В РНР также существуют другие функции, упрощающие процесс обработки кода XML.
utf8_decode( )
Функция преобразует данные в кодировку ISO-8859-1. Предполагается, что преобразуемые данные находятся в кодировке UTF-8. Синтаксис:
string utf8_decode(string данные)
Параметр данные содержит преобразуемые данные в кодировке UTF-8.
utf8_encode( )
Функция преобразует данные из кодировки ISO-8859-1 в кодировку UTF-8. Синтаксис:
string utf8_decode(string данные)
Параметр данные содержит преобразуемые данные в кодировке ISO-8859-1.
xml_get_error_code( )
Функция xm1_get_error_code( ) получает код ошибки, возникшей в процессе обработки XML. Код ошибки передается функции xml_error_string( ) (см. ниже) для интерпретации. Синтаксис:
int xml_error_code(int анализатор)
Параметр функции определяет анализатор XML. Пример использования приведен ниже, в описании функции xml_get_current_line_number( ).
xml_error_string( )
Ошибкам, возникающим в процессе анализа кода XML, присваиваются числовые коды. Функция xml_error_string( ) возвращает текстовое описание ошибки по ее коду. Синтаксис:
string xml_error_string(int код)
В параметре функции передается код ошибки (вероятно, полученный при вызове функции xml_get_error_code( )). Пример использования функции приведен ниже, в описании функции xml_get_current_line_number( ).
xml_get_current_line_number( )
Функция возвращает номер текущей строки, обрабатываемой анализатором XML. Синтаксис:
int xml_get_current_line_number(int анализатор)
Параметр функции определяет анализатор XML. Пример использования функции:
Например, если ошибка была обнаружена в шестой строке файла, определяемого манипулятором $fh, сообщение будет выглядеть примерно так:
Error! [Line 6]:mi snatched tag
xml_get_current_column_number( )
Функция xml_get_current_colunin_number( ) может использоваться в сочетании с xml_get_current_line_number( ) для определения точного местонахождения ошибки в документе XML. Синтаксис:
int xml_get_current_column_number(int анализатор)
Параметр функции определяет анализатор XML. Давайте усовершенствуем предыдущий пример:
Например, если ошибка была обнаружена в шестой строке файла, определяемого манипулятором $fh, сообщение будет выглядеть примерно так:
Error! [Line 6 Column 2]:mismatched tag
Функции обработки кода XML
Хотя реализация всех функций-обработчиков не обязательна (документы XML не обязаны содержать элементы всех типов), по крайней мере три функции должны присутствовать во всех сценариях, работающих с XML.
xml_parser_create( )
Перед обработкой документа XML необходимо предварительно создать анализатор. Синтаксис:
int xml_parser_create([stnng кодировка])
Необязательный параметр определяет кодировку исходного текста. В настоящее время поддерживаются три варианта кодировки:
UTF-8;
US-ASCII;
ISO-8859-1 (используется по умолчанию).
По аналогии с тем, как функция fopen( ) возвращает манипулятор открытого файла, функция xml_parser_create( ) также возвращает манипулятор, используемый для вызова различных функций в процессе обработки XML. При одновременной обработке нескольких документов можно создать сразу несколько анализаторов.
xml_parse()
Функция xml_parse( ) выполняет обработку документа XML. Синтаксис:
int xml_parse(int анализатор, string данные [int завершение])
Первый параметр определяет анализатор XML (используется значение, возвращаемое при вызове xml_parser_create( )). Если необязательный параметр завершение равен TRUE, передаваемый фрагмент данных является последним. Как правило, это происходит при достижении конца обрабатываемого файла.
xml_parser_free( )
Функция освобождает ресурсы, выделенные для работы анализатора. Синтаксис:
int xml_parser_free(int анализатор)
Параметр функции определяет анализатор XML.
PHP 4 на практике
РНР и XML
Бесспорно, развитие World Wide Web оказало заметное влияние на способы обмена информацией. Вследствие огромных размеров этой электронной сети соблюдение стандартов превратилось из простого удобства в обязательное требование — конечно, если ваша организация собирается в полной мере использовать потенциал Web. Одним из таких стандартов является язык XML (extensible Markup Language) — удобное средство обмена данными между организациями и приложениями.
В начале этой главы приведены общие сведения о XML, при этом особое внимание уделяется общему синтаксису языка. Второй раздел посвящен средствам РНР для работы с XML. Мы рассмотрим стандартные функции поддержки XML, а также схему общего процесса обработки файлов в формате XML. Этот материал позволит вам лучше понять, чем же так ценен XML и как РНР может применяться для разработки полезных и интересных приложений на базе XML.
Но прежде чем переходить к непосредственному описанию XML, я расскажу о том, как же развивались концепции, в конечном счете приведшие к возникновению формата XML.
В этой главе был изложен
В этой главе был изложен довольно обширный материал, касающийся XML и возможностей обработки кода XML в РНР. Глава начинается с краткой истории языков разметки. Читатель знакомится с XML и его основными преимуществами, после чего приводится сводка синтаксических конструкций языка. Оставшаяся часть главы посвящена стандартным функциям РНР для работы с кодом XML. В завершение приводятся примеры использования РНР для обработки и вывода данных XML. В частности, рассматриваются следующие вопросы:
краткое описание языков разметки текста;
SGML;
общие сведения о XML;
синтаксис XML;
описание типа документа (DTD);
РНР и XML.
В главе 15 рассматриваются две перспективные технологии, JavaScript и СОМ (Component Object Model), и возможности их использования в РНР.
Язык SGML
SGML представляет собой международный стандарт обмена электронной информацией между различными аппаратными и программными компонентами. По названию можно предположить, что SGML — это язык. На самом деле это не совсем так, поскольку SGML в действительности определяет формализованный набор правил для создания языков. На базе SGML были созданы два самых популярных языка разметки — HTML и XML. Как вы уже знаете, HTML — плат-форменно- и аппаратно-независимый язык, предназначенный для форматирования и отображения текста. То же самое можно сказать и о XML.
Появление стандарта SGML было обусловлено необходимостью совместного использования данных разными приложениями и операционными системами. Даже в далеких 60-х годах у пользователей компьютеров возникало немало проблем с совместимостью. Проанализировав недостатки многих нестандартных языков разметки, трое ученых из IBM — Чарльз Гольдфарб (Charles Goldfarb), Эд Мо-шер (Ed Mosher) и Рэй Лори (Ray Lorie) — сформулировали три общих принципа, обеспечивающих возможность совместной работы с документами в разных операционных системах:
Использование единых принципов форматирования во всех программах, выполняющих обработку документов. Вполне логичное требование — всем нам хорошо известно, как трудно договориться между собой людям, говорящим на разных языках. Наличие единого набора синтаксических конструкций и общей семантики заметно упрощает взаимодействие между программами.
Специализация языков форматирования. Благодаря возможности построения специализированного языка на базе набора стандартных правил программист
перестает зависеть от внешних реализаций и их представлений о потребностях конечного пользователя
Четкое определение формата документа.
Правила, определяющие формат документа, задают количество и маркировку языковых конструкций, используемых в документе. Применение стандартного формата гарантирует, что пользователь будет точно знать структуру содержимого документа. Обратите внимание: речь идет не о формате отображения документа, а о его структурном формате. Набор правил, описывающих этот формат, называется «определением типа документа» (document type definition, DTD).
Эти три правила были заложены в основу предшественника SGML — GML (Generalized Markup Language). Исследования и разработка GML продолжались около десяти лет, пока в результате соглашения, заключенного международной группой разработчиков, не появился стандарт SGML.
В 1980-х годах необходимость в общих средствах обмена информацией непрерывно возрастала, и SGML вскоре превратился в отраслевой стандарт (в 1986 году он был принят в качестве стандарта ISO). Даже в наши дни этот стандарт занимает достаточно сильные позиции, поскольку многие организации, работающие с огромными объемами информации, полагаются на SGML как на удобное и надежное средство хранения данных. Чтобы подкрепить сказанное, замечу, что Бюро патентов и товарных знаков США (http://www.uspto.gov), Служба внутренних сборов США (http://www.irs.gov) и Библиотека Конгресса (http://lcweb.loc.gov) используют SGML в своих основных приложениях. Только представьте, какой объем документации проходит через эти организации за год!
Одним из лучших ресурсов Интернета, посвященных SGML, XML и другим языкам раз-метки, является сайт Robin Cover/OASIS XML Cover Pages (http://www.oasis-open.org/cover).
Идея передачи гипертекстовых документов через web-браузер, предложенная Тимом Бернерсом-Ли (Tim Berners-Lee), не требовала многих возможностей, поддерживаемых полной реализацией SGML. В результате появился известный язык разметки HTML.
Несколько слов о РНР и XML
В этой главе мы познакомились с XML и различными функциями РНР, предназначенными для обработки документов в формате XML. Поскольку основной темой книги является РНР, я описал лишь одну из трех спецификаций стандарта XML и не упомянул о том, как работают XSL и XLL. Конечно, полноценное отделение содержания от представления требует использования всех трех компонентов или по меньшей мере XML и XSL.
К сожалению, на момент написания книги РНР еще не обладал возможностями, которые бы позволяли работать с XML исключительно средствами РНР. Конечно,
возможности РНР продолжают расширяться, и в будущем эта проблема обязательно будет решена.
Особого внимания в этой области заслуживает XSL-процессор Sablotron, разработанный компанией Ginger Alliance Lts. (http://www.gingerall.com). 12 октября 2000 года было объявлено о том, что РНР 4.03 отныне распространяется с модулем расширения Sablotron для платформ Linux и Windows. Обязательно проследите за дальнейшим развитием событий.
