Он называется конструктором, или инициализатором. Чтобы PHP мог понять, что конструктор следует вызывать автоматически, ему (конструктору) нужно дать то же имя, что и имя класса. В нашем примере это будет выглядеть так:
class MysqlTable {
function MysqlTable($TblName)
{ команды, ранее описанные в Init();
}
}
$Obj=new MysqlTable("test"); // создаем и сразу же инициализируем объект
Обратите внимание на синтаксис передачи параметров конструктору. Если бы мы случайно пропустили параметр test, PHP выдал бы сообщение об ошибке. Таким образом, теперь в программе потенциально не могут быть созданы объекты-таблицы, ни к чему не привязанные.
Инструкция array() и многомерные массивы
Вернемся к предыдущему примеру. Нам необходимо написать программу, которая по фамилии некоторого человека из группы будет выдавать его имя. Поступим так же, как и раньше: будем хранить данные в ассоциативном массиве (сразу отбрасывая возможность составить ее из огромного числа конструкций if-else как неинтересную):
$Names["Ivanov"] ="Dmitry";
$Names["Petrova"]="Helen";
Теперь можно, как мы знаем, написать:
echo $Names["Petrova"]; // âûâåäåò Helen
echo $Names["Oshibkov"]; // îøèáêà: â ìàññèâå íåò òàêîãî ýëåìåíòà!
Идем дальше. Прежде всего обратим внимание: приведенным выше механизмом мы никак не смогли бы создать пустой массив. Однако он очень часто может нам понадобиться, например, если мы не знаем, что раньше было в массиве $Names, но хотим его проинициализировать указанным путем. Кроме того, каждый раз задавать массив указанным выше образом не очень-то удобно— приходится все время однообразно повторять строку $Names...
Так вот, существует и второй способ создания массивов, выглядящий значительно компактнее. Я уже упоминал его несколько раз — это использование оператора array(). Например:
// ñîçäàåò ïóñòîé ìàññèâ $Names
$Names=array();
// ñîçäàåò òàêîé æå ìàññèâ, êàê â ïðåäûäóùåì ïðèìåðå ñ èìåíàìè $Names=array("Ivanov"=>"Dmitry", "Petrova"=>"Helen");
// ñîçäàåò ñïèñîê ñ èìåíàìè (íóìåðàöèÿ 0,1,2) $NamesList=array("Dmitry","Helen","Sergey");
Теперь займемся вопросом, как формировать двумерные (и вообще многомерные) массивы. Это довольно просто. В самом деле, я уже говорил, что значениями переменных (и значениями элементов массива тоже, поскольку PHP не делает никаких различий между переменными и элементами массива) может быть все, что угодно, в частности — опять же массив. Так, можно создавать ассоциативные массивы (а можно — списки) с любым числом измерений. Например, если кроме имени о человеке известен также его возраст, то можно инициировать массив $Names так:
$Names["Ivanov"] = array("name"=>"Dmitry","age"=>25);
$Names["Petrova"] = array("name"=>"Helen", "age"=>23);
или даже так:
$Names=array(
"Ivanov" => array("name"=>"Dmitry","age"=>25),
"Petrova"=> array("name"=>"Helen", "age"=>23)
);
Как же добраться до нужного нам элемента в нашем массиве? Нетрудно догадаться по аналогии с другими языками:
echo $Names["Ivanov"]["age"]; // íàïå÷àòàåò "25"
echo $Names["Petrova"]["bad"]; // îøèáêà: íåò òàêîãî ýëåìåíòà "bad"
Довольно несложно, не правда ли? Кстати, мы можем видеть, что ассоциативные массивы в PHP удобно использовать как некие структуры, хранящие данные. Это похоже на конструкцию struct в Си (или record в Паскале). Пожалуй, это единственный возможный способ организации структур, но он очень гибок.
Инструкция list()
Пусть у нас есть некоторый массив-список $List с тремя элементами: имя человека, его фамилия и возраст. Нам бы хотелось присвоить переменным $name, $surname и $age эти величины. Это, конечно, можно сделать так:
$name=$List[0];
$surname=$List[1];
$age=$List[2];
Но гораздо изящнее будет воспользоваться инструкцией list(), предназначенной как раз для таких целей:
list($name,$surname,$age)=$List;
Согласитесь, выглядит несколько приятнее. Конечно, list()
можно задействовать для любого количества переменных: если в массиве не хватит элементов, чтобы их заполнить, им просто присвоятся неопределенные значения.
Что, если нам нужны только второй и третий элемент массива $List?
В этом случае имеет смысл пропустить первый параметр в инструкции list(), вот так:
list(,$surname,$age)=$List;
Таким образом, мы получаем в $surname
и $age
фамилию и возраст человека, не обращая внимания на его имя в первом аргументе.
