Аспектно-Ориентированная Разработка ПО на PHP
В настоящий момент имеется ряд инициативных проектов, авторы которых представили различные способы реализации АОП и PHP. В проекте aoPHP представлен препроцессор PHP, написанный на Java 1.5. Мы можем писать привычный PHP-код, но должны будем сообщать препроцессору о нашем желании приобщения к АОП. Для этого вместо конструкции <?PHP .. ?> мы будем использовать <?AOPHP ?>. Сквозную функциональность мы сможем разместить в отдельных скриптах.
before(): execr(add($x,$y)) | execr(sub($x,$y)){ echo "<font color=red>Im About To Add/Sub $x & $y</font><br>"; }
Эти скрипты при необходимости могут быть задействованы путем указания при декларации кода AOPHP
<?aophp filename="aotest.aophp,aotest2.aophp" debug="off" // PHP code ?>
В проекте Seasar.PHP применен иной путь. Здесь для структурирования деклараций аспектов используется XML, а компоновку производит сам PHP, после чего выполняет результирующий код посредством функции eval().
В проекте MFAOP используется принцип, немного похожий на тот, что я демонстрировал выше в примерах. Автор проекта рекомендует первоначально назначить некоторый Poincut и в дальнейшем уже его применять в различных аспектах.
$pointCut = new PointCut(); $pointCut->addJoinPoint('Example', 'Foo'); $pointCut->addJoinPoint('Example', 'Bar'); $test1 = new Aspect($pointCut, before, 'echo "Before $MethodName";'); $test2 = new Aspect($pointCut, after, 'echo "After $MethodName";');
В отличие от библиотеки aop.lib.php в данном решении у вас нет необходимости расставлять "оповещатели" "вручную" для каждой функции. Но придется инсталлировать на сервере дополнительное расширение PHP PECL Classkit.
На мой взгляд, наиболее элегантное решение получилось у авторов проекта PHPAspect. Это стало возможным благодаря эффективному использованию новых возможностей PHP5, в частности, возможности создания абстрактных классов. PHPAspect вводит специальную конструкцию в язык PHP, которая наглядно представляет декларируемый аспект.
aspect TraceOrder{ pointcut logAddItem:exec(public Order::addItem(2)); pointcut logTotalAmount:call(Order->addItem(2)); after logAddItem{ printf("%d %s added to the cartn", $quantity, $reference); } after logTotalAmount{ printf(" Total amount of the cart : %.2f €n", $thisJoinPoint->getObject()->getAmount()); } }
Как видно, в примере область заданного аспекта четко определена. Задание Pointcut и Advice столь лаконично, но емко, что складывается впечатление, будто это "родной" синтаксис PHP. Данный проект предлагает обслуживание событий Join point семи (!) типов: вызов метода (call), выполнение метода (exec), инициализация класса (new), запись в атрибут (set), чтение атрибута (get), деструкция класса (unset) и захват блока (catch). Возможно задание Advice трех типов: before, after, around. Проект позволяет использовать неожиданно гибкие маски для задания областей наблюдения в Pointcut. Так, к примеру, есть возможность задания области для всех классов с заданным префиксом в имени.
new(*(*)); exec(* Order::addItem(2)); call(DataObject+->update(0));
Для установки PHPAspect вам потребуется PHP версии не ниже 5.0.0 и установленные библиотеки PEAR Console_Getopt, Console_ProgressBar, PHP_Beautifier.
Данный проект был с успехом представлен в прошлом году на PHP конференции во Франции (на родине авторов) и, судя по всему, активно развивается и ныне. Вполне возможно, что Zend Inc. обратит на него внимание и учтет этот опыт в следующих версиях PHP.
Аспектно-ориентированная веб-разработка и PHP
Дмитрий Шейко,
Данная статья знакомит читателя с популярной парадигмой аспектно-ориентированной разработки программного обеспечения (AOSD). Статья содержит множество практических примеров, призванных конкретизировать столь абстрактную область как AOSD и помочь быстрее понять и оценить преимущества данного подхода. Статья рассчитана в первую очередь на программистов PHP. Цель ее в том, что бы показать, как можно использовать AOSD в PHP проектах уже сегодня
Уже много лет объектно-ориентированный подход к программированию пользуется широкой популярностью. В небольших краткосрочных проектах едва ли будут заметны его преимущества, но без него любой крупный проект фактически обречен. Именно объектно-ориентированные языки программирования содержат все необходимое для того, чтобы представить бизнес-логику проекта в наглядном виде. Даже при проектировании самой логики системы ныне напрашивается диаграмма классов UML. Наглядная бизнес-логика позволяет легко включаться в проект новым участникам, сберегает время авторам кода, вернувшимся в проект после длительного перерыва. Наглядная бизнес-логика ощутимо сокращает число ошибок в проекте. Но достаточно ли использования объектно-ориентированного подхода к программированию для того, чтобы достичь столь желанной наглядной бизнес-логики? Очевидно - нет. Добиться изящной объектно-ориентированной программной архитектуры достаточно сложно. Но если вы использовали приемы из книги Мартина Фаулера "Рефакторинг. Улучшение существующего кода", возможно, вам это удалось.
Однако даже теперь мы можем найти в коде сквозную функциональность (crosscutting concerns), участвующую в самых различных классах (протоколирование, кеширование, синхронизация, трассировка, контроль безопасности, контроль транзакций). Организовать подобную программную логику поможет AOSD (Аспектно-ориентированная разработка программного обеспечения).
Что такое AOSD?
Аспектно-ориентированная разработка программного обеспечения (AOSD) - это относительно новая парадигма разработки бизнес-приложений. Основа данного подхода - Аспект. Это точка зрения, с которой может быть рассмотрено какое-либо понятие, процесс, перспектива. Чтобы быстрее вникнуть в суть подхода, давайте рассмотрим веб-сайт в различных аспектах. Информационная архитектура описывает сайт в аспекте организации его структуры. Usability описывает сайт в аспекте удобства его использования. Графический дизайн представляет сайт в аспекте его визуального восприятия. Функциональная модель описывает сайт в аспекте его бизнес-логики. Все это различные составляющие процесса разработки веб-сайта, каждая из которых требует специфичных ресурсов, подходов и реализаций. Успешный проект подразумевает качественное решение со стороны каждого их этих аспектов. Если кому-либо данный пример покажется сложным, можно обратиться к более простой и универсальной схеме. Когда проектируется жилой дом, архитекторы проектируют каркасный чертеж, далее подготавливается схема электропроводки, схема водоснабжения и прочее. Очевидно, что каждый этап является самостоятельным, но необходимым для успеха всего проекта. Каждый этап - это аспект, в котором можно рассматривать проект. Как это ни банально, но в разработке программного обеспечения может быть использован тот же принцип выделения аспектов бизнес логики приложений. Более 20 лет назад Бьерн Страуструп воплотил в C++ компоновку программного кода в наборы логических объектов, поведение которых и соотношение друг с другом может быть определено различным образом (наследование, инкапсуляция, абстракция, полиморфизм). Это надежная, проверенная временем парадигма разработки программного обеспечения - объектно-ориентированное программирование. Однако этот подход имеет свои ограничения в декомпозиции аспектов бизнес-логики приложения. За прошедшее время было разработано множество новых подходов для преодоления данных ограничений. Среди них можно назвать адаптивное программирование, композиционные фильтры, гиперпространства, аспектно-ориентированное программирование, моделирование ролей, предметно-ориентированное программирование и т.д. Последнее время подобные изыскания стали подаваться под эгидой аспект-ориентированной разработкой программного обеспечения. Как уже говорилось выше, код сквозной функциональности так или иначе будет распределен по различным модулям, что наихудшим образом скажется на качестве программного обеспечения с точки зрения наглядности бизнес-логики, ее адаптации и способности к развитию. Задача AOSD в том, чтобы выделить сквозную функциональность и вынести ее за пределы бизнес-логики приложений.