Определение типа документа (DTD)
DTD
представляет собой совокупность синтаксических правил, на основе которых проверяется структура документа XML. В DTD явно определяется структура документа XML, указываются элементы и их атрибуты, а также приводится другая информация, распространяющаяся на все документы XML, созданные на основе данного DTD.
Учтите, что наличие DTD не является обязательным. Если DTD существует, система XML руководствуется им при интерпретации документа XML. Если DTD отсутствует, предполагается, что система XML должна интерпретировать документ по собственным правилам. Впрочем, для документов XML все же рекомендуется создавать DTD, поскольку это упрощает их интерпретацию и проверку структуры.
DTD можно включить непосредственно в документ XML, сослаться на него по URL или использовать комбинацию этих двух способов. При непосредственном включении DTD в документ XML определение DTD располагается сразу же после пролога:
<!DOCTYPE имя_корневого_элемента [
...прочие объявления...
] >
Атрибут имя_корневого_элемента соответствует имени корневого элемента в тегах, содержащих весь документ XML. В секции «прочих объявлений» находятся определения элементов, атрибутов и т. д.
Возможно, вы предпочитаете разместить DTD в отдельном файле, чтобы обеспечить модульную структуру программы. Давайте посмотрим, как выглядит ссылка на внешний DTD в документе XML. Задача решается одной простой командой:
<!DOCTYPE имя_корневого_элемента SYSTEM "some_dtd.dtd">
Как и в случае с внутренним объявлением DTD, имя_корневого_элемента должно соответствовать имени корневого элемента в тегах, содержащих весь документ XML. Атрибут SYSTEM указывает на то, что some_dtd.dtd находится на локальном сервере. Впрочем, на файл some_dtd.dtd также можно сослаться по его абсолютному URL. Наконец, в кавычках указывается URL внешнего DTD, расположенного на локальном или на удаленном сервере.
Как же создать DTD для листинга 14.1? Во-первых, мы собираемся создать в документе XML ссылку на внешний DTD. Как упоминалось в предыдущем разделе, ссылка на DTD выглядит так:
<!DOCTYPE cookbook SYSTEM "cookbook.dtd">
Возвращаясь к листингу 14.1, мы видим, что cookbook является именем корневого элемента, a cookbook.dtd — именем DTD-файла. Содержимое DTD показано в листинге 14.2, а ниже приведены подробные описания всех строк.
Что же означает этот загадочный документ? Несмотря на внешнюю сложность, в действительности он довольно прост. Давайте переберем все содержимое листинга 14.2:
<?xml version="1.0"?>
Перед нами пролог XML, о котором уже говорилось выше.
<!DOCTYPE cookbook [
Вторая строка сообщает, что далее следует DTD с именем cookbook.
<!ELEMENT cookbook (recipe+)>
Третья строка описывает элемент XML, в данном случае — корневой элемент cookbook. После него следует слово recipe, заключенное в круглые скобки. Это означает, что в теги cookbook заключается вложенный тег с именем recipe. Знак + говорит о том, что в родительских тегах cookbook находится одна или несколько пар тегов recipe.
Четвертая строка описывает тег recipe. В ней сообщается, что в тег recipe входят четыре вложенных тега: title, description, ingredients и process. Поскольку после имен тегов не указываются признаки повторения (см. следующий раздел), внутри тегов recipe должна быть заключена ровно одна пара каждого из перечисленных тегов.
<! ELEMENT title (#PCDATA)>
Перед нами первое определение тега, который не содержит вложенных тегов. В соответствии с определением он содержит #PCDATA, то есть произвольные символьные данные, не считающиеся частью разметки.
<!ELEMENT ingredients (ingredient+)>
В соответствии с определением элемент ingredients содержит один или несколько тегов с именем ingredient. Обратитесь к листингу 14.1, и вы все поймете.
<! ELEMENT ingredient (#PCDATA)>
Поскольку элемент ingredient соответствует отдельному ингредиенту, вполне логично, что этот элемент содержит простые символьные данные.
<! ELEMENT process (step+)>
Элемент process содержит один или несколько экземпляров элемента step.
<! ELEMENT step (#PCDATA)>
Элемент step, как и элемент ingredient, соответствует отдельному пункту в списке более высокого уровня. Следовательно, он должен содержать символьные данные.
<!ATTLIST recipe category CDATA #REQUIRED>
Обратите внимание: элемент recipe в листинге 14.1 содержит атрибут. Этот атрибут, category, определяет общую категорию, к которой относится рецепт — в приведенном примере это категория «итальянская кухня» (Italian). В определении ATTLIST указывается как имя элемента, так и имя атрибута. Кроме того, отнесение каждого рецепта к определенной категории упрощает классификацию, поэтому атрибут объявляется обязательным (#REQUIRED).
]>
Последняя строка просто завершает определение DTD. Определение всегда должно быть должным образом завершено, иначе произойдет ошибка.
В завершение этого раздела я приведу сводку основных компонентов типичного DTD-файла:
объявления типов элементов;
объявления атрибутов;
ID, IDREF и IDREFS;
объявления сущностей.
Некоторые из этих компонентов уже встречались нам в описании листинга 14.2. Далее каждый компонент будет описан более подробно.
Объявления элементов
Все элементы, используемые в документе XML, должны быть определены в DTD, прилагаемом к документу. Мы уже встречались с двумя распространенными разновидностями определений: для элемента, содержащего другие элементы, и элемента, содержащего символьные данные. Данное определение свидетельствует, что элемент содержит только символьные данные:
<! ELEMENT описание (#РСDАТА)>
Следующее определение элемента process говорит о том, что он содержит ровно один вложенный элемент с именем step:
<!ELEMENT process (step)>
Впрочем, процессы (process) из одного шага (step) встречаются довольно редко — скорее всего, шагов будет несколько. Чтобы указать, что элемент содержит один или несколько экземпляров вложенного элемента step, следует воспользоваться признаком
повторения:
<!ELEMENT process (step+)>
Количество вложенных элементов можно задать несколькими способами. Полный список операторов элементов приведен в табл. 14.1.
Таблица 14.1.
Операторы элементов
Признак
Значение
?
Ноль или ровно один экземпляр
*
Ноль или несколько экземпляров
+
Один или несколько экземпляров
Ровно один экземпляр
|
Один из элементов
,
Перечисление элементов
Если элемент будет содержать несколько вложенных элементов, их следует перечислить через запятую в определении родительского элемента:
Поскольку признаки повторения не указаны, каждый тег должен встречаться ровно один раз.
Определение элемента уточняется при помощи логических операторов. Предположим, вы работаете с рецептами, в которые всегда входят макароны (pasta) с одним или несколькими типами сыра (cheese) или мяса (meat). В этом случае элемент ingredient определяется следующим образом:
<!ELEMENT ingredient (pasta+, (cheese | meat)+)>
Поскольку элемент pasta обязательно должен присутствовать в элементе ingredient, он указывается с признаком повторения +. Затем следует либо элемент cheese, либо элемент meat; мы разделяем альтернативы вертикальной чертой и заключаем их в круглые скобки со знаком +, поскольку в рецепт всегда входит либо одно, либо другое.
Существуют и другие разновидности определений элементов. Мы рассмотрели лишь простейшие случаи. Тем не менее, приведенного материала вполне достаточно для понимания примеров, приведенных в оставшейся части этой главы.
Объявления атрибутов
Атрибуты элементов
описывают значения, связываемые с элементами. Элементы XML, как и элементы HTML, могут иметь ноль, один или несколько атрибутов. Общий синтаксис объявления атрибутов выглядит следующим образом:
Имя_элемента определяет имя элемента, включаемое в тег. Затем перечисляются атрибуты, связанные с данным элементом. Объявление каждого атрибута состоит из трех основных компонентов: имени, типа данных и флага, определяющего особенности данного атрибута. Вместо многоточия (...) могут быть расположены объявления других атрибутов.
Простое объявление атрибута уже встречалось нам в листинге 14.2:
<!ATTLIST recipe category CDATA #REQUIRED>
Тем не менее, как видно из приведенного общего определения, допускается одновременное объявление нескольких атрибутов. Допустим, в дополнение к атрибуту category вы хотите связать с элементом recipe дополнительный атрибут difficulty (сложность приготовления). Оба атрибута объявляются в одном списке:
Форматировать объявления подобным образом необязательно; тем не менее, многострочные объявления нагляднее однострочных. Кроме того, поскольку оба атрибута являются обязательными, тег reci ре не может ограничиться каким-нибудь одним атрибутом, он должен включать в себя оба атрибута сразу. Например, следующий тег будет считаться неверным: <recipe difficulty="hard">
Почему? Потому что в нем отсутствует атрибут category. Правильный тег должен содержать оба атрибута:
<recipe category="Italian" difficulty="hard">
Особые условия обработки атрибута описываются тремя флагами, перечисленными в табл. 14.2.
Таблица 14.2.
Флаги атрибутов
Флаг
Описание
#FIXED
Во всех экземплярах элемента в документе атрибуту может присваиваться только одно конкретное значение
#IMPLIED
Если атрибут не указан в элементе, используется значение по умолчанию
#REQUIRED
Атрибут является обязательным и должен присутствовать во всех экземплярах элемента в документе
<
/p>
Типы атрибутов
Атрибут элемента может объявляться с определенным типом. Типы атрибутов описаны далее.
Атрибуты CDATA
Очень часто атрибуты содержат общие символьные данные. Такие атрибуты называются атрибутами CDATA. Следующий пример уже встречался в начале этого раздела:
<!ATTLIST recipe category COATA #REQUIRED>
Атрибуты ID, IDREF и IDREFS
Идея однозначного представления данных (например, информации о пользователе или товаре, хранящейся в базе данных) посредством идентификаторов неоднократно встречалась в предыдущих главах книги. Идентификаторы также часто используются в XML, поскольку перекрестные ссылки между документами применяются не только в общих задачах обработки данных, но и в World Wide Web (гиперссылки).