Разумеется, можно пропускать любое число элементов, как слева или справа, так и посередине списка. Главное— не забыть проставить нужное количество запятых.
Инструкция return
Синтаксис оператора return абсолютно тот же, что и в Си, за исключением одной очень важной детали. Если в Си функции очень редко возвращают большие объекты (например, структуры), а массивы они не могут возвратить вовсе (это явный прокол в концепции Си), то в PHP можно использовать return абсолютно для любых объектов (какими бы большими они ни были), причем без заметной потери быстродействия. Вот пример простой функции, возвращающей квадрат своего аргумента:
function MySqrt($n)
{ return $n*$n;
}
echo MySqrt(4); // âûâîäèò 16
Сразу несколько значений функции, разумеется, возвратить не могут. Однако, если это все же очень нужно, то можно вернуть ассоциативный массив или же список, например так (листинг11.3):
Листинг 11.3. Возвращение массива
function Silly()
{ return array(1,2,3);
}
// присваивает массиву значение array(1,2,3)
$arr=Silly();
// присваивает переменным $a, $b, $c первые значения из списка
list($a,$b,$c)=Silly();
В этом примере использован оператор list(), который мы уже рассматривали.
Если функция не возвращает никакого значения, т. е. инструкции return в ней нет, то считается, что функция возвратила ложь (то есть, false). Все же часто лучше вернуть false явно (если только функция не объявлена как процедура, или void-функция по Си-терминологии), например, задействуя return false, потому что это несколько яснее.
Int, long
Целое число, либо вещественное число (в последнем случае дробная часть отсекается), либо строка, содержащая число в одном из перечисленных форматов. Если строку не удается перевести в int, то вместо нее подставляется 0, и никаких предупреждений не генерируется!
Integer
Целое число со знаком, обычно длиной 32 бита (от –2147 483 648 до 2 147 483 647, если это еще кому-то может быть интересно).
Интерфейс
Как можно заметить из листинга 30.4, интерфейс сценария гостевой книги стал гораздо проще, чем это было с генератором данных из листинга 30.2. Файл, в котором содержится его код, называется точно так же, как и файл генератора. Это и не удивительно: "снаружи" интерфейс выглядит как полноценный генератор данных, а о существовании ядра шаблон даже и не "подозревает".
Листинг 30.4. Интерфейс: gbook.php
<?
include "kernel.php"; // Загружаем ядро.
$Book=LoadBook(GBook); // Загрузка гостевой книги.
// Обработка формы, если сценарий запущен через нее.
if(!empty($doAdd)) {
// Добавить в книгу запись пользователя.
$Book=array(time()=>$New)+$Book;
// Записать книгу на диск.
SaveBook(GBook,$Book);
}
// Загрузка шаблона не нужна — теперь, наоборот, шаблон
// вызывает интерфейс.
?>
Как видим, интерфейс занимается только той работой, для которой он и предназначен: выступает "посредником" между ядром и шаблоном. Самым первым загружается ядро — файл kernel.php (я люблю так его называть). Дальше осуществляется исключительно обработка и "расшифровка" входных данных и формирование выходных.
Интерфейс CGI
Термин CGI (Common Gateway Interface— Общий шлюзовой интерфейс) обозначает набор соглашений, которые должны соблюдаться Web-серверами при выполнении ими различных Web-приложений. Вскоре мы расшифруем его смысл гораздо более подробно. Фактически, до недавнего времени все Web-программирование представляло собой программирование CGI-приложений. В последнее время ситуация изменилась. И хотя CGI все еще остается негласным стандартом для Web-приложений, механизм работы CGI-программ несколько обновился.
В этой и следующей главах мы будем разбирать основы традиционного CGI-программирования, не касаясь напрямую PHP. В качестве языка для примеров выбран Си, поскольку его компиляторы можно найти практически в любой операционной системе, и по той причине, что он "наиболее красиво" показывает, почему… его не следует использовать в Web-программировании. Да-да, это не опечатка. Вскоре вы поймете, что я хотел сказать.
IP-адрес
Любой компьютер, подключенный к Интернету и желающий обмениваться информацией со своими "сородичами", должен иметь некоторое уникальное имя, или IP-адрес. Вот уже 30 лет (думаю, и в ближайшее десятилетие тоже) IP-адрес выглядит примерно так:
127.12.232.56
Как мы видим, это — четыре 8-разрядных числа (то есть принадлежащих диапазону от 0 до 255 включительно), соединенные точками. Не все числа допустимы в записи IP-адреса: ряд из них используется в служебных целях (например, адрес 127.0.0.1 выделен для обращения к локальной машине — той, на которой был произведен запрос, а число 255 соответствует широковещательной рассылке в пределах текущей подсети). Мы не будем здесь обсуждать эти исключения детально.