Давайте представим какое-нибудь комплексное веб-приложение, например, CMS, и рассмотрим, на каком этапе и каким образом мы можем столкнуться с указанными проблемами. Допустим, что для некоторого числа функций системы требуется преобразование входных данных из XML в массивы. В данном случае аспект XML-парсинга затрагивает лишь небольшое число функций и не предполагает существенного развития. Как мы видим, здесь не требуется расширенная декомпозиция, нет очевидной необходимости в использовании AOSD. Логичнее всего определить эту процедуру в метод корневого класса (или же внешнего класса, смотря по обстоятельствам) и вызывать его по мере необходимости.
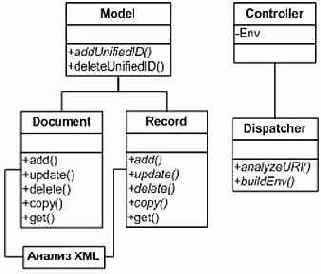
Рисунок 1.Приемлемая декомпозиция.
Однако если же речь идет о мониторинге производительности, и наша задача - по требованию снять показания со всех выполняемых функций на их входах и выходах, то едва ли помогут какие-либо манипуляции с объектами. Впрочем, дотошный читатель предложит воспользоваться предыдущим примером в масштабе всего приложения и в дальнейшем использовать триггер для включения и выключения сбора статистических данных. Остается его предупредить, что когда вдруг возникнет необходимость задействовать протоколирование системных транзакций для заданных случаев, при данном подходе придется вспоминать все детали программной архитектуры и реорганизовывать ее.
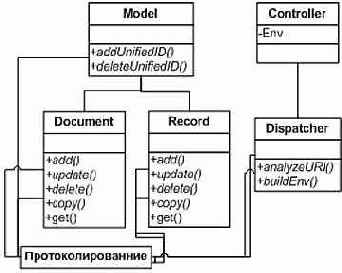
Рисунок 2. Неприемлемая декомпозиция.
Насколько было бы удобнее попросить систему в рамках некоторого аспекта должным образом обслужить заданные события в определенных объектах. Скажем, проходит время, и для нашего большого и сложного проекта приходят новые требования по безопасности. Мы пишем процедуру дополнительных проверок безопасности и требуем от системы в рамках аспекта безопасности при вызове заданных методов выполнять данную процедуру. Парадигма аспектно-ориентированной разработки программного обеспечения подразумевает это. Мы выделяем новый уровень абстракции вне существующей программной архитектуры и декларируем в нем функциональность, в том или ином отношении применимую к системе в целом. Как видно из , мы можем выделить программные процедуры, обслуживающие систему, например, в рамках аспекта безопасности и вынести их из основных классов. Далее мы можем проделать то же в отношении процедур аспекта контроля входных данных. Таким образом, при каждом проходе мы освобождаем бизнес-логику системы, делаем ее более наглядной. Фактически мы получаем в результате наглядную бизнес-логику в основных классах системы и аккуратно расфасованную сквозную функциональность вне базовой модели.
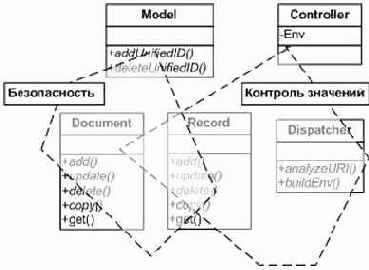
Рисунок 3. Аспектная декомпозиция.
Итак, резюмируем:
Основа аспектно-ориентированного подхода состоит в идентификации общности программного кода в рамках каких-либо аспектов и вынесении выделенных процедур за пределы основной бизнес-логики. Процесс аспектной ориентации и разработки программного обеспечения может включать моделирование, дизайн, программирование, обратный инжениринг, реинжениринг. Зона покрытия аспектно-ориентированной разработки ПО включает приложения, компоненты, базы данных. Взаимодействие и интеграция с прочими парадигмами осуществляется посредством фреймворков, генераторов, языков программирования и языков описания архитектуры (ADL).
Основы аспектно-ориентированного подхода
Аспектно-ориентированное программирование (АПО) позволяет выделить сквозную функциональность в отдельные декларации - аспекты. Можно определить функциональность для строго заданных точек выполнения программы JoinPoints (вызов метода, инициация класса, доступ к полю класса и т.д.). В языках, поддерживающих АОП, чаще используются назначения для множества точек - Pointcut. Функциональность в точках определяет программный код, который принято вежливо называть Advice (AspectJ). Таким образом, в пространстве аспектов описывается сквозная функциональность для определенного множества компонентов системы. В самих компонентах представлена лишь бизнес-логика, которую они призваны реализовать. В ходе компиляции программы компоненты связываются с аспектами (Weave).
Чтобы лучше понять базисы АОП, давайте вернемся к примеру с выделением аспекта мониторинга производительности (см. ). Нам требуется снять показания таймера на входе и на выходе всех методов классов Model, Document, Record, Dispatcher. Итак, мы имеем аспект Logging. Нам потребуется завести к нему Pointcut с перечислением всех требуемых функций. В большинстве языков программирования, поддерживающих АОП, для охвата сразу всех методов класса можно использовать специальную маску. Теперь можно описать для этого Pointcut. Создаем Advice на входе в методы из списка Pointcut (Before) и на выходе из них (After). Advice для событий Before, After, Around - наиболее популярны в языках, поддерживающих АОП, но порой доступны и другие события.
Итак, по результатам данного примера можно отметить для себя по поводу базисных деклараций АОП следующее:
Aspect - определение некоторого набора сквозной функциональности, нацеленной на конкретную задачу;
Poincut - код применимости аспекта. Отвечает на вопросы, где и когда может быть применена функциональность данного аспекта (см. )
Advice - код функциональности объекта. Непосредственно код функциональности для заданных событий. Другими словами, это то, что будет выполнено для объектов, указанных в Pointcut.
Все еще сложно вникнуть в этот подход? Полагаю, все встанет на свои места, когда мы привнесем немного предметности. Давайте начнем с самого простого примера. Я некогда написал эту маленькую библиотеку специально, чтобы проиллюстрировать как преимущества подхода АОП, так и его доступность. Кроме того, для того, чтобы воспользоваться данной библиотекой вам не потребуются глубокие знания PHP и специального программного обеспечения. Вам будет достаточно включить библиотеку aop.lib.php в ваши скрипты под управлением PHP 4 (или выше) в его стандартной комплектации. Мы можем определить некоторый аспект для сквозной функциональности (скажем, ведение журналов транзакций) посредством инициирования класса Aspect.
$aspect1 = new Aspect();
Далее мы можем создать Pointcut и сообщить, какие методы он затрагивает.
$pc1 = $aspect1->pointcut("call Sample::Sample or call Sample::Sample2");
Осталось лишь сообщить программный код для входной и выходной точек методов текущего среза.