Идентификаторы элементов присваиваются атрибуту ID. Допустим, вы хотите связать с каждым рецептом уникальный идентификатор. Соответствующий фрагмент DTD может выглядеть так:
После этого объявление элемента recipe в документе может выглядеть так:
<recipe recipe-id="ital003">
<title>Spaghetti alla Carbonara</title>
Рецепт однозначно определяется идентификатором ital003. Следует помнить, что атрибут redpe-id относится к типу ID, поэтому ital003 не может использоваться в качестве значения атрибута recipe-id другого элемента, в противном случае документ будет считаться синтаксически неверным. Теперь допустим, что позднее вы захотели сослаться на этот рецепт из другого документа — скажем, из списка любимых рецептов пользователя. Именно здесь в игру вступают перекрестные ссылки и атрибут IDREF. Атрибуту IDREF присваивается идентификатор, используемый для ссылок на элемент, — по аналогии с тем, как URL используется для идентификации страницы в гиперссылке. Рассмотрим следующий фрагмент кода XML:
<favoriteRecipes>
<recipe-ref go="ital003">
</favoriteRecipes>
В процессе обработки документа XML элемент заменяется более наглядной ссылкой на рецепт с указанным идентификатором (например, названием рецепта). Вероятно, он будет отформатирован в виде гиперссылки, чтобы упростить переход к указанному рецепту.
Перечисляемые атрибуты
При объявлении атрибута можно перечислить все допустимые значения, принимаемые атрибутом. В нашем примере это было бы удобно, поскольку вы можете сразу определить список допустимых категорий. Приведенное выше объявление записывается в следующем виде:
<!ATTLIST recipe category (Italian | French | Japanese | Chinese) #REQUIRED difficulty (easy | medium | hard) #REQUIRED)
Обратите внимание: при использовании списков допустимых значений включать в объявление тип CDATA не нужно, поскольку все перечисленные значения относятся к формату CDATA.
Перечисляемые атрибуты со значением по умолчанию
Иногда бывает удобно объявить для атрибута значение по умолчанию. Скорее всего, вам уже приходилось делать это раньше при построении форм с раскрывающимися списками. Например, если большинство рецептов в вашей поваренной книге относится к итальянской кухне, атрибут recipe будет часто относиться к категории Italian. В этом случае категорию Italian можно назначить по умолчанию:
<!ATTLIST recipe category (Italian | French | Japanese | Chinese) "Itaian">
Если атрибут category не задан явно, по умолчанию ему присваивается значение Italian.
Атрибуты ENTITY и ENTITIES
Данные в документах XML не всегда являются текстовыми — документ может содержать и двоичную информацию (например, графику). На такие данные можно ссылаться при помощи атрибута entity. Например, в описании элемента description можно указать атрибут recipePicture с графическим изображением:
Также можно объявить сразу несколько сущностей, заменив ENTITY на ENTITIES. Значения разделяются пробелами.
Атрибуты NMTOKEN и NMTOKENS
Атрибуты NMTOKEN представляют собой строки из символов, входящих в ограниченный набор. Объявление атрибута с типом NMTOKEN предполагает, что значение атрибута соответствует установленным ограничениям. Как правило, значение атрибута NMTOKEN состоит из одного слова:
<!ATTLIST recipe category NMTOKEN #REQUIRED>
Можно объявить сразу несколько атрибутов, заменив NMTOKEN на NMTOKENS. Значения разделяются пробелами.
Объявления сущностей
Объявление сущности напоминает команду define в некоторых языках программирования, включая РНР. Ссылки на сущности кратко упоминались в предыдущем разделе «Знакомство с синтаксисом XML». На всякий случай напомню, что ссылка на сущность используется в качестве замены для другого фрагмента содержания. В процессе обработки документа XML все вхождения сущности заменяются содержанием, которое она представляет. Существует два вида сущностей: внутренние и внешние.
Внутренние сущности
Внутренние сущности напоминают строковые переменные, связывающие имя с фрагментом текста. Например, если вы хотите определить имя для ссылки на информацию об авторских правах, можно объявить сущность следующего вида:
<!ENTITY Copyright "Copyright 2000 YourCompanyName. All Rights Reserved.">
В процессе обработки документа все экземпляры &Соруright заменяются текстом «Copyright 2000 YourCompanyName. All Rights Reserved». Весь код XML в заменяющем тексте обрабатывается так, словно он присутствовал в исходном документе.
Внутренние сущности удобны в ситуациях, когда вы планируете использовать сущность в относительно небольшом количестве документов XML. При большом количестве документов лучше воспользоваться внешними сущностями.
Внешние сущности
Внешние сущности используются для ссылок на содержание, находящееся в другом файле. Сущности этого типа могут содержать текстовую информацию, но также могут ссылаться и на двоичные данные (например, графику). Возвращаясь к предыдущему примеру, допустим, что вы решили сохранить информацию об авторских правах в отдельном файле, чтобы упростить ее редактирование в будущем. Ссылка на созданный файл выглядит следующим образом:
<!ENTITY Copyright SYSTEM "http://yoursite.com/administer/copyright.xml">
При последующей обработке документа XML все ссылки &Соруright заменяются содержимым документа copyright.xml. Весь код XML в заменяющем тексте обрабатывается так, словно он присутствовал в исходном документе.
Внешние сущности также удобно использовать для ссылок на графические изображения. Например, если вы хотите включить в документ XML графический логотип, создайте внешнюю сущность:
<!ENTITY food_picture SYSTEM http://yoursite.com/food/logo.gif>
Как и в предыдущем примере, все ссылки &food_picture заменяются графическим изображением, на которое указывает ссылка. Поскольку данные являются двоичными, а не текстовыми, они не интерпретируются.
Ресурсы, посвященные XML
Хотя приведенного выше материала вполне достаточно для понимания базовой структуры документов XML, данное описание не является полным. Ниже приведены ссылки на ресурсы Интернета, содержащие более подробную информацию:
http://www.w3.org/XML;
http://www.xml.com/pub/ArticlesByTopic;
http://ww.ibm.com/developer/xml;
http://www.oasis-open.org.cover.
В оставшейся части главы рассказано о том, как использовать РНР для обработки документов XML. На первый взгляд задача кажется очень сложной (лексический анализ любых документов любого типа вызывает немало затруднений).
Но стоит познакомиться с базовой стратегией работы с XML в РНР, и все оказывается на удивление просто.
Параметры анализатора XML
В настоящее время в РНР поддерживаются два параметра, влияющих на работу анализатора XML:
XML_OPTION_CASE_FOLDING — автоматическое преобразование имен тегов к верхнему регистру;
XML_OPTION_TARGET_ENCODING — кодировка документа на выходе анализатора XML. В настоящее время поддерживаются кодировки UTF-8, ISO-8859-1 и US-ASCII.
Для получения текущих значений и модификации этих параметров применяются, соответственно, функции xml_parser_get_option( ) и xml_parser_set_option( ).
xml_parser_get_option( )
Функция xml_parser_get_option( ) получает текущее значение параметра анализатора XML. Синтаксис:
int xml_parser_get_option(int анализатор, int параметр)
Первый параметр функции определяет анализатор XML, а второй — имя интересующего вас параметра. Пример:
Если параметру XML_OPTION_CASE_FOLDING не присваивалось другое значение, функция вернет значение по умолчанию. В этом случае будет выведен следующий результат:
Case Folding: 1
xml_parser_set_option( )
Функция xml_parser_set_option() задает значение параметра анализатора XML. Синтаксис:
int xml_parser_set_option(int анализатор, int параметр, mixed значение)
Первый параметр функции определяет анализатор XML, второй — имя интересующего вас параметра, а третий — его новое значение. Пример:
В результате выполнения этой команды выходная кодировка документа изменяется с ISO-8859-1 на UTF-8.
Подключение пользовательских функций к обработке XML
В РНР существует восемь стандартных функций для регистрации пользовательских функций, обрабатывающих различные компоненты документов XML.
Следует помнить, что вы обязательно должны определить все пользовательские функции; в противном случае произойдет ошибка. В этом разделе перечислены все стандартные функции регистрации и приведены спецификации всех пользовательских функций.
xml_set_character_data_handler()
Функция регистрирует пользовательскую функцию для работы с символьными данными. Синтаксис:
int xml_set_character data_handler(int анализатор, string обработчик_символьных_данных)
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой при обработке символьных данных. Определение функции-обработчика должно выглядеть так:
function обработчик_символьных_данных (int анализатор, string данные) {
...
}
Первый параметр определяет анализатор XML, а второй — символьные данные, подлежащие обработке.
xml_set_default_handler( )
Функция регистрирует пользовательскую функцию для всех незарегистрированных компонентов документа XML. В частности, к числу таких компонентов относятся пролог XML и комментарии. Синтаксис:
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой по умолчанию. Определение функции-обработчика должно выглядеть так:
function обработчик_по_умолчанию (int анализатор, string данные) {
...
}
Первый параметр определяет анализатор XML, а второй — символьные данные, подлежащие обработке.
xml_set_element_handler( )
Функция регистрирует пользовательские функции для обработки открывающих и закрывающих тегов элементов. Синтаксис:
int xml_set_element_handler(int анализатор, string обработчик_открывающих_тегов, string обработчик_закрывающих_тегов)
Первый параметр определяет анализатор XML. Второй и третий параметры определяют имена функций, используемых для обработки, соответственно, открывающих и закрывающих тегов. Определение обработчика открывающих тегов должно выглядеть так:
function обработчик_открывающих_тегов (int анализатор, string имя_тега,
string атрибуты[ ]) {
...