Возникает вопрос: ведь компьютеров в Интернете миллионы (а скоро будут миллиарды). Как же мы, простые пользователи, запросив IP-адрес машины, в считанные секунды с ней соединяемся? Как "оно" (и что это за "оно"?) узнает, где на самом деле расположен компьютер и устанавливает с ним связь, а в случае неверного адреса адекватно на это реагирует? Вопрос актуален, поскольку машина, с которой мы собираемся связаться, вполне может находиться за океаном, и путь к ней пролегает через множество промежуточных серверов.
В деталях вопрос определения пути к адресату довольно сложен. Однако достаточно нетрудно представить себе общую картину, точнее, некоторую ее модель. Предположим, что у нас есть 1 миллиард компьютеров (давайте завысим цифры), каждый из которых напрямую соединен с 11 (к примеру) другими через кабели. Получается этакая паутина из кабелей, не так ли? Кстати, это объясняет, почему одна из наиболее популярных служб Интернета, базирующаяся на протоколе HTTP, названа WWW
(World Wide Web, или Всемирная паутина).
Следует заметить, что в реальных условиях, конечно же, компьютеры не соединяют друг с другом таким большим количеством каналов. Вместо этого применяются всевозможные внутренние таблицы, которые позволяют компьютеру "знать", где конкретно располагаются некоторые ближайшие его соседи. То есть любая машина в Сети имеет информацию о том, через какие узлы должен пройти сигнал, чтобы достигнуть самого близкого к ней адресата — а если не обладает этими знаниями, то получает их у ближайшего "сородича" в момент загрузки операционной системы. Разумеется, размер таких таблиц ограничен и они не могут содержать маршруты до всех машин в Интернете (хотя в самом начале развития Интернета, когда компьютеров в Сети было немного, именно так и обстояло дело). Потому-то я и провожу аналогию с одиннадцатью соседями.
Итак, мы сидим за компьютером номер 1 и желаем соединиться с машиной somehost с таким-то IP-адресом. Мы даем нашему компьютеру запрос: выясни-ка у своих соседей, не знают ли они чего о somehost. Он рассылает в одиннадцать сторон этот запрос (считаем, что это занимает 0,1 с, т. к. все происходит практически одновременно — размер запроса не настолько велик, чтобы сказалась задержка передачи данных), и ждет, что ему ответят.
Что же происходит дальше? Нетрудно догадаться. Каждый из компьютеров окружения действует по точно такому же плану. Он спрашивает у своих десятерых соседей, не слышали ли они чего о somehost. Это, в свою очередь, занимает еще 0,1 с. Что же мы имеем? Всего за 0,2 с проверено уже 11´10=
=110 компьютеров. Но это еще не все, ведь процесс нарастает лавинообразно. Нетрудно подсчитать, что за время порядка 1 секунды мы "разбудим" 10 в десятой степени машин, т. е. в 10 раз больше, чем мы имеем!
Конечно, на самом деле процесс будет идти медленнее: какие-то системы могут быть заняты и не ответят сразу. С другой стороны, мы должны иметь механизм, который бы обеспечивал, чтобы одна машина не "опрашивалась" многократно. Но все равно, согласитесь, результаты впечатляют, даже если их и придется занизить для реальных условий хоть в 100 раз.
В действительности дело обстоит куда сложнее. Отличия от представленной схемы частично заключаются в том, что компьютеру совсем не обязательно "запрашивать" всех своих соседей — достаточно ограничиться только некоторыми из них. Для убыстрения доступа все возможные IP-адреса делятся на четыре группы — так называемые адреса подсетей классов A, B, C и D. Но для нас сейчас это не представляет никакого интереса, поэтому не будем задерживаться на деталях. О TCP/IP можно написать целые тома (что и делается).
Исключительная блокировка
Вернемся к нашему примеру с процессами-писателями. Каждый такой процесс страстно желает, чтобы в некоторый момент (точнее, когда он уже почти готов начать писать) он был единственным, кому разрешена запись в файл.
Он хочет стать исключительным.
Отсюда и название блокировки, которую процесс должен для себя установить. Вызвав функцию flock($f,LOCK_EX), он может быть абсолютно уверен, что все остальные процессы не начнут без разрешения писать в файл, пока он не выполнит все свои действия и не вызовет flock($f, LOCK_UN) или не закроет файл.
Откуда такая уверенность? Дело в том, что если в данный момент наш процесс не единственный претендент на запись, операционная система просто не выпустит его из "внутренностей"
функции flock(), т. е. не допустит его продолжения, пока процесс-писатель не станет единственным. Момент, когда процесс, использующий исключительную блокировку, становится активным, знаменателен еще и тем, что все остальные процессы-писатели ожидают (все в той же функции flock()), когда же он, наконец, закончит свою работу с файлом. Как только это произойдет, операционная система выберет следующий исключительный процесс, и т. д.