$pc1->_before("print 'Aspect1 preprocessor<br />';"); $pc1->_after("print 'Aspect1 postprocessor<br />';");
Аналогичным образом мы можем описать дополнительный аспект, например:
$aspect2 = new Aspect(); $pc2 = $aspect2->pointcut("call Sample::Sample2"); $pc2->_before("print 'Aspect2 preprocessor<br />';"); $pc2->_after("print 'Aspect2 postprocessor<br />';");
Для того, чтобы задействовать один или несколько аспектов, достаточно воспользоваться функцией Aspect::apply()
Aspect::apply($aspect1); Aspect::apply($aspect2);
Как вам, возможно, известно, в PHP до 5-й версии достаточно проблематично обслуживать события методов и классов. Если для событий глобального характера, таких как ошибки PHP, можно написать собственный обработчик, то для обработки, скажем, событий на входе и выходе методов придется "вручную" расставить "оповещатели". В нашем случае потребуется расставлять специальные функции
Advice::_before(); и Advice::_after(); class Sample { function Sample() { Advice::_before(); print 'Class initilization<br />'; Advice::_after(); return $this; } function Sample2() { Advice::_before(); print 'Business logic of Sample2<br />'; Advice::_after(); return true; } }
Как видно из примера, до кода бизнес-логики метода и после него установлены "оповещатели" этих событий. Когда процессор PHP минует такой "оповещатель", он проверяет, нет ли активных аспектов. В случае наличия такового, PHP проверяет, указана ли текущая функция в диапазоне Pointcut. Если и это условие верно, вызывается назначенная нами функция для данного события (например для Advice::_before()). Видите - как я и обещал, все достаточно просто. Но дает ли этот подход реальную пользу?
Давайте представим, что мы расставили во всех методах классов наших скриптов "оповещатели" и подключили библиотеку aop.lib.php. И вот однажды нам потребовалось получить подробный отчет о распределении нагрузки по выполняемым функциям нашего проекта. Мы создаем аспект и назначаем ему Pointcut, охватывающий все функции проекта.
$Monitoring = new Aspect(); $pc3 = $Monitoring->pointcut("call *::*");
Как показано в примере, мы можем воспользоваться маской *::*. Далее в Advice мы можем воспользоваться традиционной функцией вычисления точного времени в миллисекундах
function getMicrotime() { list($usec, $sec) = explode(" ",microtime()); return ((float)$usec + (float)$sec); }
С помощью этой функции мы можем замерять время на входе в каждую функцию проекта и сверять его с показаниями на выходе из этой функции, а время выполнения операций бизнес-логики в теле функции помещать в глобальную переменную отчета. Осталось лишь вывести на экран отчет в конце программы. Пример использования аспекта мониторинга производительности представлен в скрипте sample_trace.php в архиве дистрибутивного пакета.
Чтобы у вас не сложилось мнение, что АОП помогает решать лишь какие-то частные задачи, давайте рассмотрим еще пример.
Как известно, PHP лояльно относится к типам переменных. С одной стороны, это не может не радовать нас, так нет необходимости постоянно заботиться о соответствие заданным типам и тратить время на их декларацию. С другой стороны - это причина множества возможных ошибок. При большом количестве функций в проекте едва ли возможно удержать в памяти заведенный нами же синтаксис для них. Но достаточно лишь поменять местами аргументы функции, и ее поведение может стать непредсказуемым. Может ли здесь нам помочь АОП? А почему бы и нет?! Давайте вспомним диаграмму, приведенную на . Как мы видим, классы Document и Record содержат однотипные методы add, update, delete, copy, get. Хорошо организованная программная архитектура подразумевает однотипный синтаксис для этих методов: add($id, $data), update($id, $data), delete($id), copy($id1,$id2), get($id). АОП нам может помочь организовать как программную архитектуру, так и самих себя. Мы можем завести аспект валидации входных параметров и определить диапазон Pointcut для методов классов Document и Record. Функция события входа для методов add, update, delete, copy, get может проверять тип первого аргумента. Если он не является целочисленным (integer), то можно смело сообщать об ошибке. Можно также завести второй Pointcut для методов add и update. В данном случае будет проверяться тип второго аргумента. Он, очевидно, должен соответствовать типу массив (array).
Таким же образом мы можем выносить за пределы бизнес-логики проекта протоколирование транзакций, мы можем в любой момент определить диапазон функций, требующих дополнительных проверок на предмет безопасности, и т.д.
Что особенно интересно, посредством АОП мы можем назначить специфичный вывод сообщения о системной ошибке для определенного набора функций. Допустим, ряд наших функций участвует в формировании кода разметки WML (WAP), WSDL (SOAP), RSS/ATOM или SVG. Разумеется, в данном случае недопустимо выводить на экран HTML-разметку с сообщением об ошибке. "Оповещатель" в обработчике ошибок PHP заставит систему отобразить сообщение либо в требуемой разметке XML, либо оповестить нас без отображения сообщения на экране (например, по Email).
Каждый, кому приходилось участвовать в разработке тиражируемых программных продуктов, знает, насколько непросто решить проблему обновления версий продукта. Конечно, все мы знаем о наличие специального программного обеспечения для контроля версий, например, о CVS (Concurrent Versions System). Однако проблема состоит в том, что для каждого нового продукта на базе нашего тиражируемого продукта требуется некоторая кастомизации, и часто достаточно сложно выяснить, не затронет ли обновление области, адаптированные под конкретный проект. Наверняка кто-нибудь из вас встречался с проблемой, когда после очередного обновления версии базового продукта приходилось восстанавливать весь проект из резервных копий. А представьте себе ситуацию, когда "пропажа" кастомизации в отдельных интерфейсах проекта выясняется спустя продолжительное время после обновления версии базового продукта! Вы скажите "А причем здесь АОП?!". Дело в том, что АОП как раз может помочь в решении данной проблемы. Мы ведь можем перенести весь код кастомизации проекта как сквозную функциональность за пределы основной бизнес-логики. Достаточно определить аспект наших интересов, указать область его применимости (Pointcut) и разработать соответствующий код функциональности. Имеет смысл взглянуть на то, как это может работать.
Вернемся к моему излюбленному примеру с ПО для управления содержанием сайта. Подобный продукт наверняка будет содержать функцию для отображения списков записей (recordsets) Record::getList() и подготовки кода для отображения данного списка View::applyList(). Record::getList() получает в качестве аргументов идентификатор recordset и параметры выборки в нем. Возвращает эта функция массив с данными по результатам выборки. Функция View::applyList() принимает на входе этот массив и формирует код оформления для него, например HTML-код таблицы. Допустим, в нашем продукте каталог товаров представлен в виде подобных списков записей. Это универсальное решение для тиражируемого продукта, но для конкретного проекта, базированного на нем, требуется отображать дополнительную колонку в списках. Например, в базовом продукте принято отображать таблицу с полями "артикул", "наименование товара". А требуется к ним добавить поле "Рейтинг покупателей". Для этого мы всего лишь пишем Advice для функции Record::getList(), по которому на ее выходе в возвращаемый массив будет введена дополнительная колонка. Если наша функция View::applyList() не способна автоматически адаптироваться под изменения во входящем массиве, то придется написать Advice и для нее. Допустим, спустя время заказчик потребовал от нас выделить все строки в списках, обозначающие товары, которые отсутствуют на складе. Мы дописываем Advice для View::applyList(), где сверяем значение атрибута записей "Наличие на складе" и соответствующим образом оформляем их. Обратите внимание, что мы можем завести отдельную папку Plugins для деклараций аспектов и скриптов их функциональности. Таким образом, вся кастомизация для любого из проектов будет сосредоточена в одно заданной папке. В дальнейшем у нас уже не будет проблем с обновлением версий. Мы сможем смело обновлять любые системные скрипты, за исключением тех, что представлены в папке Plugins.