}
Первый параметр определяет анализатор XML, второй — имя открывающего тега для анализируемого элемента, а третий содержит массив атрибутов соответствующего тега.
Обработчик закрывающих тегов определяется следующим образом:
function обработчик_закрывающих_тегов (int анализатор, string имя_тега) {
...
}
Первый параметр определяет анализатор XML, второй — имя закрывающего тега для анализируемого элемента.
xml_set_external_entity_ref_handler( )
Функция регистрирует пользовательскую функцию для обработки внешних ссылок на сущности. Синтаксис:
int xml_set_external_entity_ref_handler(int анализатор, string обработчик_внешних_ссылок)
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой при обработке внешних ссылок. Определение функции-обработчика должно выглядеть так:
Первый параметр определяет анализатор XML. Второй параметр определяет имя ссылки, четвертый — системный идентификатор ссылки на сущность, а пятый — открытый идентификатор ссылки. Третий параметр, база, в настоящее время не используется, однако его объявление все равно обязательно.
xml_set_notation_decl_handler ( )
Функция регистрирует пользовательскую функцию для обработки синтаксических объявлений. Синтаксис:
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой при обработке синтаксических объявлений. Определение функции-обработчика должно выглядеть так:
Первый параметр определяет анализатор XML. Второй параметр определяет имя объявления, четвертый — системный идентификатор, а пятый — открытый идентификатор объявления. Третий параметр, база, в настоящее время не используется, однако его объявление все равно обязательно.
xml_set_object( )
Функция ассоциирует анализатор XML с некоторым объектом. Синтаксис:
Первый параметр определяет анализатор XML, а второй содержит ссылку на объект, методы которого будут использоваться для обработки компонентов XML. Таким образом, функция xml_set_object связывает анализатор с объектом. Как правило, она вызывается в конструкторе объекта перед определениями функций-обработчиков:
... Определения функций-обработчиков startTag. endTag. characterData и т.д. ...
} // class xmlDB
В порядке эксперимента попробуйте закомментировать вызов xml_set_object( ). Вы увидите, что при выполнении этого фрагмента выводятся сообщения об ошибках, в которых говорится о невозможности обращения к методам объекта.
xml_set_processing_instruction_handler( )
Функция регистрирует пользовательскую функцию для работы с Pi-инструкциями.
Синтаксис:
int xml_set_processing_instruction_handler(int анализатор, string обработчик_инструкций)
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой при обработке Pi-инструкций. Определение функции-обработчика должно выглядеть так:
function обработчик_инструкций (int анализатор, string приложение, string инструкция) {
...
}
Первый параметр определяет анализатор XML, второй — имя приложения, выполняющего инструкции, а третий — инструкцию, передаваемую приложению.
xml_set_unparsed_entity_decl_handler( )
Функция регистрирует пользовательскую функцию для необработанных внешних ссылок на сущности. Синтаксис:
int xml_set_external_entity_ref_handler(int анализатор, string обработчик_внешних_ссылок)
Первый параметр определяет анализатор XML, а второй — имя пользовательской функции, используемой для обработки необработанных внешних ссылок. Определение функции-обработчика должно выглядеть так:
Первый параметр определяет анализатор XML. Второй параметр определяет имя ссылки, четвертый — системный идентификатор ссылки на сущность, а пятый — открытый идентификатор ссылки. Третий параметр, база, в настоящее время не используется, однако его объявление все равно обязательно. Наконец, последний параметр определяет имя синтаксического объявления.
На этом завершается наше краткое знакомство с обработчиками и функциями регистрации. Впрочем, для эффективной обработки документов XML вам понадобятся и другие функции. В следующем разделе представлены остальные функции РНР, связанные с обработкой кода XML.
Преобразование XML в HTML
Предположим, у вас имеется документ XML bookmarks.xml, содержащий список ссылок. Он выглядит примерно так:
<?xml version="1.0"?>
<website>
<title>Epicurious</title>
<url>http://www.epicurious.com</url>
<description>
Epicurious is a great online cooking resource, providing tutorials.
recipes, forums and more.
</description> </website>
Допустим, вы хотите преобразовать bookmarks.xml и вывести его содержимое в формате, совместимом с форматом браузера вашего компьютера. Программа, приведенная в листинге 14.3, преобразует файл к нужному формату.
В результате преобразования файл bookmarks.xml выводится в браузере в следующем виде:
<WEBSITE>
<TITLE>
Epicurious
</TITLE>
<URL>
http : //www.epicurious.com
</URL>
<DESCRIPTION>
Epicurious is a great online cooking resource,
providing tutorials, recipes, forums and more.
</DESCRIPTION>
</WEBSITE>
Конечно, результат не такой уж впечатляющий — мы всего лишь добились, чтобы файл XML отображался в браузере. Внеся небольшие изменения в листинг 14.3, можно преобразовать URL в работающие гиперссылки, оформить данные между парой тегов <TITLE>...</TITLE> жирным шрифтом и т. д. Как видно из листинга 14.3, я использую шрифт двух разных цветов, чтобы продемонстрировать возможность форматирования текста в браузере.
Пришествие HTML
Концепция World Wide Web идеально соответствовала идее применения обобщенного языка разметки для упрощения обмена информацией в среде, содержащей множество разных аппаратных конфигураций, операционных систем и программных реализаций. Несомненно, Бернерс-Ли учитывал это обстоятельство, поскольку он смоделировал первую версию HTML на основе стандарта SGML. HTML унаследовал некоторые характеристики SGML, в том числе простой обобщенный набор тегов и особую роль угловых скобок. Простые документы в формате HTML можно прочитать в любой компьютерной системе, в которой предусмотрены средства для просмотра текстовых документов. Все остальное — история.
Тем не менее, у HTML имеется существенный недостаток: он не позволяет разработчику создавать собственные типы документов. Результатом стала «война браузеров», в ходе которой разработчики браузеров начали создавать свои собственные усовершенствования языка HTML. Эти модификации существенно отклонялись от идеи работы с единым стандартом HTML и вызвали настоящий хаос среди разработчиков, которые хотели создавать web-сайты, не зависящие от браузера. Более того, долгий период неопределенности в области стандартов привел к тому, что разработчики вывели язык из первоначально задуманных границ. Думаю, подавляющее большинство web-страниц современного Интернета вообще не соответствуют текущей спецификации HTML.
Реакцией консорциума W3 (http://www.w3.org) на быстро ухудшающуюся ситуацию стала попытка вернуть развитие HTML на правильный путь — другими словами, вернуться к истокам SGML. Результатом этих усилий стал XML.
Разметка текста
Как нетрудно предположить по его названию, язык HTML (HyperText MarkUp Language) относится к числу так называемых языков разметки текста (markup languages). Под термином «разметка» понимается общая служебная информация, которая не выводится вместе с документом, но определяет; как должны выглядеть те или иные фрагменты документа. Например, вы можете потребовать, чтобы какое-либо слово выводилось жирным или курсивным шрифтом, вывести отдельный абзац особым шрифтом или оформлять заголовки увеличенным шрифтом. Текстовый редактор, в котором я ввожу этот абзац, тоже использует особую форму разметки для представления тех атрибутов форматирования, которые я выбираю. Таким образом, в нем тоже используется особая разновидность языка разметки. Короче говоря, язык разметки, используемый моим текстовым редактором, представляет собой средство для описания визуального оформления текста в моих документах.
В наши дни существует множество разных языков разметки. Например, в коммуникационных программах особая форма разметки определяет смысл каждого пакета из нулей и единиц, пересылаемого в Интернете. Когда мы подчеркиваем слова в книге, это тоже можно считать своего рода разметкой. Впрочем, любой язык разметки должен решать две важные задачи:
Язык определяет синтаксис разметки. Например, в соответствии со спецификацией HTML конструкция <b>text</b> определяет синтаксически правильную разметку текста, а конструкция <xR5t>text</x4rt> считается неправильной из-за несовпадения открывающего и закрывающего тегов.
Язык определяет смысл разметки. Конечно, вы знаете, что команда <b>text</b> выводит слово text жирным шрифтом. В данном случае определяется смысл, связанный с объявлением некоторого компонента документа.
Стремительное развитие Web за последние несколько лет наглядно показывает, что самым популярным языком разметки текста является HTML. Но как появился этот язык? Кто закрепил за тегами <b> и </b> определенный смысл в документе? Чтобы ответить на этот вопрос, необходимо познакомиться с предшественником HTML — SGML (Standard Generalized Markup Language).
РНР и ХМL
Для работы с XML в РНР используется пакет Джеймса Кларка (James Clark) Expat (XML Parser Toolkit) — cm. http://www.jclark.com/xml. Expat включается в поставку Apache 1.3.7 и более поздних версий, поэтому вам не придется специально загружать его, если вы используете свежую версию Apache. Чтобы воспользоваться функциональными возможностями XML в РНР, необходимо настроить РНР с ключом -with-xml.
Разработку Expat 2.0 в настоящее время ведет Кларк Купер (Clark Cooper). За дополни- тельной информацией обращайтесь по адресу http://expat.sourceforge.net.
На первый взгляд задача обработки данных XML на РHР (или на любом другом языке) выглядит устрашающе, но на самом деле большая часть работы выполняется за вас стандартными средствами РНР. Вам остается лишь определить новые функции для своих DTD и затем применить их в несложном процессе обработки кода XML.