Что ж, давайте теперь рассмотрим, как в общем случае должен быть устроен процесс-писатель, желающий установить для себя исключительную блокировку (листинг 15.2).
Листинг 15.2. Модель процесса с исключительной блокировкой
<?
// инициализация
// . . .
$f=fopen($f,"a+") or die("Не могу открыть файл на запись!");
flock($f,LOCK_EX); // ждем, пока мы не станем единственными
// В этой точке мы можем быть уверены, что только эта
// программа работает с файлом
// . . .
fflush($f); // записываем все изменения на диск
flock($f,LOCK_UN); // говорим, что мы больше не будем работать с файлом
fclose($f);
// Завершение
// . . .
?>
Заметьте, что при открытии файла мы использовали не деструктивный режим w (который удаляет файл, если он существовал), а более "мягкий" — a+.
Это неспроста. Посудите сами: удаление файла идеологически есть изменение его содержимого. Но мы не должны этого делать до получения исключительной блокировки (вспомните пример со светофором)! Поэтому, если вам нужно обязательно каждый раз стирать содержимое файла, ни в коем случае не используйте режим открытия w — применяйте a+ и функцию ftruncate(), описанную выше. Например:
$f=fopen($f,"a+") or die("Не могу открыть файл на запись!");
flock($f,LOCK_EX); // ждем, пока мы не станем единственными
ftruncate($f,0); // очищаем все содержимое файла
Зачем мы используем fflush() перед тем, как разблокировать файл? Все очень просто: отключение блокировки не ведет к сбросу внутреннего файлового буфера, т. е. некоторые изменения могут быть "сброшены" в файл уже после того, как блокировка будет снята. Мы, разумеется, этого не хотим, вот и заставляем PHP принудительно записать все изменения на диск.

Устанавливайте исключительную блокировку, когда вы собираетесь изменять файл. Всегда используйте при этом режим открытия r, r+ или a+. Никогда не применяйте режим w. Снимайте блокировку так рано, как только сможете, и не забывайте перед этим вызвать fflush().[E71]
Использование формы
Как теперь нам сделать, чтобы пользователь мог в удобной форме ввести свое имя и возраст? Очевидно, нам придется создать что-то вроде диалогового окна Windows, только в браузере. Итак, нам понадобится обычный HTML-документ (например, с именем form.html и расположенный в корневом каталоге) с элементами этого диалога— полями ввода текста и кнопкой, при нажатии на которую запустится наш сценарий. Текст этого документа приведен в листинге 2.1.
Листинг 2.1. Документ /form.html с формой
<html><body>
<form action=script.cgi method=GET>
Ââåäèòå èìÿ:
<input type=text name="name" value="Íåèçâåñòíûé"><br>
Ââåäèòå âîçðàñò:
<input type=text name="age" value="íåîïðåäåëåííûé"><br>
<input type=submit value="Íàæìèòå êíîïêó!">
</body></html>
Вы можете заметить, что некоторые атрибуты тэгов я написал в кавычках (например, name="age"), а некоторые — нет. Как показывает практика, везде, где это не конфликтует с синтаксисом HTML (то есть, в текстах, в которых нет пробелов и букв кириллицы), можно кавычки опускать. Мне лично нравится заключать значения полей name и value в кавычки, а остальные — писать без них. Правда, стандарт на язык HTML это не допускает (он требует обязательного наличия кавычек), но большинство браузеров относится к этому весьма и весьма лояльно.
Загрузим наш документ в браузер. Получим примерно следующее:
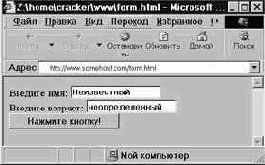
Рис. 2.1.
HTML-форма
Теперь, если занести в поле name свое имя, а в поле для возраста — возраст и нажать кнопку Нажмите кнопку!, браузер обратится к сценарию по URL, указанному в атрибуте action тэга <form> формы:
http://www.somehost.com/script.cgi
Он передаст через ? все параметры, которые помещены внутрь тэгов input в форме, отделяя их амперсандом (&). Имена полей и их значения будут разделены знаком =. Теперь вы понимаете, почему мы с самого начала использовали эти символы?
Итак, реальный URL, который будет сформирован браузером при старте сценария, будет таким (учитывая, что на странице был пользователь по имени Vasya и ему 20 лет):
http://www.somehost.com/script.cgi?name=Vasya&age=20
Самое, пожалуй, полезное, что можно вынести из рассмотренного примера, — то, что все URL-перекодирования и преобразования осуществляются браузером автоматически. То есть, пользователю теперь совершенно не нужно об этом задумываться и ломать голову над путаницей шестнадцатеричных кодов и управляющих символов.
Использование карманов в функции сопоставления
И даже на том, что было описано выше, возможности карманов не исчерпываются. Мы можем задействовать содержимое карманов и в функции ereg()— раньше, чем закончится сопоставление. А именно, управлять ходом поиска на основе данных в карманах.