AOSD вовсе не панацея. АОП
Безусловно, AOSD вовсе не панацея. АОП не избавит нас от ошибок в программном обеспечении, да и программы не станут писаться сами собой. Едва ли каждый программист получит по нобелевской премии, только за то, что использует АОП. Более того, нельзя сказать, что этот подход в программировании будет доминирующим в будущем. Вспомните, за два десятка лет объектно-ориентированное программирование обрело популярность, но по-прежнему большое число программистов ограничиваются процедурным кодом. С другой стороны, преимущества АОП перед ООП очевидны, так же как и преимущества ООП перед процедурным программированием. Можно сказать, что программисты, использующие АОП, находятся на шаг впереди. Их код лучше в плане удобочитаемости, соответственно, в нем меньше ошибок, он лучше подходит для развития. Таким образом, инженеры AOSD способны реализовать более масштабные, более надежные, более универсальные проекты, нежели программисты не использующие АОП. И заметьте, АОП не требует кардинальной переквалификации программистов. АОП не меняет логику программирования до неузнаваемости, как это было при переходе от процедурного программирования к ООП. Можно сказать, что АОП лишь расширяет ее. Проектируя новую программную архитектуру, вы лишь выносите из объектов все то, что "мозолит вам глаза", и определяете все это в подходящее место. Представьте, что вы упорно терпите в своем доме статуэтку, которая абсолютно не вписывается в дизайн интерьера, но дорога вам как память. Но однажды вы делаете скрытую от праздного взгляда нишу в стене, где все неугодные предметы находят свое истинное место. После чего остается лишь только восклицать: "Ну, правильно! Именно здесь оно и должно быть!".
АОП также не требует длительного периода привыкания, как, например, TDD. Поначалу можно выносить в аспекты простую сквозную функциональность, такую как протоколирование. А со временем можно все более и более расширять декомпозицию программной архитектуры, собирая в областях аспектов различные сферы применимости приложения.
Возможно, кого-то смущает тот факт, что официально в PHP не поддерживается АОП в настоящее время. Однако как раз в этой статье я показал вам на примерах, что без особого труда вы сами можете обеспечить поддержку основных принципов АОП. Не так важна реализация идеи AOSD, как ее суть. Какой бы вы образ ни выбрали, но если вам удалась более качественная декомпозиция в программной архитектуре, это в любом случае улучшит качество ваших программ. Сегодня АОП действительно поддерживается по большей части в расширениях к популярным языкам программирования, а не в самих языках. Однако ведущие игроки на рынке не остаются в стороне, и АОП постепенно пробивает себе дорогу в популярные программные платформы (http://www.internetnews.com/dev-news/print.php/3106021). Не стоит ожидать технологической революции под знаменами AOSD. Но эволюция неизбежна. Догонять ее или следовать во главе ее - выбор за нами.
If-Modified-Since, если PHP не установлен как модуль Apache
Николай И. Яровой,
22.04.2006
Наверное, каждый веб-программист, интересующийся кешированием веб-страниц на стороне клиента, знает о таких заголовках HTTP, как «If-Modified-Since» и «If-None-Match». Данные заголовки отправляются браузером при обращении к странице, которая имеется в его кеше. Для правильной организации кеширования на стороне клиента, серверному приложению необходимо отправлять заголовок "HTTP/1.0 304 Not Modified"и прекращать передачу данных в случае, если содержимое запрашиваемой страницы не изменилось с того момента времени, которое указано в присланном заголовке "If-Modified-Since".
Основная проблема при реализации кеширования на стороне клиента заключается в том, чтобы получить содержимое заголовка "If-Modified-Since". Вызвана она тем, что по умолчанию указанный заголовок доступен из серверного приложения только в том случае, если интерпретатор PHP установлен в качестве модуля Apache, что бывает крайне редко на серверах организаций, предлагающих услуги хостинга (по соображениям безопасности и удобства перекомпиляции PHP). Следует заметить, что кеширование на стороне клиента благотворно влияет не только на нагрузку веб-сервера, но и на скорость индексации веб-сайта поисковыми машинами. В связи с этим, опытные SEO-специалисты упорно ищут и рекомендуют "правильные" хостинговые компании.
На самом деле, существует универсальное решение данной проблемы, не требующее вмешательства в глобальную конфигурацию веб-сервера и работающее даже в том случае, когда PHP не установлен в качестве модуля Apache. Для применения данного метода необходимо и достаточно, чтобы выполнялись следующие условия:
возможность конфигурации через файлы .htaccess; доступность и возможность использования модуля mod_rewrite; в серверном приложении к заголовкам "If-Modified-Since" и "If-None-Match" необходимо обращаться через массив $_SERVER, а не при помощи функций getallheaders или apache_request_headers (эти функции доступны только в том случае, если PHP установлен в качестве модуля Apache).
Итак, для реализации доступа к заголовкам "If-Modified-Since" и "If-None-Match" необходимо в корневом каталоге веб-сайта поместить файл .htaccess следующего содержания:
RewriteEngine On
RewriteRule .* - [E=HTTP_IF_MODIFIED_SINCE:%{HTTP:If-Modified-Since}]
RewriteRule .* - [E=HTTP_IF_NONE_MATCH:%{HTTP:If-None-Match}]
После этого, необходимые заголовки будут доступны как $_SERVER['HTTP_IF_MODIFIED_SINCE'] и $_SERVER['HTTP_IF_NONE_MATCH']. В случае если на веб-сайте mod_rewrite используется для формирования URL, содержимое .htaccess примет вид:
# url rewriting
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)$ index.php [QSA]
# If-Modified-Since (if php is not installed as cgi then comment lines below)
RewriteRule .* - [E=HTTP_IF_MODIFIED_SINCE:%{HTTP:If-Modified-Since}]
RewriteRule .* - [E=HTTP_IF_NONE_MATCH:%{HTTP:If-None-Match}]
Следует заметить, что заголовки и не отправляются браузером, если в предыдущих запросах к данной странице он не получал в ответе веб-сервера заголовок Last-Modified>. Кроме того, при использовании в веб-приложении сессий с установками по умолчанию, указанные заголовки также не будут присылаться браузером. Для того чтобы избежать такого поведения браузера, необходимо перед запуском сессии выполнять функцию session_cache_limiter, передавая в качестве аргумента параметр 'private_no_expire':
<?php
session_cache_limiter('private_no_expire');
session_start();
?>
Битва со списками или применение классов для вывода списков в PHP
, ASIADATA.RU
Список, список, список… Открываешь файл любого интернет-проекта, основанного на технологии PHP+MySQL, и первое, что видишь - это куски кода, примерно такого вида: $q = 'SELECT id, title FROM rubrics'; $result = mysql_query ($q) or die ('Select query failed'); print '<ol>'; while ($line = mysql_fetch_array ($result, MYSQL_ASSOC)) {
print '<li><a href="?id=' . $line['id'] . '">'; print $line['title']; print '</a></li>';
} print '</ol>';
Подобным образом выводится список ссылок на отдельные страницы раздела сайта, хранящиеся в базе данных, фирмы в каталоге, подписчики рассылки в интерфейсе администрирования, статистика ресурса и многое другое.
Каждый раз, набирая подобный код в PHP-редакторе, видишь, что снова и снова проделываешь одну и ту же работу с минимальными вариациями. Различия только в коде SQL-запроса, типе и количестве выводимых полей и в HTML-тэгах, т.е. в дизайне. А если делаешь одну работу два раза, то это повод не только заскучать, но и задуматься о том, как ее себе облегчить. Да и попытки немного изменить дизайн сайта часто требуют модификации именно этого участка кода, а значит и его последующей отладки.
На протяжении нескольких лет работы с PHP у меня выработался определенный стандарт написания кода для вывода списков, и в результате захотелось обобщить этот опыт и сделать нечто стандартное, подходящее для любой ситуации, связанной с выводом результатов SQL-запроса в виде списка средствами PHP.
В результате все простые списки были препарированы на шесть частей (это самая простая их модель):
Обрамление списка: это то, внутри чего список находится, есть в нем хотя бы один элемент или нет.
Пустой список: если наш запрос не возвращает ни одной строки, то все-таки стоит вывести на сайт некоторое пояснение, например, „список пуст”, или „редактор в отпуске, новостей больше не будет”, или оставить здесь пустое значение.
Начало списка: если в списке есть хотя бы один элемент, то список можно начать какой-нибудь фразой, например, „начало списка”, или разместить здесь заголовок, который в случае пустого списка может и не выводиться.