Прежде чем переходить к рассмотрению функций РНР, предназначенных для работы с XML, необходимо познакомиться с основными компонентами документа XML. Это поможет вам лучше понять, почему эти функции являются незаменимой частью любой программы обработки XML-кода. На самом общем уровне документ XML содержит компоненты девяти видов:
открывающие теги;
атрибуты;
символьные данные;
закрывающие теги;
инструкции по обработке;
синтаксические объявления;
внешние ссылки на сущности;
необработанные сущности;
прочие компоненты (комментарии, объявления XML и т. д.).
Для эффективной обработки документов XML необходимо определить пользовательские функции-обработчики (handlers), обрабатывающие каждый из перечисленных компонентов. Определенные функции подключаются к процессу обработки XML стандартными средствами РНР. Общий процесс обработки кода XML в РНР состоит из пяти этапов:
Определите пользовательские функции. Разумеется, если вы собираетесь постоянно работать с документами XML, эти функции достаточно написать всего один раз и в дальнейшем лишь вносить в них необходимые изменения.
Создайте анализатор (parser) кода XML, который будет использоваться для обработки документа. Анализатор создается вызовом функции xml_parser_create( ).
При помощи стандартных функций зарегистрируйте свои функции в анализаторе XML.
Откройте файл XML, прочитайте содержащиеся в нем данные и передайте их анализатору XML. Обработка данных выполняется простым вызовом xml_parse( )! В процессе своей работы эта функция обеспечивает косвенный вызов всех определенных вами обработчиков.
Уничтожьте анализатор XML, чтобы освободить задействованные им ресурсы.
Задача решается функцией xml_parser_free( ). Смысл всех перечисленных этапов разъясняется в следующем разделе.
XML как неопровержимое свидетельство эволюции
XML воплощает все усилия, предпринятые W3 в области выработки Интернет-стандарта, который бы соответствовал трем главным принципам SGML (см. предыдущий раздел). XML, как и SGML, не является языком; он также представляет собой набор рекомендаций, на базе которых создаются другие языки. Точнее говоря, XML является конгломератом из трех отдельных спецификаций:
XML (Extensible Markup Language) — спецификация, определяющая базовый синтаксис XML;
XSL (Extensible Style Language) — спецификация, направленная на отделение визуального оформления страницы от ее содержимого за счет применения к документу стилей (style sheets), определяющих конкретные атрибуты форматирования;
XLL (Extensible Linking Language) — спецификация, определяющая представление ссылок на другие ресурсы.
XML не только позволяет разработчикам создавать специализированные языки для Интернет-приложений; он также обеспечивает возможность проверки этих документов на соответствие спецификации XML. Более того, XML действительно реализует концепцию данных, не зависящих от реализации, поскольку формат отображаемого документа можно точно описать при помощи XSL. Допустим, вы переформатировали свой web-сайт, чтобы он хранился в формате XML. После этого' вы сможете использовать один стиль для форматирования исходного текста XML на портативном компьютере типа Palm Pilot, а другой — для форматирования на мониторе обычного компьютера. В обоих случаях код XML остается одним и тем же, изменяется только его форматирование в соответствии с используемым устройством.
Примером популярного языка, созданного на базе XML, является WML (Wireless Markup Language).
Знакомство с синтаксисом XML
Для большинства читателей, знакомых с SGML или HTML, структура документов XML не содержит ничего нового. Пример простого документа XML приведен в листинге 14.1.
Листинг 14.1.
Пример документа XML
<?xml version="1.0"?>
<!DOCTYPE cookbook SYSTEM "cookbook.dtd">
<cookbook>
<recipe category="italian">
<title>Spaghetti alla Carbonara</title>
<description>This traditional Italian dish is sure to please even the most discriminating
critic.</description>
<ingredients>
<ingredient>2 large eggs</ingredient>
<ingredient>4 strips of bacon</ingredient>
<ingredient>l clove garlic</ingredient>
<ingredient>12 ounces spaghetti</ingredient>
<ingredient>3 tablespoons olive oil</ingredient>
</ingredients>
<process>
<step>Combine oil and bacon in large skillet over medium heat. Cook until bacon is
brown and crisp.</step>
<step>whisk eggs in bowl. Set aside.</step>
<step>Cook pasta in large pot of boiling water to taste, stirring occasionally.
Add salt as necessary.</step>
<step>Drain pasta and return to pot. adding whisked eggs. Stir over medium-low
heat for 2-3 minutes.</step>
<step>Mix in bacon. Season with salt and pepper to taste.</step>
</process>
</recipe>
</cookbook>
Обратите внимание на основные компоненты, из которых состоит документ XML:
пролог XML;
теги;
атрибуты;
ссылки на сущности;
инструкции по обработке;
комментарии.
Пролог XML
Все документы XML начинаются с пролога (prolog). Пролог сообщает, что документ написан на XML, а также указывает, какая версия XML при этом использовалась.
Поскольку текущая версия XML имеет номер 1.0, все ваши документы XML должны начинаться со строки
<?xml version="1.0">
Следующая строка в листинге 14.1 указывает на внешний DTD. Пока не обращайте на нее внимания — DTD подробно рассматриваются в следующем разделе «Определение типа документа (DTD)»:
<!DOCTYPE cookbook SYSTEM "cookbook.dtd">
Оставшаяся часть листинга 14. 1 состоит из элементов, очень похожих на элементы документов HTML. Первый элемент, cookbook, называется корневым элементом (root element), поскольку в эту пару тегов заключены все остальные теги документа. Конечно, вы можете присвоить корневому элементу любое имя по своему усмотрению. Главное, о чем следует помнить, — все остальные элементы должны находиться внутри пары корневых тегов.
Пролог может содержать другие инструкции. Например, объявление можно расширить, указав, что документ является автономным:
<?xml version="1.0" standalone="yes">
Присваивание yes атрибуту standalone сообщает механизму обработки XML-кода о том, что документ не импортирует других файлов (например, DTD).
Хотя это расширение, как и многие другие, приносит несомненную пользу, я сокращаю описание синтаксиса до минимума, чтобы лучше выделить основную тему этой главы — совместное использование РНР и XML.
Элементы
Оставшаяся часть документа состоит в основном из различных служебных элементов и соответствующих данных. Служебные элементы легко узнать по угловым скобкам (как в разметке HTML). Элемент может быть пустым или содержащим информацию; в этом случае элемент содержит открывающий и закрывающий теги. Если элемент не пуст, то в теги включаются имена, описывающие природу данных. Как видно из листинга 14.1, эти теги очень похожи на теги документов HTML. Впрочем, следует помнить о некоторых важных различиях:
Непустые элементы должны содержать как открывающий, так и закрывающий тег. В элементах, которые логически не могут иметь закрывающего тега, используется альтернативная форма синтаксиса <элемент />. Возникает вопрос — у каких элементов нет закрывающего тега? Достаточно вспомнить некоторые теги форматирования HTML — например, <br>, <hr> и <img>, у них нет парных тегов. Теги этого формата могут создаваться и в документах XML
Элементы XML должны находиться на правильном уровне вложенности. Документ XML, приведенный в листинге 14.1, синтаксически правилен; другими словами, теги элементов не встречаются там, где их быть не должно. Например, следующий фрагмент недопустим:
<title>Spaghetti alia Carbonara
<ingredients></title>
В элементах XML различается регистр символов. Некоторым читателям это наверняка не понравится. Например, в XML теги <tag>, <Tag> и <TAG> считаются разными тегами. Привыкайте поскорее — с непривычки это может свести вас с ума.
Атрибуты
Теги XML, по аналогии с тегами HTML, могут обладать атрибутами. Атрибуты содержат дополнительную информацию о содержании, которая в дальнейшем используется при форматировании или обработке XML. Значения атрибутов присваиваются в формате «имя=значение», и, в отличие от HTML, атрибуты XML должны быть заключены в апострофы или кавычки. В листинге 14.1 встречается пример использования атрибута:
<recipe category="italian">
Атрибут сообщает, что данный рецепт (recipe) относится к категории «итальянской кухни» (italian). Наличие такой информации упрощает дальнейшую группировку и обработку данных.
Ссылки на сущности
Концепция сущности (entity) упрощает сопровождение документа, обеспечивая возможность ссылки на некоторое содержание по ключевым словам. Ключевое слово может относиться как к простейшему фрагменту вроде расширения аббревиатуры, так и к совершенно новому фрагменту кода XML. Сущности удобны тем, что они могут многократно использоваться в документах XML. При последующей обработке документа все ссылки на сущность заменяются конкретным содержанием, указанным при объявлении сущности. Объявление сущности включается в DTD документа XML.
Чтобы сослаться на некоторую сущность в документе HTML, следует указать ее имя с префиксом «амперсанд» (&) и суффиксом «точка с запятой» (;). Допустим, вы объявили сущность с информацией об авторских правах. После этого на данную сущность можно ссылаться следующим образом:
&Соруright:
При этом строка документа XML может выглядеть так:
<footer>
...прочие данные колонтитула...
&Copyright:
</footer>
Сущности, как и переменные и шаблоны, часто применяются в ситуациях, когда некоторая информация может измениться в будущем или документ содержит множество повторяющихся ссылок. Мы вернемся к проблемам объявления ссылок в разделе «Определение типа документа (DTD)».
Инструкции по обработке
Инструкции по обработке
( processing instructions, PI) представляют собой внешние команды, которые выполняются приложением, работающим с документом XML.
В общем случае синтаксис PI выглядит так:
<?приложение инструкции?>
Атрибут приложение указывает, какой программе адресованы последующие инструкции. Например, для выполнения команды РНР в документе XML можно воспользоваться следующей конструкцией:
<?php print "Today's date is:".date("m-d-Y");?>
Инструкции по обработке удобны тем, что они позволяют нескольким приложениям совместно работать с одним документом.