В качестве примера рассмотрим такую далеко не праздную задачу. Известно, что в строке есть подстрока, обрамленная какими-то HTML-тэгами (например, <b> или <pre>), но неизвестно, какими. Требуется поместить эту подстроку в карман, чтобы в дальнейшем с ней работать. Разумеется, закрывающий тэг должен соответствовать открывающему — например, к тэгу <b> парный — </b>, а к <pre> — </pre>.
Задача решается с помощью такого регулярного выражения:
<([[:alnum:]]+)>([^<]*)</\1>
При этом результат окажется во втором кармане, а имя тэга — в первом. Вот как это работает: PHP пытается найти открывающий тэг, и, как только находит, записывает его имя в первый карман (так как это имя обрамлено в выражении первой парой скобок). Дальше он смотрит вперед и, как только наталкивается на </, определяет, следует ли за ним то самое имя тэга, которое у него лежит в первом кармане. Это действие заставляет его предпринять конструкция \1, которая замещается на содержимое первого кармана каждый раз, когда до нее доходит очередь. Если имя не совпадает, то такой вариант PHP отбрасывает и "идет" дальше, а иначе сигнализирует о совпадении.
Вот фрагмент программы, который все описанное делает тремя строчками:
$str = "Hello, this <b>word</b> is bold!";
if(ereg("<([[:alnum:]]+)>([^<]*)</\\1>",$str,$Pockets))
echo "Ñëîâî '$Pockets[2]' îáðàìëåíî òýãîì '<$Pockets[1]>'";
Использование карманов в функции замены
Мы рассмотрели только самый простой способ использования карманов — прямой их просмотр после выполнения поиска. Однако возможности, предоставляемые языком RegEx, куда шире. Особенно часто эти возможности применяются для замены с помощью регулярных выражений.
Предположим, нам нужно все слова в строке, начинающиеся с "доллара" $, сделать "жирными", — обрамить тэгами <b> и </b>, — для последующего вывода в браузер. Это может понадобиться, если мы хотим текст некоторой программы на PHP вывести так, чтобы в нем выделялись имена переменных. Очевидно, выражение для обнаружения имени переменной в строке будет таким: \$[a-zA-Z_][[:alnum:]]*.
Но как нам использовать его в функции ereg_Replace()? Вот фрагмент программы, которая делает это:
$str="<? $a=10; for($i=0; $i<10; $i++) echo $i; ?> // ê ïðèìåðó
$str=ereg_Replace("(\\$[a-zA-Z_][[:alnum:]]*)","<b>\\1</b>",$str);
Пожалуйста, обратите опять внимание на то, что слэши должны удваиваться.
Нетрудно догадаться, как "оно"
работает: просто во время замены везде вместо сочетания \1 подставляется содержимое кармана номер 1.
Использование регулярных выражений в PHP
Вернемся на минуту опять к практике. Любое регулярное выражение в PHP— это просто строка, его содержащая, поэтому функции, работающие с регулярными выражениями, принимают их в параметрах в виде обычных строк.
Использование самопереадресации
Термин самопереадресация (или, в английском варианте, self-redirect) означает свойство сценария подавать в браузер клиента запрос, заставляющий его (браузер) заново выполнить и загрузить этот сценарий с сервера. Звучит, как языческое заклинание, не правда ли? Пожалуй, с первого взгляда не совсем ясно, зачем же может понадобиться эта хваленая самопереадресация в Web-программировании.
Рассмотрим пример. Предположим, у нас имеется сценарий— гостевая книга наподобие той, эскиз которой мы рассматривали в главе 30. С точки зрения пользователя сценарий представляет собой страницу с адресом http://www.ourserver.ru/book/index.html. Если набрать этот адрес в браузере, появится, во-первых, форма с предложением добавить новое сообщение в книгу, а во-вторых, список ранее добавленных "посланий". В атрибуте action тэга <form>
указан адрес той же самой страницы index.html (это вписывается в трехуровневую схему разработки сценариев), поэтому после набора сообщения и нажатия на кнопку отправки фактически снова загружается та же самая страница. Только перед ее загрузкой генератор данных гостевой книги определяет, что необходимо добавить новую запись, и делает это.
В общем-то, довольно стандартная схема. Пусть пользователь набрал свое послание и отправил его на сервер. Перед ним появится список сообщений, первым из которых будет его собственное. Пока вроде бы все верно. И теперь пользователь, ничего не подозревая, нажимает на кнопку Обновить
в браузере, заставляя последний, как он думает, перезагрузить страницу гостевой книги.