Конец списка: нужен для тех же целей, что и предыдущий пункт – фраза „конец списка” или какие-либо итоговые данные по всем строкам, которые в случае пустого списка могут и отсутствовать.
Элемент списка: собственно это и есть вывод данных каждой строки запроса; в отличие от предыдущих пунктов этот элемент применяется к каждой строке запроса, выводя её в одном и том же дизайне внутри обрамления списка.
Разделитель элементов списка: иногда элементы списка отделяются чем-нибудь друг от друга – запятыми, вертикальными черточками, тире и прочим, причем в начале и конце списка эти разделители могут отсутствовать.
Вышеуказанную структуру я называю шаблоном списка. Остается написать код некоего класса, который, имея на входе SQL-запрос, порождает объект, содержащий результат выполнения этого запроса. В классе также требуется метод, который на основании разработанного выше шаблона выдаст нам требуемый HTML-код.
Можно, конечно, обойтись и функцией, которая выдаст требуемое, получив в качестве параметров SQL-запрос и код шаблона. Но на мой взгляд с классами и ООП в программировании работать куда вкуснее. Вдобавок я не собираюсь останавливаться на такой простой модели списка, а дальнейшие разработки кода с классами поддерживаются куда проще. А когда наши провайдеры сменят движки PHP с четвертой версии на пятую, классы войдут в PHP в том же объеме, что и в C++.
Недолго думая, класс был назван ListItems; незнакомых с английским отсылаю на multitran.ru. Пишем его код:
class ListItems {
var $query; var $template; var $count = 0; var $items = array(); var $listitems = '';
function ListItems ($query='') {
$this->query = $query; if (!empty ($this->query)) {
$result = mysql_query ($this->query) or die('SQL query is failed'); while ($tmp = mysql_fetch_object ($result)) $this->items[] = $tmp; $this->count = count ($this->items); } } }
Конструктор класса принимает в качестве параметра код SQL-запроса. К моменту создания экземпляра класса у вас уже должна быть вызвана функция mysql_connect. После этого в свойстве items объекта мы получим результат выполнения запроса в виде нумерованного массива, каждый элемент которого является стандартным PHP-объектом, имена полей которого соответствуют именам полей запроса, а значения, естественно, соответствуют выбранным из базы данных значениям полей.
Теперь немного о шаблоне списка. Списки я препарировал, но ничего не сказал об их программной реализации. Для начала назовем каждый пункт каким-нибудь малопонятным именем на английском языке.
list – обрамление списка
empty – пустой список
begin – начало списка
end – конец списка
item – элемент списка
delimiter – разделитель элементов списка
Потом создадим массив, в котором каждый элемент шаблона индексируется принятым именем. Для написания кода элементов шаблона я пользуюсь одной достаточно распространенной идеей, вымученной PHP-программистами (да и не только ими) за многолетние попытки отделить дизайн от кода (эта статья также относится к ним). В настоящее время сложился определенный стандарт написания шаблонов для PHP-программ, использующий так называемые макрокоды, или макросы.
Чаще всего применяется конструкция, использующая угловые скобки с каким-либо текстовым или цифровым значением внутри для указания того места в шаблоне, куда надо вставлять нужную информацию. Для той же цели применяются теги комментариев HTML <!-- --> с текстом или числом, которые идентифицируются PHP-движком и заменяются требуемой информацией.
На мой взгляд, главный недостаток такой технологии заключается в том, что если PHP по какой-либо причине не обработал этот элемент кода, то в браузере вы не увидите ничего, что указало бы на эту ошибку, поскольку комментарии HTML невидимы по определению, а конструкции с угловыми скобками выглядят для браузера как неизвестные ему HTML-тэги, которые также не отображаются. А если совершенная ошибка невидима, то она будет повторяться и никогда не отладится. К тому же шаблоны бывают достаточно сложны и объемны по содержанию и разрабатывать их приходится в каком-либо WISIWIG-редакторе. Попробуйте редактировать невидимые тэги и комментарии в нем, и сразу убедитесь, насколько это неудобно. Применение квадратных скобок в виде [name] не очень удачно, так как даже в обычных текстах они достаточно распространены.
В общем, для вставки в шаблоны варьируемой информации была придумана следующая конструкция: {%%NAME%%}, где NAME – это идентификатор того значения, которым мы хотим заменить этот макрос. Такой макрос виден в выводе браузера, в любом WISIWIG-редакторе, более того, многие популярные HTML- и PHP-редакторы исходного кода можно настроить на подсветку этой конструкции цветом, отличным от остального кода, поскольку в стандарте HTML и PHP такая последовательность символов не используется. К тому же этот макрос не требует для своего написания специальных символов HTML.
Идентификатор NAME должен подчиняться еще одному правилу. Как вы уже заметили, в коде класса ListItems, SQL-запрос преобразуется в массив объектов, у которых имена полей соответствуют именам полей запроса, а значения – значениям. Распространяя это дальше, примем, что идентификатор NAME должен соответствовать имени того поля, значение которого заменит макрос без учета регистра символов. То есть, если в вашей базе данных есть таблица, в которой в поле name содержатся названия стран мира, а в поле population – численность их населения, то для того чтобы вывести список стран в виде
НАЗВАНИЕ СТРАНЫ – НАСЕЛЕНИЕ
элемент item должен выглядеть так: {%%NAME%%} – {%%POPULATION%%} чел.
Чтобы указать, где в обрамлении списка выводится последовательность его элементов, а также их количество, в классе ListItems предусмотрены дополнительные поля и соответствующие им макросы.
listitems – в этом поле накапливается HTML-вывод по мере перебора элементов списка, а макрос {%%LISTITEMS%%} должен обязательно присутствовать в элементе list шаблона, поскольку он заменяется кодом всего списка.
count – это число элементов списка, а макрос {%%COUNT%%} заменяется значением этого поля.
С учетом вышесказанного, код, задающий шаблон, будет выглядеть так:
$template = array (
'list' => '{%%LISTITEMS%%}', 'empty' => '<p>"Это мир, где нет стран и людей.', 'begin' =>' <p>Население {%%COUNT%%} стран мира.<ul>', 'end' => '</ul>', 'item' => '<li>{%%NAME%%} - {%%POPULATION%%} чел.</li>', 'delimiter' => ' '
);
Теперь приведу код метода объекта ListItems, который вставляет любой объект $o в каждый элемент шаблона $t, закодированного по определённым выше правилам. function InsertObjectToTemplate ($o, $t) {
foreach ($o as $n=>$v) if (gettype ($v)!= 'object' && gettype ($v)!='array') {
$p = '\{%%' . strtoupper ($n) . '%%\}'; if (eregi ($p, $t)) $t = eregi_replace ($p, strval($v), $t);
} return $t;
}
Изменив регулярное выражение в третьей строке кода, вы можете изменить вид макроса в соответствии с принятым на вашем проекте. Например, $p = '\[' . strtoupper ($n) . '\]';
позволит использовать макрос вида [name], а $p = '\{[[:space:]]{0,}' . strtoupper ($n) . '[[:space:]]{0,}\}';
– такой же макрос с фигурными скобками и любым числом пробельных символов между name и скобками. Я использую в своих проектах макросы с возможностью добавления пробельных символов перед и просле name, и эта строка выглядит так: $p = '\{%%[[:space:]]{0,}' . strtoupper ($n) . '[[:space:]]{0,}%%\}';
И последняя функция класса ListItems выводит массив объектов items в шаблон из шести элементов в соответствии со всем вышесказанным. function getOutput ($arg) {
$list = empty ($arg['list']) ? '' : $arg['list']; $begin = empty ($arg['begin']) ? '' : $arg['begin']; $end = empty ($arg['end']) ? '' : $arg['end']; $item = empty ($arg['item']) ? '' : $arg['item']; $delimiter = empty ($arg['delimiter']) ? '' : $arg['delimiter']; $empty = empty ($arg['empty']) ? '' : $arg['empty']; foreach ($this->items as $id=>$one) {
$this->listitems .= $this->insertObjectToTemplate ($one, $item) . $delimiter;
} $this->listitems = $this->count == 0 ? $empty : $begin . substr ($this->listitems, 0, -strlen ($delimiter)) . $end; $res = $this->insertObjectToTemplate ($this, $list); unset ($this->listitems); return $this->insertObjectToTemplate ($this, $res);
}
Первые шесть строк кода нужны, чтобы предотвратить вывод сообщений об ошибках в случае несоответствия шаблона $arg введенным нами соглашениям. Далее по циклу перебираются все элементы массива items и вставляются в элемент item шаблона с добавлением разделителя delimiter. По окончании цикла, в случае, если количество элементов в items больше нуля, то listitems заменяется empty, если нет, то к нему добавляются begin и end с отбрасыванием последнего delimiter. Далее экземпляр нашего класса вставляется в list и еще раз в полученный результат но уже без поля listitems. Это необходимо для того, чтобы дать возможность разместить поле count в begin, end, item или delimiter, что иногда бывает необходимо.