Комментарии
Комментарии принадлежат к числу основных возможностей любого языка. В XML используется тот же синтаксис комментариев, что и в HTML:
<!-комментарии ->
Итак, мы проанализировали структуру типичного документа XML. Но у документов XML существует еще один важный аспект — определение типа документа (DTD).
Динамическое создание временных окон
В JavaScript предусмотрены простые и удобные средства для работы с окнами браузера. В частности, JavaScript позволяет отображать временные окна с вспомогательной информацией, не оправдывающей создания и загрузки отдельной страницы. Напрашивается очевидная идея — построить универсальный шаблон, который будет использоваться для всех временных окон. Все, что для этого потребуется, — РНР. В листинге 15.4 показано, как файл РНР window.php вызывается из JavaScript. В этом файле реализован очень простой шаблон с директивой INCLUDE для включения файла, идентификатор которого передается window.php при вызове из JavaScript.
Для читателей, не имеющих опыта программирования на JavaScript, я включил в программу подробные комментарии. Значение переменной winld, передаваемой сценарию РНР window.php, задается внутри ссылки в основном коде HTML. Когда пользователь щелкает на ссылке, вызывается функция newWindow( ), определенная в JavaScript. Чтобы вы лучше поняли, как это происходит, рассмотрим следующую ссылку:
Как видите, я просто включаю в href значение "#", поскольку ссылка генерируется обработчиком события onClick в JavaScript. Установка обработчика приводит к тому, что при щелчке на ссылке вызывается функция newWindow( ). Обратите внимание на параметр, передаваемый при вызове этой функции (в приведенном примере — 1). Содержащийся в нем идентификатор используется сценарием РНР для выбора отображаемой информации. Вы можете передать любое число — при условии, что оно соответствует имени файла, отображаемого в сценарии РНР. Внимательно просмотрите листинг 15.4. Чтобы вам было легче ориентироваться, я создал три простых файла *.inc, соответствующих ссылкам в этом листинге.
Листинг 15.4.
Динамическое построение временных окон
<html>
<head>
<title>Listing 15-4</title>
<SCRIPT language="Javascript">
// Объявить переменную Javascript
var popWindow;
// Объявить функцию newWindow
function newWindow(winID)
{
// Объявить переменную winURL. Присвоить ей
// имя файла РНР с последующими данными.
var winURL = "Listingl5-5.php?winID=" + winID;
// Если временное окно не существует или закрыто.
// открыть его.
if (! popWindow | popWindow.closed) {
// Открыть новое окно шириной 200 пикселов и высотой
// 300 пикселов, расположенное на расстоянии 150 пикселов
Когда пользователь щелкает на одной из ссылок в листинге 15.4, программа создает временное окно и загружает в него содержимое, полученное в результате вызова window.php. Сценарию window.php передается переменная winID, по которой определяется файл, включаемый в сценарий РНР. Сценарий window.php приведен в листинге 15.5.
Остается лишь создать файлы для ссылок в листинге 15.4. Поскольку в ссылках передаются три уникальных идентификатора (1, 2 и 3), мы должны создать три файла. Первый файл, содержащий контактную информацию, сохраняется с именем Line:
Следующий файл (местонахождение) сохраняется с именем 2.inс.
<table>
<tr>
<td>
<h4>Driving Directions</h4>
<ol>
<li>Turn left on 1st avenue.
<li>Enter the old Grant building.
<li>Take elevator to 4th floor.
<li>We're in room 444.
</td>
</tr>
</table>
Последний файл (сводка погоды) сохраняется с именем 3.inc. Обратите внимание на вызов функции РНР, возвращающей текущую дату, — этот пример наглядно показывает, как легко РНР интегрируется с JavaScript: ,
<table>
<tr>
<td>
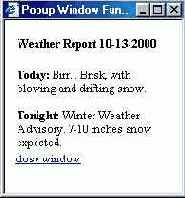
<h4>Weather Report <?=date("m-d-Y");?></h4>
<b>Today:</b> Birr... Brisk, with blowing and drifting snow.<br><br>
На рис. 15.1 показано, как выглядит временное окно, открываемое по третьей ссылке.
Рис. 15.1.
Сводка погоды во временном окне
Наше короткое знакомство с интеграцией PHP/JavaScript подходит к концу. Мы рассмотрели несколько простых, но вполне реальных примеров, которые при желании легко адаптируются для более сложных целей. При объединении РНР с JavaScript или любой другой технологией, ориентированной на работу на стороне сервера, необходимо правильно определить возможности браузера, чтобы предотвратить случайные ошибки. Всегда полезно поэкспериментировать с другими технологиями, интегрируемыми с кодом РНР; только проследите за тем, чтобы не отпугнуть пользователей от сайта недоступными возможностями или содержанием, которое невозможно просмотреть.
Следующий раздел посвящен СОМ — еще одной технологии, с которой легко работать средствами РНР.
Дополнительная информация
Ниже перечислены ссылки на некоторые полезные ресурсы, посвященные СОМ и найденные мной в Интернете:
Как неоднократно упоминалось в книге, одной из самых замечательных особенностей РНР является простота его интеграции с другими технологиями. Примеры такой интеграции уже встречались при описании работы с базами данных, ODBC и XML. В этой главе будет показано, как просто организуется работа РНР в комбинации с JavaScript и приложениями на базе СОМ. Ниже приводятся общие сведения о JavaScript и СОМ, подкрепленные примерами их использования в РНР. К концу главы вы узнаете немало полезного об этих замечательных технологиях и о том, как они применяются в РНР.
в очередной раз показала, как
Эта глава в очередной раз показала, как легко РНР интегрируется с внешними технологиями — а именно, JavaScript и COM (Component Object Model). В частности, были рассмотрены следующие темы:
общие сведения о JavaScript;
проверка поддержки JavaScript в браузерах;
получение информации о возможностях браузера;
использование временных окон в сочетании с РНР;
общие сведения о технологии СОМ;
стандартные средства РНР для работы с СОМ;
использование поддержки СОМ в РНР для передачи информации из базы данных в Microsoft Word.
Интеграция этих технологий с РНР способна расширить функциональные возможности ваших приложений по нескольким направлениям. JavaScript позволяет выполнять на стороне клиента различные операции с окном и браузером, а также производит проверку данных при заполнении форм. При помощи СОМ можно создавать программы, напрямую работающие с многими распространенными приложениями (например, из семейства Office), благодаря чему ваши программы становятся более удобными и обретают новые возможности. Последняя глава посвящена теме, постоянно занимающей умы многих программистов и администраторов, — безопасности. В этой главе будут представлены ключевые проблемы из области безопасности — защита сценариев, шифрование и коммерческие средства проверки данных.
JavaScript
Сценарный язык JavaScript обладает чрезвычайно богатыми возможностями для разработки Интернет-приложений, работающих как на клиентской, так и на серверной стороне. У этого языка есть немало интересных особенностей, и одна из них — возможность обработки не только данных, но и событий. Событие определяется как некоторое действие, выполненное в контексте браузера, — например, щелчок мышью или загрузка страницы.
Любой программист с опытом работы на РНР, Pascal или C++ освоит JavaScript без особого труда. Если вы не программировали на этих языках, не огорчайтесь — JavaScript изучается легко. Разработчики JavaScript (как, впрочем, и разработчики РНР) в первую очередь ориентировались на решение реальных, практических задач.
Если вы хотите воспользоваться средствами обработки,событий JavaScript, сохранив при этом многочисленные преимущества РНР, могу вас обрадовать — РНР интегрируется с JavaScript так же легко, как и с HTML. В сущности, JavaScript неплохо дополняет РНР — на нем удобно делать то, что неудобно делать в РНР, и наоборот.
Но прежде чем интегрировать РНР с JavaScript, следует учесть, что некоторые пользователи отключают поддержку JavaScript в своих браузерах или работают в браузерах, вообще не поддерживающих JavaScript (представьте, такое тоже бывает!). В РНР предусмотрены простые средства для распознавания таких ситуаций.
Поддержка СОМ в РНР
Стандартные функции РНР, предназначенные для работы с СОМ, создают объекты СОМ и используют их свойства и методы. Пожалуйста, не забывайте о том, что эта поддержка присутствует только в версии РНР для Windows. Следующие примеры были протестированы для Microsoft Word 2000. За информацией об объектах, методах и событиях, используемых в программе, обращайтесь на web-сайт MSDN (http://msdn.microsoft.com/library/officedev/off2000/ wotocobjectmodelapplication.htm).
Создание экземпляров объектов СОМ
Экземпляры объектов СОМ создаются вызовом new, как при обычном объектно-ориентированном программировании. Синтаксис:
object new СОМ("обьекг.класс" [, string удаленный_адрес])
Параметр объект.класс определяет модуль СОМ, присутствующий на сервере. Необязательный параметр удаленный_адрес используется в том случае, если объект СОМ создается на удаленном компьютере. Допустим, вы хотите создать экземпляр объекта для приложения MS Word. При этом приложение Microsoft Word запускается так, словно вы запустили его вручную (разумеется, для этого MS Word должен быть установлен на компьютере). Команда имеет следующий синтаксис:
$word=new COM("word.application") or die("Couldn't start Word!");
После того как экземпляр объекта СОМ будет создан, можно приступать к работе с различными методами и свойствами этого объекта. Допустим, вы захотели активизировать окно Word. Следующая команда изменяет атрибут видимости объекта, в результате чего графический интерфейс приложения отображается на экране:
$word->visible = 1:
He огорчайтесь, если эта команда выглядит непонятной. Вызов методов объектов СОМ рассматривается в следующем разделе.