Но в действительности происходит совсем не то, что он ожидает. Если данные формы были посланы методом POST, браузер выведет на экран диалоговое окно запроса примерно такого содержания: "Вы пытаетесь обновить данные страницы, которая была сгенерирована с применением метода POST. Повторить отправку данных (да или нет)?" Если пользователь нажмет кнопку Нет, то гостевая книга не перезагрузится, а появится совершенно бесполезная стандартная страница с сообщением о том, что "данные устарели". Если же он подтвердит вторичную отправку данных, его сообщение будет добавлено в книгу еще раз, а потому "размножится". Довольно нетрудно понять, почему так происходит: ведь браузер "не знает", что в действительности пользователь хочет лишь вторично "зайти" на адрес страницы книги, а не повторить отправку всех данных формы.
Однако ситуация становится еще плачевнее, если мы применяем в нашей гостевой книге метод GET. В этом случае при нажатии на кнопку Обновить браузер "без лишних разговоров" пошлет данные формы на сервер повторно, так что сообщение будет лишний раз добавлено в гостевую книгу без предупреждений. И это тоже понятно: ведь метод GET — не что иное, как простое изменение URL страницы, а именно, добавление в его конец символа ?, после которого следуют параметры (в том числе текст записи).
Впрочем, метод GET
практически никогда не применяется в интерактивных сценариях, таких как гостевые книги, форумы и т. д. Мы уже говорили в первой части книги на эту тему, но она настолько важна, что я повторюсь. Если для одних и тех же данных формы при их многократной отправке страница всегда выглядит одинаково, значит, эти данные логично передавать методом GET. В противном случае необходимо применять метод POST. Такое положение вещей связано также и с тем, что некоторые proxy-серверы могут кэшировать страницы, полученные методом GET, но они никогда не кэшируют их при использовании POST.
Самопереадресация — это как раз то средство, которое позволяет разрешить рассмотренный конфликт в сторону пользователя. В самом деле, предположим, что при получении уведомления о новом сообщении генератор данных вставляет их в базу данных, а затем посылает браузеру заголовок, заставляющий его перезагрузить страницу гостевой книги. В этом случае страница уже не будет представлять собой результат работы метода POST, это будет обычный HTML-документ, загруженный с сервера, как будто бы пользователь считал файл только что самостоятельно и "вручную". Неудивительно, что кнопка браузера Обновить будет работать так, как ей и положено.
Впрочем, при использовании самопереадресации очень легко наткнуться на один неприятный "подводный камень". Это — ошибка некоторых версий браузера Netscape, заключающаяся в том, что любые страницы, полученные им в результате самопереадресации, он ошибочно принимает за пустые (и соответственно отображает). И все же выход есть: достаточно немного модифицировать URL страницы, чтобы браузер "подумал", что это уже другой документ, а не тот же самый. Листинг 33.3 показывает, как это можно сделать. В целях экономии места я разместил шаблон страницы и генератор данных в одном файле.
Листинг 33.3. Самопереадресация
<?
// Считываем содержимое базы данных.
$Book=@Unserialize(join("",File("book.dat")));
if(!$Book) $Book=array();
// Проверяем, не нужно ли добавить запись...
if(@$Go) {
array_unshift($Book,$Text);
$f=fopen("book.dat","w");
fwrite($f,Serialize($Book));
fclose($f);
// Внимание! Самопереадресация. Обратите внимание на то,
// какой заголовок мы посылаем.
Header("Location: http://$HTTP_HOST$REQUEST_URI?".time());
exit; // Завершить сценарий.
}
?>
<form action=sr.php method=post>
Введите текст:<br>
<input type=text name=Text><br>
<input type=submit name=Go value="Go!">
</form>
<?foreach($Book as $k=>$v) {?>
<?=$v?>
<hr>
<?}?>
Мы обеспечиваем "уникальность" URL страницы гостевой книги за счет добавления в его конец текущего времени в секундах, прошедших с 1 января 1970 года (так называемый Unix timestamp). Вряд ли пользователь будет обновлять страницу чаще, чем раз в секунду, поэтому такой способ прекрасно подходит для наших целей.
Обратите внимание на то, что в заголовке Location мы передаем полный URL страницы, включая имя хоста. Большинство браузеров умеют "понимать" и сокращенные пути (например, без указания имени сервера), но некоторые — нет, так что лучше не искушать судьбу.
Ядро
Ядро— это самая ответственная, но, на мой взгляд, в то же время и самая скучная часть работы программиста. Действительно, оно напрямую не взаимодействует с шаблоном страницы, а значит, не имеет права "общаться" с пользователем.
Ядро в идеале должно содержать лишь набор функций, которые позволяют исчерпывающим образом работать с объектом программы. В этом смысле идеально его объектно-ориентированное построение. Об объектно-ориентированном программировании на PHP будет вкратце рассказано в главе 31, а пока не будем усложнять и без того "скользкую"
задачу и посмотрим, что представляет собой ядро нашей гостевой книги (листинг 30.5).