В общем-то, уже почти все сказано. Но как полагается в любой статье по программированию, приведу один готовый к тестированию пример, чтобы мой читатель, который, как и всякий программист, достаточно ленив, мог оценить сей труд на своем сервере.
Скачайте файл и распакуйте его в один из каталогов вашего сервера. Код класса ListItems находится в файле cls_lstitems.inc, тестовый пример – в файле test.php, SQL-код для создания тестовой таблицы в вашей базе данных – в файле test.sql. Во второй-пятой строках файла test.php укажитете ваши данные для подключения к MySQL, создайте тестовую таблицу из файла test.sql и запускайте скрипт test.php. Результатом его работы будет список стран мира с их населением по последним данным из CIA World FactBook.
Раскомментируйте 20-ю строку скрипта. Теперь элемент item отличается от первоначального тэгами b и, соответственно, население страны выделяется жирным шрифтом. Раскомментируйте 22-ю и 23-ю строки, и список становится нумерованным. Если в 53-ей строке заменить параметр функции $template на $template1, то вы получите список в табличном виде. Шаблон $template2 позволяет вывести только названия всех стран мира через запятую с пробелом и завершающей точкой. Если 51-ую строку скрипта заменить на $list = new ListItems ('');
то можно посмотреть на то, как класс ListItems обрабатывает пустые SQL-запросы.
Конечно, код класса ListItems намного сложнее приведенного в начале статьи цикла. Но, вводя такой класс, мы сделали одну очень большую вещь. В этом примере программный код (класс) полностью отделен от дизайна (шаблон) и содержащейся в выводимом списке информации (SQL-запрос). Добавьте к этому возможность хранить любое количество шаблонов в базе данных за счет их однотипной структуры, выбирая их по имени или номеру (идентификатору) и редактируя через какой-нибудь интерфейс администрирования без необходимости правки программного кода. Теперь не надо запускать дизайнеров в программный код, достаточно лишь поправить шаблон. Нет необходимости править код и в случае добавления новых данных: если вы хотите добавить в ваш список площадь территории каждой страны, то нужно лишь добавить в таблицу MySQL новое поле square, а в поле item шаблона — макрос {%%SQUARE%%}. Все это очень сильно облегчает жизнь разработчику движка сайта и CMS (Content Management System).
В этой статье мною приведена самая простая модель шаблона списка. На данный момент код класса ListItems, применяемый мной, куда сложнее. На сайте http://asiadata.ru/, который я поддерживаю как вебмастер, этот класс выводит все списки, позволяя группировать их по любому количеству элементов, выделять один или несколько из них, сортировать по одному или нескольким полям, как в запросе, так и в самом массиве items, а также расставлять ссылки и многое другое. Если читателей статьи заинтересует написанное, пишите на , и я продолжу и разовью затронутую здесь тему.
Register_globals=On? Вы в опасности!
,
Здравствуйте, уважаемые веб-мастера, статья повествует о том, почему опасно оставлять опцию register_globals включенной. Вы, возможно, слышали, что использование её может привести к небезопасной работе вашей программы (скрипта). Но давайте разберемся, как эту опцию могут использовать в противоправных целях и как от этого защититься.
Что представляет собой register_globals?
Это опция в php.ini, которая указывает на необходимость регистрации переменных, полученных методом POST или GET в глобальный массив $GLOBALS.
Для ясности приведу пример при register_globals=On.
Есть файл "index.php" с содержимым:
<?
echo $asd.' - локальная переменная<br>';
echo $GLOBALS['asd'].' - ссылка в глобальном массиве $GLOBALS<br>';
echo $_GET['asd'].' - $_GET["asd"]';
?>
В адресной строке напишем: index.php?asd=123
Получим:
123 - локальная переменная
123 - ссылка в глобальном массиве $GLOBALS
123 - $_GET['asd']
Как мы видим, создались 2 переменные: одна локальная (+ ссылка в $GLOBALS), другая в массиве $_GET. Многие не используют массив $_GET вообще, они продолжают обрабатывать переменную $asd после получения ее извне.
Но давайте вдумаемся, зачем нам "загрязнять" массив $GLOBALS? Для этого у нас есть специальные массивы, хранящие данные, переданные методами GET (массив $_GET) и POST (массив $_POST).
Тот же самый пример, но при register_globals=Off:
- глобальная переменная
- ссылка в глобальном массиве $GLOBALS
123 - $_GET['asd']
Т.о. не была создана локальная переменная и для манипулирования с мы должны использовать массив $_GET.
Возможно, уже сейчас вы изменили свое мнение о register_globals.
Вероятно, вам придется, что-то переписать в своих программах, но оно того стоит.
А теперь я расскажу вам, как взломщик может воспользоваться этой опцией в своих целях, т.е. при register_globals=On.
Начну от простого к сложному.
Часто мы видим предупреждения:
Notice: Undefined variable: asd(название переменной) in ****
Что это значит? Это значит, что переменная $asd не была определена явно.
Например, некоторые люди балуются подобным:
<?
for($i= 0;$i<10;$i++)
{
@$asd.=$i;
}
echo $asd
?>
Т.е. не определив переменную, сразу начинают ее использовать. Приведенный код по идее не страшен, но задумайтесь, а вдруг эта самая переменная $asd, в последствии записывается в файл? Например, напишем следующее в строке адреса: "index.php?asd=LUSER+" и получим: "LUSER 0123456789". Ну разве приятно будет увидеть такое? Не думаю.
Предположим мы пишем систему аутентификации пользователя:
<?
if($_POST['login']=='login'&&$_POST['pass']=='pass')
{
$valid_user=TRUE; // Юзер корректный
}
if($valid_user)
{
echo 'Здравствуйте, пользователь';
}
else echo 'В доступе отказано'
?>
Привел я заведомо дырявую систему, стоит нам только написать в адресной строке "index.php?valid_user=1" и мы получим надпись "Здравствуйте, пользователь"
Этого бы не случилось, если бы мы написали так:
<?
if($_POST['login']=='login'&&$_POST['pass']=='pass')
{
$valid_user=TRUE; // Юзер корректный
}
else $valid_user=FALSE;
if($valid_user)
{
echo 'Здравствуйте, пользователь';
}
else echo 'В доступе отказано'
?>
Т.е. сами определили переменную $valid_user, как FALSE в случае неудачи.
Продолжим далее:
Теперь использование функции IsSet() становиться небезопасно, т.к. любой может подменить переменную на угодную ему.