Вызов методов объекта СОМ
Методы объектов СОМ вызываются в типичном для ООП формате, с использованием ссылки из объектной переменной. Синтаксис:
объект->имя_метода([значение, ...])
Объект соответствует экземпляру объекта СОМ, созданному описанным выше способом. Параметр имя_метода определяет имя метода, определенного в классе объект. Необязательный параметр значение позволяет передавать параметры при вызове методов, допускающих (или требующих) дополнительных данных. Как и при вызове обычных функций, параметры разделяются запятыми. Если после создания экземпляра объекта СОМ, представляющего MS Word, вы захотите создать в приложении новый документ, просто вызовите соответствующий метод. Задача решается методом add( ) субкласса Documents экземпляра $word:
$word->Documents->Add( );
Обратите внимание: для вызова методов используется очень логичный синтаксис в стиле ООП. В результате выполнения этой команды в окне приложения MS Word открывается новый документ.
com_get( )
Функция com_get( ) возвращает значение свойства объектов СОМ. Синтаксис:
mixed com_get(resource объект, string свойство)
Первый параметр определяет экземпляр объекта СОМ, а второй — атрибут класса, к которому относится данный экземпляр.
<?
// Создать экземпляр объекта для приложения MS Word
$word=new COM("word.application") or die("Couldn't start Word!");
// Режим CapsLock либо включен (свойство CapsLock = 0),
// либо выключен (свойство CapsLock = 1).
$flag = com_get(Sword->Application.CapsLock)
// Преобразовать значение Sflag (0 или 1) в логическое значение
if ($flag == 1) :
$flag = "YES";
else :
$flag = "NO";
endif;
// Вывести сообщение
print "CAPS Lock activated: $flag";
$word->Quit();
?>
Существует и другое решение — значение атрибута CapsLock можно получить при помощи стандартного для ООП синтаксиса обращения к атрибутам. В предыдущем примере для этого следует заменить строку
$flag = com_get($word->Application,CapsLock)
следующей строкой:
$flag = $word->Application->CapsLock:
Атрибуты объекта позволяют получать разнообразную информацию о характеристиках приложения. Более того, многим атрибутам можно присваивать новые значения. Это делается при помощи функции com_set( ).
com_set( )
Функция com_set( ) присваивает атрибуту объекта новое значение:
Первый параметр определяет экземпляр объекта СОМ, а второй — атрибут класса, к которому относится данный экземпляр. Третий параметр определяет новое значение свойства.
Следующая программа (листинг 15.6) запускает Microsoft Word и активизирует окно приложения. Затем она создает новый документ, добавляет в него строку текста и выбирает режим сохранения документа (атрибут DefaultSaveFormat) в текстовом формате. Результат виден при открытии окна Сохранить как (Save As) — в списке Тип файла (Save As Type) автоматически выбирается строка Только текст (Text Only). После сохранения документа приложение Microsoft Word закрывается.
Листинг 15.6.
Выбор типа документа по умолчанию
<?
// Создать экземпляр объекта для приложения MS Word
$word-new COMC'word.application") or die("Couldn't start Word!");
// Активизировать окно MS Word $word->visible = 1;
// Создать новый документ $word->Documents->Add();
// Вставить в документ фрагмент текста
$word->Selection->Typetext("php's com functionality is cool\n");
// Запросить у пользователя имя и сохранить документ.
// Обратите внимание: по умолчанию документ сохраняется
// в текстовом формате! $word->Documents[l]->Save;
// Выйти из MS Word
$word->Quit();
?>
Существует и другое решение — новое значение атрибута DefaultSaveFormat можно присвоить непосредственно, как обычной переменной. В листинге 15.6 для этого следует заменить строку
Итак, вы получили общее представление об управлении приложениями Windows через поддержку СОМ в РНР. Мы переходим к занимательному примеру, кото-
рый наглядно показывает, каких полезных и впечатляющих результатов можно добиться при помощи СОМ.
Проверка поддержки JavaScript
Правильное определение возможностей браузера избавит пользователей от неприятностей при посещении вашего сайта. Ничто так не действует на нервы, как град раздражающих сообщений «JavaScript Error» или недоступность каких-то средств сайта из-за того, что использованные вами технологии не поддерживаются браузером. К счастью, в РНР предусмотрено простое средство для проверки возможностей браузера — стандартная функция get_browser( ).
get_browser( )
Функция get_browser( ) возвращает информацию о возможностях браузера в виде объекта. Синтаксис:
object get_browser([string агент])
Необязательный параметр агент используется для получения характеристик конкретного браузера. Как правило, функция get_browser( ) вызывается без параметров, поскольку по умолчанию она использует глобальную переменную РНР $HTTP_USER_AGENT.
Стандартный список возможностей браузера хранится в файле browcap, путь к которому определяется параметром browcap в файле php.ini. По умолчанию эта строка выглядит следующим образом:
;browcap = extra/browcap.ini
Файл browser.ini был разработан компанией cyScape, Inc. Последняя версия этого файла находится по адресу http://www.cyscape.com/browcap. Загрузите и распакуйте этот файл в каталог на сервере. Запомните имя каталога, оно понадобится вам для обновления параметра browcap в файле php.ini.
В принципе, после загрузки browcap.ini и редактирования файла php.ini вы можете включать в свои программы проверку возможностей браузера. Впрочем, я рекомендую сначала открыть файл browser.ini и ознакомиться с его структурой, а затем просмотреть листинги 15.1 и 15.2. В листинге 15.1 приведен очень простой пример отображения всех возможностей браузера в самом браузере. Листинг 15.2 ограничивается лишь одной возможностью — поддержкой JavaScript.
Листинг
15.1. Отображение всех атрибутов браузера
<?
// Получить информацию о браузере
$browser = get_browser();
// Преобразовать $browser в массив
Sbrowser = (array) Sbrowser;
while (list ($key, $value) = each ($browser)) :
// Присвоить нули пустым элементам массива
if ($value == "") : $value = 0;
endif;
print "$key : $value <br>";
endwhile;
?>
Для браузера Microsoft Internet Explorer 5.0 листинг 15.1 выводит следующий результат:
В листинге 15.2 приведен простой, но эффективный сценарий, который при помощи файла browcap.ini определяет, включена ли поддержка JavaScript в браузере.
Листинг 15.2.
Проверка поддержки JavaScript
<?
$browser = get_browser( );
// Преобразовать $browser в массив $browser = (array) $browser;
if ($browser["javascript"] == 1) :
print "Javascript enabled!";
else :
print "No javascript allowed!";
endif;
?>
Листинг 15.2 проверяет, присутствует ли ключ javascript для заданного браузера. Если ключ присутствует и равен 1, в браузере выводится сообщение о поддержке JavaScript. В противном случае выводится сообщение об ошибке. Конечно, в реальной программе вместо выдачи сообщения следует выполнить какие-нибудь полезные действия.
Следующие два примера показывают, как легко РНР,интегрируется с JavaScript. Листинг 15.3 определяет параметры экрана (разрешение и цветовую глубину) средствами JavaScript и затем выводит их средствами РНР. Листинг 15.4 (см. следующий раздел) показывает, как при помощи шаблона РНР во временном (pop-up) окне, вызванном из кода JavaScript, выводится информация о ссылке, на которой щелкнул пользователь.
echo "<b>Screen Resolution:</b> $screenWidth x $screenHeight pixels.<br>";
if ($browserWidth != 0) :
echo "<b>Browser resolution:</b> $browserWidth x $browserHeight pixels.";
else :
echo " No javascript browser resolution support for Internet Explorer";
endif;
?>
</body>
</html>
СОМ
Технология СОМ (сокращение от «Component Object Model», то есть «модель составного объекта») обеспечивает взаимодействие между приложениями, работающими на разных языках и платформах. Такое взаимодействие в значительной мере способствует идее построения многократно используемых, легко сопровождаемых и адаптируемых программных компонентов (в последнее время к этим трем принципам проявляется повышенное внимание в области компьютерных технологий). Хотя СОМ обычно рассматривается как спецификация, ориентированная в первую очередь на продукты Microsoft, поддержка СОМ уже реализована во многих языках (например, в РНР, Java, C++ и Delphi) и существует на многих платформах, включая Windows, Linux и Macintosh.
Что же вам даст объединение СОМ с РНР? Во-первых, средства СОМ позволяют напрямую взаимодействовать со многими приложениями Microsoft. Ниже рассмотрен интересный пример — форматирование и вывод в Microsoft Word записей базы данных, полученных из Web. В следующем разделе вы увидите, как легко решается эта задача.
На нескольких страницах, посвященных технологии СОМ, эту огромную тему нельзя осветить даже поверхностно. Ситуация осложняется тем, что возможности использования СОМ в языке РНР почти не документируются. За дополнительной информацией о механизме работы СОМ обращайтесь к ресурсам, перечисленным в конце этой главы.
РНР содержит несколько стандартных функций для работы с СОМ. Учтите, эти функции поддерживаются только в версии РНР для Windows! Прежде чем переходить к примерам, мы рассмотрим все эти функции.
Запись информации в документ Microsoft Word
Допустим, вам потребовалось отформатировать информацию, загруженную из базы данных, в документе Word для построения отчета. Весь процесс автоматизируется всего в нескольких строках кода РНР. Для демонстрационных целей я воспользуюсь таблицей addressbook из проекта адресной книги, приведенного в конце главы 12. Алгоритм работы сценария выглядит следующим образом:
Подключиться к серверу MySQL и выбрать нужную базу данных.
Выбрать все данные из таблицы с сортировкой по фамилиям.
Открыть приложение Microsoft Word и создать новый документ.
Отформатировать и вывести все записи в документе.
Запросить у пользователя имя для сохранения документа.