Листинг 30.5. Ядро: kernel.php
<?
// Загружаем конфигурацию.
include "config.php";
// Загружает гостевую книгу с диска. Возвращает содержимое книги.
function LoadBook($fname)
{ $f=@fopen("gbook.dat","rb");
if(!$f) return array();
$Book=Unserialize(fread($f,100000));
fclose($f);
return $Book;
}
// Сохраняет данные книги на диске.
function SaveBook($fname,$Book)
{ $f=fopen("gbook.dat","wb");
fwrite($f,Serialize($Book));
fclose($f);
}
?>
Действительно, здесь нет ничего, кроме определений функций и… еще одной инструкции include (вздохните с облегчением — на этот раз последней). Она добавляет конфигурационные данные нашей книги — всего лишь одну-единственную константу GBook, определяющую имя файла, в котором гоствевая книга и будет храниться. "Для порядка" приведу и его (листинг 30.6).
Листинг 30.6. Конфигурация: config.php
<?
define("GBook","gbook.dat"); // имя файла с данными книги
?>
Что же у нас получилось в результате? Мы "растянули" простой сценарий на целых 5 файлов (если считать еще и .htaccess, то на 6). Что ж, если вы так думаете, я с вами соглашусь. Тут все дело в том, что для простых сценариев (а именно такой мы и рассматривали) трехуровневая схема построения оказывается чересчур уж "тяжеловесной". Про такую ситуацию в народе говорят: "из пушки по воробьям". Что же касается сложных систем, не следует забывать, что "единственность" ядра может сэкономить нам количество файлов, если у комплекса много различных интерфейсов (например, разветвленная система администрирования), не говоря уже о простоте отладки и поддержки. Кроме того, можно полностью разделить работу по написанию ядра и интерфейса между несколькими людьми.
Явное использование константы SID
В PHP существует одна специальная константа с именем SID. Она всегда содержит имя группы текущей сессии и ее идентификатор в формате имя=идентификатор. Вспомните: именно в таком формате данные принимаются, когда они приходят из Cookies браузера. Таким образом, нам достаточно просто-напросто передать значение константы SID в сценарий, чтобы он "подумал", будто бы данные пришли из Cookies. Вот пример:
Листинг 25.3. Sesget.php: простой пример использования сессий без Cookies
<?
session_name("test");
session_start();
session_register("count");
$count=@$count+1;
?>
<body>
<h2>Ñ÷åò÷èê</h2>
 òåêóùåé ñåññèè ðàáîòû ñ áðàóçåðîì Âû îòêðûëè ýòó ñòðàíèöó
<?=$count?> ðàç(à). Çàêðîéòå áðàóçåð, ÷òîáû îáíóëèòü ýòîò ñ÷åò÷èê.<hr>
<a href=sesget.php?<?=SID?>>Click here!</a>
</body>
Если набрать в браузере адрес вроде такого:
http://www.somehost.ru/sesget.php
то создастся новая сессия с уникальным идентификатором. Разумеется, если сразу же нажать кнопку Обновить, счетчик не увеличится, потому что при каждом запуске будет создаваться новое временное хранилище— у PHP просто нет информации об идентификаторе пользователя. Теперь обратите внимание на предпоследнюю строчку листинга 25.3. Видите, как хитро мы передаем в сценарий, запускаемый через гиперссылку, данные об идентификаторе текущей сессии? Теперь с его точки зрения они якобы пришли из Cookies…
Все будет работать так, как описано, только в том случае, если в браузере действительно отключены Cookies. Если же они включены, PHP просто не будет генерировать константу SID (она будет пустой) и задействует Cookies. Все вполне логично.
Эффект прозрачности
Функцию imageColorClosest() можно и нужно использовать, если мы не хотим допустить разрастания палитры и уверены, что требуемый цвет в ней уже есть. Однако есть и другое, гораздо более важное, ее применение — определение эффекта прозрачности для изображения. "Прозрачный"
цвет рисунка — это просто те точки, которые в браузер не выводятся[E98] [DK99] . Таким образом, через них "просвечивает" фон. Прозрачный цвет у картинки всегда один, и задается он при помощи функции imageColorTransparent().
int imageColorTransparent(int $im [,$int col])
Функция imageColorTransparent()
указывает GD, что соответствующий цвет $col (заданный своим идентификатором) в изображении $im должен обозначиться как прозрачный. Возвращает она идентификатор установленного до этого прозрачного цвета, либо false, если таковой не был определен ранее.
Не все форматы поддерживают задание прозрачного цвета — например, JPEG не может его содержать.