Приведу пример с sql-инъекцией:
<?
if(@$some_conditions) // некоторые условия
{
$where='id=3';
}
echo $query='SELECT id, title, description FROM table '
.'WHERE '.(IsSet($where)?$where:'id=4')
?>
В адресной строке напишем:
"index.php?where=id=0 + UNION + ALL + SELECT + login, + password, + null + FROM + admin + where + login='admin'",
получим sql-инъекцию:
SELECT id, title, description FROM table WHERE id=0
UNION ALL SELECT login, password, null FROM admin where login='admin'
И взломщик получает ваши явки и пароли:(
Как вы видите, все примеры имеют дыры в защите, которые можно эксплуатировать через включенный register_globals.
Справиться с подобным можно, если всегда определять переменную вне зависимости от условий. Или же использовать инкапсуляцию переменных в функциях, т.е. когда вы определяете функцию, то переменные внутри нее будут закрыты извне, например:
<?
function asd()
{
// Какие то действия
if(IsSet($where))
{
echo $where;
}
else echo '$where не существует';
}
asd();
?>
Теперь, если мы напишем в адресной строке: "index.php?where=123"
Даст: "$where не существует"
Но это при условии, что вы не устанавливаете переменную $where как глобальную, т.е. "global $where"
Я могу придумать еще очень много примеров, но думаю, что приведенных мною вам будет достаточно для понимания.
Хочу сказать, что все эти проблемы канут в лета, когда вы установите опцию register_globals=Off и попробуете заново все приведенные выше примеры.
Это можно сделать как в php.ini, но большинство хостинг провайдеров вам это не позволят, потому придется воспользоваться файлом .htaccess
Создаем файл с названием: .htaccess
Запишем в него:
php_flag register_globals off
И все, теперь некоторые вопросы безопасности решены:)
Немного о причине написания мной этой статьи:
Лично я никогда не использовал register_globals = on, т.к. мне казалось это нелогичным. Также я знал, что это еще один "+" к защите. Но в полной мере я не осознавал, насколько это может быть опасно. Случилось это когда я решил написать GSMgen - Google SiteMap generator, который должен был работать безопасно и при включенном register_globals. Когда же я начал его тестировать, у меня был шок: так как мне нравится использовать функцию IsSet(), я нашел в ней непосредственную уязвимость, и в процессе мне пришлось от этого отказаться:( Что поделаешь...
Я очень надеюсь, что эта статья изменит ваше мнение относительно register_globals. Думаю, что со временем все хостинг провайдеры будут ставить register_globals = off по умолчанию. Но пока этого нет, вы знаете как с этим бороться;-)
Если у вас возникли вопросы, вы можете задать их на форуме или лично мне
Удачи вам!
Сбор статистики на PHP
,
Подглядываем за посетителями
Статистические сведения о посетителях сайта приносят не мало пользы. По статистике можно подогнать дизайн сайта в соответствии с разрешением большинства посетителей, подогнать дизайн к браузеру, на котором приходят большая часть посетителей да и просто интересно, кто заглядывает к вам на сайт, из под какой OC, а может это поисковый робот яндекса или гугла? Хотя некоторые системы слежения за посетителями бывают черезвычайно сложными, но с помощью довольно простой системы можно получить любопытные сведения о посетителях сайта. Я покажу как сделать с виду простой журнал посещений сайта с помощью PHP и cookies (MySQL не требуется). К тому же мой пример можно легко расширить.
Для того, что бы система работала, нужно скрипт статистики встроить в каждую страницу. Ну или в те страницы, статистику посещений которых вы хотите увидеть. Наш скрипт будет записывать следующие данные:
Браузер + OC (HTTP_USER_AGENT) IP адрес (REMOTE_ADDR) Хост (REMOTE_HOST) Страницу-рефферер (HTTP_REFERER) Время визита (date("d.m.Y H:i:s")) Запрашиваемый адрес (REQUEST_URI)
Даже эти данные, я думаю, будут весьма интересны веб-мастерам. Итак, начнем. Скрипт будет называться sniffer.php. Я приведу текст всего скрипта и дополню это обильными комментариями:
<?php //sniffer.php //защита от непосредственного запуска //скрипта кем то посторонним if (eregi("sniffer.php",$PHP_SELF)) { Header("Location: index.php"); die(); } extract($HTTP_GET_VARS); extract($HTTP_POST_VARS); extract($HTTP_COOKIE_VARS); extract($HTTP_SERVER_VARS);
//этот фрагмент кода был позаимствован //из системы PHP Nuke ;) //далее объявляю переменные $fileName="stat.txt"; //имя файла со статистикой $maxVisitors=30; //количество записей, отображаемых //при просмотре статистики $cookieName="visitorOfMySite"; //имя куки $cookieValue="1"; //значение куки $timeLimit=86400; //срок в секундах, который должен //пройти с момента последнего посещения сайта, что бы //информация о посетителе записалась повторно. Это //значение равно 1 дню, т.е. один и тот же посетитель //записывается в статистику раз в одни сутки. Если //эту переменную приравнять к нулю, то будут учитываться //все посещения одного и того же посетителя //далее следуют переменные, отвечающие за отображение //статистики $headerColor="#808080"; $headerFontColor="#FFFFFF"; $fontFace="Arial, Times New Roman, Verdana"; $fontSize="1"; $tableColor="#000000"; $rowColor="#CECECE"; $fontColor="#0000A0"; $textFontColor="#000000"; //все переменные подготовлены. //Функция записи данных о посетителе function saveUserData() { GLOBAL $fileName, $HTTP_USER_AGENT, $REMOTE_ADDR, $REMOTE_HOST, $HTTP_REFERER, $REQUES_URI; $curTime=date("d.m.Y @ H:i:s"); //текущее время и дата //подготавливаю данные для записи if (empty($HTTP_USER_AGENT)) {$HTTP_USER_AGENT = "Unkwnown";} if (empty($REMOTE_ADDR)) {$REMOTE_ADDR = "Not Resolved";} if (empty($REMOTE_HOST)) {$REMOTE_HOST = "Unknown";} if (empty($HTTP_REFERER)) {$HTTP_REFERER = "No Referer";} if (empty($REQUEST_URI)) {$REQUEST_URI = "Unknown";} $data_ = $HTTP_USER_AGENT."::".$REMOTE_ADDR."::".$REMOTE_HOST.":: ".$HTTP_REFERER."::".$REQUEST_URI."::".$curTime."\r\n"; //разделителем будут два ":" //далее пишу в файл if (is_writeable($fileName) ) : $fp = fopen($fileName, "a"); fputs ($fp, $data_); fclose ($fp); endif; } //функция записи готова. Теперь нужно написать //функцию вывода данных из файла статистики function showStat () { GLOBAL $headerColor, $headerFontColor, $fontFace, $fontSize, $tableColor, $fileName, $maxVisitors, $rowColor, $fontColor, $textFontColor; //вывожу таблицу $fbase=file($fileName); $fbase = array_reverse($fbase); $count = sizeOf($fbase); echo "<font face=\"$fontFace\" color=\"$textFontColor\" size=\"$fontSize\">"; echo "Всего посещений: $count<br><br>"; echo "<div align=\"center\"> <table cellpadding=\"2\" cellspacing=\"1\" width=\"95%\" border=\"0\" bgcolor=\"$tableColor\">"; echo "<tr bgcolor=\"$headerColor\"><td>< font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">Браузер </font> </td><td><font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">IP</font></td> <td><font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">Хост</font></td> <td><font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">Ссылка</font></td> <td><font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">Страница</font></td> <td><font face=\"$fontFace\" color=\"$headerFontColor\" size=\"$fontSize\">Время визита</font></td></tr>"; echo "</font><font face=\"$fontFace\" size=\"$fontSize\">"; //открываю файл и запускаю цикл $fbase=file($fileName); $fbase = array_reverse($fbase); for ($i=0; $i<$maxVisitors; $i++) : if ($i>= sizeof($fbase)) {break;} $s = $fbase[$i]; //разделяю $strr = explode("::", $s); if (empty($strr)) {break;} //вывожу данные echo "<tr><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[0]</font> </td><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[1]</font> </td><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[2]</font> </td><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[3]</font> </td><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[4]</font> </td><td bgcolor=\"$rowColor\">< font face=\"$fontFace\" color=\"$fontColor\" size=\"$fontSize\">$strr[5]</font></td> </tr>"; endfor; }
?>
Скрипт сбора и показа статистики готов. Теперь нужно вставить в те страницы, информацию о посетителях которой вы хотите просмотреть:
<?php include("sniffer.php"); if (! isset($$cookieName)) : //установить куки setcookie($cookieName, $cookieValue, time()+$timeLimit); saveUserData(); endif; ?>
Здрасьте! А мона вас посчитать? Можно? Ну спасибо! Я вас посчитал! ;)
Обратите внимание, что этот код нужно вставлять в самый верх страницы, до того, как данные будут передаваться в браузер. В противном случае установить куки не получится. Далее сделаем страницу, выводящюю статистику:
<html><body> <?php include("sniffer.php"); ?> Статистика<br> <?php showStat(); ?></body></html></i>
Здесь мы просто включили файл sniffer.php и вызвали из него функцию showStat() Вот с помощью такого небольшого скрипта, длинной всего ровно в 100 строк, можно с помощью PHP получить и в удобном виде просмотреть. Здесь ещё много чего предстоит сделать, например сделать статистику по реферерам, браузерам... Так же можно из HTTP_USER_AGENT вытащить браузер и ОС и записать их в более удобном виде. Кстати, все размеры при выводе статистики я расчитывал при разрешении 1024*768 и у меня все удобно помещается в одну строку. Этот скрипт можно скачать с моего сайта: http://coding.pp.ru . Если возникнут вопросы, то я с удовольствием на них отвечу: admin@coding.wp-club.net .
Работа с MS Access в PHP
,
Если Вы планируете создавать свой динамический сайт на платформе Windows, то у Вас скорее всего возникнет задача выбора СУБД для хранения информации (с языком, на котором Вы будете его программировать, судя по всему, вопросов не возникает). Одним из вариантов её решения, может оказаться использование MS Access в качестве SQL-сервера. Далее будет описано, как в скрипте, написанном на PHP, обратиться к базе данных MS Access.
К сожалению, в PHP нет встроенных средств для работы с этой СУБД, что, однако не исключает совместной их работы - для подключения к базе мы будем использовать ODBC.
Первым делом мы должны создать так называемый DSN Source. Для этого (рассматривается вариант, когда у пользователя установлена ОС Windows 2000 Rus) в панели управления мы должны выбрать пункт Администрирование, а затем Источники данных (ODBC). Далее, в появившемся окне (рис.1)
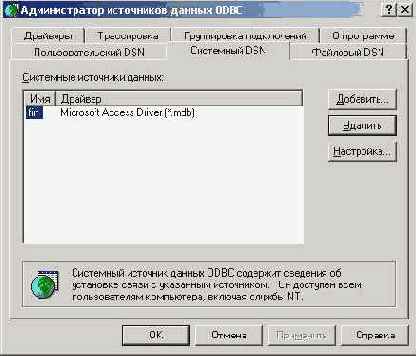
рис. 1
выбираем вкладку системный DSN, нажимаем кнопку добавить, выбираем драйвер MS Access (рис.2)
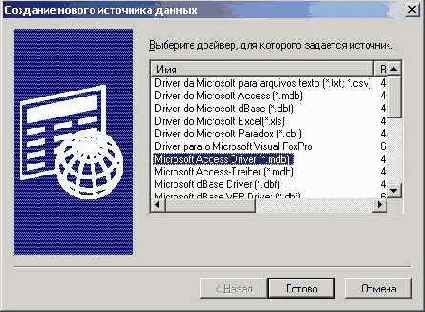
рис. 2
и нажимаем кнопку готово. В поле ввода имя источника данных пишем имя, по которому впоследствии мы сможем обратиться к нашей базе данных, например, test, затем нажимаем кнопку выбрать и указываем, где у нас на диске находится наш файл с БД (рис. 3)
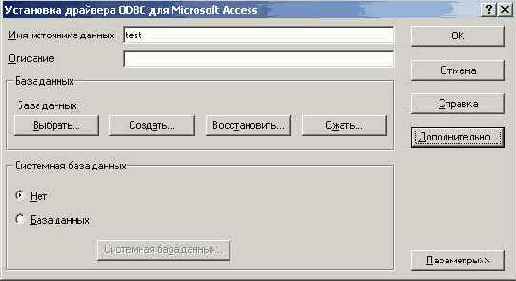
рис. 3
Затем, если в этом есть необходимость, можем задать имя пользователя и пароль для доступа к БД через ODBC, нажав на кнопку дополнительно (рис. 4)
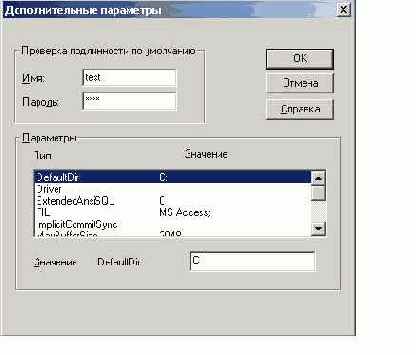
рис. 4
Теперь, когда у нас есть источник данных ODBC, мы можем воспользоваться функцией odbc_connect для подключения к нашей базе:
<? $x=odbc_connect("test","test","test"); ?>
Чтобы передать запрос в СУБД, мы можем воспользоваться функцией odbc_exec:
<? $res=odbc_exec($x,"create table test (f1 integer, f2 varchar(10))"); $res=odbc_exec($x,"insert into test (f1,f2) values(1,'qwerty')"); $res=odbc_exec($x,"insert into test (f1,f2) values(2,'asdfgh')"); ?>
Если после выполнения этого примера открыть базу test в MS Access, то мы обнаружим, что там появилась новая таблица test с полями f1 и f2 целочисленного и строкового типов соответственно; в таблице будут две записи с данными, которые были указаны в запросе.
К сожалению, не все функции для работы с ODBC корректно работают с MS Access, например, это функции odbc_num_rows и odbc_fetch_array. Так, в той версии PHP, что установлена на моём компьютере, PHP вообще выдаёт сообщение, что функция odbc_fetch_array ему не известна. Но эти проблемы решаются, если описать две следующие функции и использовать их вместо ранее упоминавшихся:
<? function xodbc_num_rows($sql_id, $CurrRow = 0) { $NumRecords = 0; odbc_fetch_row($sql_id, 0); while (odbc_fetch_row($sql_id)) { $NumRecords++; } odbc_fetch_row($sql_id, $CurrRow); return $NumRecords; } function xodbc_fetch_array($result, $rownumber=-1) { if ($rownumber < 0) { odbc_fetch_into($result, &$rs); } else { odbc_fetch_into($result, &$rs, $rownumber); } foreach ($rs as $key => $value) { $rs_assoc[odbc_field_name($result, $key+1)] = $value; } return $rs_assoc; }
$res=odbc_exec($x,"select * from test"); $cnt=xodbc_num_rows($res); ?>
<table border=1 cellspacing=0 cellpadding=4>
<tr><td>f1</td><td>f2</td></tr>
<? for ($i=0;$i<$cnt;$i++) { $row=xodbc_fetch_array($res,$i+1); echo '<tr><td>'.$row['f1'].'</td><td>'.$row['f2'].'</td></tr>'; } ?>
</table>
Результат выполнения этого примера приведён ниже:
| f1 | f2 |
| 1 | qwerty |
| 2 | asdfgh |