Например, мы нарисовали при помощи GD птичку на кислотно-зеленом фоне и хотим, чтобы этот фон как раз и был "прозрачным"
(вряд ли у птички есть части тела такого цвета, хотя с нашей экологией все может быть...). [E100] [DK101] В этом случае нам потребуются такие команды:
$tc=imageColorClosest($im,0,255,0);
imageColorTransparent($im,$tc);
Обратите внимание на то, что применение функции imageColorAllocate() здесь совершенно бессмысленно, потому что нам нужно сделать прозрачным именно тот цвет, который уже присутствует в изображении, а не новый, только что созданный.
Эмуляция браузера через telnet
Между прочим, при передаче запроса браузер "притворяется" пользователем, который запустил telnet-клиента (программу, которая, грубо говоря, умеет подключаться к заданному IP-адресу и порту, посылать по нему то, что набирается на клавиатуре, и отображать на экране поступающие "снаружи" данные) и вводит строки заголовков вручную— т. е., в текстовом виде. Например, вместо того чтобы набрать в браузере http://www.somehost.com/, попробуйте в командной строке ОС (Unix, Windows 95/98/NT/2000 или любой другой) выполнить следующие команды (вместо <Enter> нажимая соответствующую клавишу):
telnet www.somehost.com 80<Enter>
GET /index.html HTTP/1.0<Enter>
<Enter>
Вы увидите, как перед вами промелькнут строки HTML-документа index.html. Очень рекомендую проделать описанную процедуру, чтобы избавиться от духа мистицизма при упоминании о протоколе HTTP. Все это не так сложно, как иногда может показаться.
Если у вас указанная процедура не удалась, и сервер все время шлет сообщение "Bad Request", то проверьте регистр символов, в котором вы набираете команды. Все буквы должны быть заглавными, а название протокола HTTP/1.0 — идти без пробелов.
Посмотрим теперь, как работает сервер. А происходит все следующим образом: он считывает все заголовки запроса и дожидается маркера "\n\n" (или, что то же самое, "пустого" заголовка), а как только его получает, начинает разбираться — что же ему за информация пришла, и выполнять соответствующие действия.
С помощью заголовков реализуются такие механизмы, как контроль кодировок, Cookies, метод POST и т. д. Если же сервер не понимает какого-то заголовка, он его либо пропускает, либо жалуется отправителю (в зависимости от воли администратора, который настраивал сервер).
Эмуляция функции virtual()
Функция virtual()
работает только в том случае, если PHP установлен как модуль Apache. Проблемы начинаются, если это не так, и какой-то уже готовый сценарий интенсивно использует вызовы virtual(). Тогда мы должны будем либо переделать сценарий, либо написать эмуляцию для функции virtual() (благо в "сценарном"
варианте PHP эта функция отсутствует, так что можно без оглядки на ключевые слова создать процедуру с именем virtual()). Вот как мы здесь поступим:
if(!function_exists("virtual")) {
// Условно определяемая функция
function Virtual($url)
{ //* здесь должен идти код для преобразования относительного
//* URL (заданного относительно текущего каталога) в абсолютный.
//* Мы не будем сейчас останавливаться на этом вопросе — оставим
//* его для 5-й части книги.
global $HTTP_HOST,$SERVER_PORT;
$f=@fopen("http://$HTTP_HOST:$SERVER_PORT$url","r");
if(!$f) {
echo "[an error ocurred while processing this directive: $url]";
return false;
}
// Теперь просто читаем все и выводим с помощью echo
while(($s=fread($f,10000))!="") echo $s;
fclose($f);
}
}
Обращаю ваше внимание на то, что используется не обычный fopen(), а сетевая его разновидность, на что указывает префикс http:// в имени файла. Единственное здесь сложное место — преобразование относительного URL в абсолютный. Но эта задача, конечно, вполне разрешима, и мы займемся ей уже скоро — в пятой части книги — наряду с остальными проблемами прикладного характера.
 |
Этап первый: установка
1. Запустите только что полученный файл дистрибутива Apache. В появившемся диалоговом окне нажмите кнопку Next
(рис. 4.1), а затем — кнопку Yes, чтобы согласиться с условиями лицензии.
Рис. 4.1. Установка Apache
Рис. 4.2. Каталог для установки сервера
2. Нажимайте кнопку Next
в открывающихся окнах до тех пор, пока не появится запрос о выборе каталога для установки Apache (рис. 4.2). Рекомендую вам оставить тот каталог, который предлагается по умолчанию (пусть это, например, C:\Program Files\Apache Group\Apache). Запомните его на будущее.
3. В появившемся окне установите флажок Typical (Обычная) и нажмите кнопку Next (рис. 4.3).
4. Программа инсталляции Apache предложит создать папку в меню Пуск в папке Программы. Позвольте ей это сделать, нажав кнопку Next. Начнется процесс копирования программного обеспечения.
5. После окончания копирования нажмите кнопку Finish. Процесс установки сервера завершен, впереди — его настройка.
Рис. 4.3. Тип установки