Закрыть Microsoft Word.
Программный код приведен в листинге 15.7.
Листинг 15.7.
Запись информации в документ Microsoft Word <?
<?
// Создать соединение с сервером MySQL
$host = "localhost";
$user = "root";
$pswd = "";
$db = "book";
$address_table = "addressbook";
mysql_connect($host. $user, $pswd)
or die("Couldn't connect to MySQL server!");
mysql_select_db($db) or die("Couldn't select database!");
// Выбрать из базы данных все записи
$query = "SELECT * FROM $address_table ORDER BY lastjiame";
Sresult = mysql_query($query):
// Создать новый объект COM для приложения MS Word
$word=new COM("word.application") or die("Couldn't start Word!");
// Активизировать окно MS Word $word->visible = 1;
При всей простоте рассмотренный пример наглядно показывает, как писать приложения РНР для пересылки содержимого базы данных в приложения Windows. Можно написать и более сложное приложение, обеспечивающее синхронизацию данных, полученных из Web, из Microsoft Outlook. Все, что для этого нужно — получить ссылку на объекты, свойства и методы Outlook, после чего можно переходить к экспериментам (обзор объектной модели всех приложений семейства Office приведен по адресу http://www.microsoft.com/officedev/articles/Opg/toc/PGTOC.htm).
Аутентификация пользователя
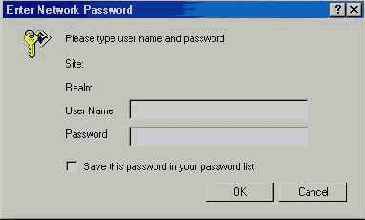
Правильно введенные имя и пароль открывают пользователю доступ к каталогам сервера, недоступным для анонимного доступа. Этот принцип аутентификации обычно называется схемой «запрос/ответ» (challenge/response). Запросом является приглашение к вводу имени и пароля, а ответом — введенные данные. Если введенная комбинация верна, пользователю предоставляется доступ к защищенным каталогам; в противном случае попытка получения доступа отклоняется с выводом соответствующего сообщения.
Как правило, для ввода имени и пароля применяются диалоговые окна, активизируемые вызовом функции header( ) (листинг 16.2).
Листинг 16.2.
Запрос данных для аутентификации пользователя <?
<?
header( 'WWW-Authenticate: Basic realm="Secret Family Recipes"');
header ('HTTP/1.0 401 Unauthorized');
exit;
?>
Выполнение фрагмента из листинга 16.2 всего лишь активизирует окно для ввода данных. Примерный вид этого окна изображен на рис. 16.1.
Рис. 16.1.
Окно аутентификации пользователя
Следующим шагом после подготовки интерфейса для ввода является обработка имени пользователя и пароля. В РНР имя и пароль хранятся в двух глобальных переменных, $PHP_AUTH_USER (имя) и $PHP_AUTH_PW (пароль). В листинге 16.3 показано, как проверяются значения этих переменных. Если данные не были введены, окно аутентификации отображается заново.
Экспериментируя со сценариями этого раздела, вы увидите, что окно аутентификации не всегда появляется после обновления страницы. Проблема кроется не в программе, а в том, как окна аутентификации реализованы в браузере. Чтобы вызвать окно, вам придется закрыть и перезапустить браузер.
Листинг 16.3.
Проверка глобальных переменных аутентификации в РНР
<?
If ( (! isset ($PHP_AUTH_USER)) || (! isset ($PHP_AUTH_PW)) ):
headert 'WWW-Authenticate: Basic realm="Secret Family Recipes'");
header(''HTTP/1.0 401 Unauthorized');
print "You are attempting to enter a restricted area. Authorization is required.";
exit;
endif;
?>
В простейшей, но недостаточно гибкой схеме ограничения доступа к странице имя пользователя и пароль жестко кодируются в сценарии. В листинге 16.4 приведен вариант предыдущего примера, построенный с использованием этой схемы.
header('WWW-Authenticate: Basic realm="Secret Family Recipes'"); header('HTTP/1.0 401 Unauthorized');
print "You are attempting to enter a restricted area. Authorization is required,
exit;
endif;
?>
Аутентификация с несколькими пользователями
Хотя вариант, приведенный в листинге 16.4, неплохо подходит для небольших статических групп пользователей, для ограничения доступа к некоторым областям web-сайта обычно выбираются более гибкие и надежные решения. Вероятно, вы предпочтете создать отдельные имя и пароль для каждого пользователя, которому предоставляется расширенный доступ. Существует несколько реализаций этой схемы, из которых чаще всего встречается чтение аутентификационных данных из текстового файла или базы данных.
Хранение информации в текстовом файле
Существует очень простое, но эффективное решение — хранить аутентификацион-ные данные в текстовом файле. В каждой строке файла содержится отдельная пара «имя:пароль»; в,процессе проверки программа последовательно читает и проверяет все строки файла. Примерный вид текстового файла приведен в листинге 16.5.
Листинг 16.5.
Типичный текстовый файл с параметрами аутентификации (authenticate.txt)
brian:snaidni00
alessia:aiggaips
gary:9avaj9
chris:poghsawcd
matt:tsoptaes
Как видно из листинга, каждая строка приведенного файла состоит из имени пользователя и пароля, разделенных двоеточием (:). Таким образом, при использовании этого файла существует пять комбинаций «имя/пароль», обеспечивающих доступ к ограниченным ресурсам. Каждый раз, когда пользователь вводит имя и пароль в окне, сценарий открывает текстовый файл и последовательно ищет в нем совпадающую пару. Если совпадение находится, запрашиваемый доступ пользователю предоставляется, а если нет — запрос отклоняется. Процедура аутентификации продемонстрирована в листинге 16.6.
Листинг 16.6.
Аутентификация на основе текстового файла <?
<?
$file = "Listing16-5.txt":
$fp = fopen($file, "r"):
$auth_file = fread ($fp, filesize($fp)):
fclose($fp);
$authorized = 0;
// Сохранить строки файла в виде элементов массива
$elements = explode ("\n", $auth_file);
foreach ($elements as $element) {
list ($user, $pw) = split (":", $element);
if (($user == $PHP_AUTH_U$ER) && ($pw = $PHP_AUTH_PW)) :
Листинг 16.7.
Аутентификация пользователя посредством поиска в базе данных
<?
if (!isset($PHP_AUTH_USER)) :
header( 'WWW-Authenticate: Basic realm="Secret Family Recipes'");
header('HTTP/1.0 401 Unauthorized');
exit;
else :
// Создать содинение с базой данных MySQL
mysql_connect ("host", "user", "password")
or die ("Can't connect to database!");
mysql_select_db ("useMnfo")
or die ("Can't select database!");
// Обратиться к таблице user_authenticate
// для поиска совпадающей строки
$query = "select userid from user_authenticate where
username = '$PHP_AUTH_USER' and
password = '$PHP_AUTH_PW'";
$result = mysql_query (Squery):
// Если совпадение не найдено, вывести окно аутентификации
if (mysql_numrows($result) != 1) :
header('WWW-Authenticate: Basic realm="Secret Family Recipes'");
header ('HTTP/ 1.0 401 Unauthorized');
exit;
// Если проверка пройдена, получить идентификатор пользователя
Даже после того, как вы обеспечили надежную конфигурацию сервера, необходимо постоянно помнить о потенциальной угрозе для системы безопасности, исходящей из программного кода РНР. Не подумайте, что язык РНР недостаточно надежен — теоретическую брешь в системе безопасности можно создать на любом языке программирования. Тем не менее, учитывая широкое распространение РНР для программирования в распределенных средах с большим количеством пользователей (то есть в Web), вероятность попыток «взлома» ваших программ со стороны пользователей существенно возрастает. Вы должны сами позаботиться о том, чтобы этого не произошло.
Безопасный режим и работа РНР в режиме модуля Apache
Следует помнить, что при работе РНР в режиме модуля Apache безопасный режим недоступен. Это объясняется тем, что модуль РНР работает в составе сервера Apache, поэтому все сценарии РНР работают под тем же UID, что и сам сервер Apache. Поскольку ограничения вызова функций в безопасном режиме основаны на сравнении UID, этот режим полноценно работает только при использовании CGI-версии РНР в сочетании с suExec (http://www.apache.org/docs/ suexec.html). Дело в том, что CGI-версия РНР работает как отдельный процесс, что позволяет динамически изменять UID средствами suExec. Если вас интересует использование РНР в безопасном режиме, вероятно, вам следует остановить свой выбор на комбинации CGI/suExec, хотя за это приходится расплачиваться быстродействием.
Другой важный аспект конфигурации — запрет на просмотр некоторых файлов в браузере. Конечно, секретные пароли или другие конфигурационные данные должны оставаться недоступными для внешних пользователей. Эта тема рассматривается в следующем разделе.
CCVS
Технология CCVS (Credit Card Verification System) была разработана RedHat (http://www.redhat.com) для независимой обработки сделок по кредитным картам. Она позволяет напрямую обращаться к агентствам кредитных карт вместо того, чтобы пользоваться услугами третьих сторон (например, Cybercash). Технология CCVS совместима со многими платформами Linux/UNIX и легко адаптируется, поскольку RedHat предоставляет исходные тексты.
Для использования средств CCVS РНР необходимо откомпилировать с ключом
-with-ccvs[-DIR].
За дополнительной информацией о CCVS обращайтесь по адресам:
Компания Cybercash, Inc. (http://www.cybercash.com) предлагает разнообразные услуги по проверке кредитных карт и проведению сделок, а также программное обеспечение для тех, кто желает использовать эти услуги в своих web-приложениях.
Сценарии, написанные на Perl, могут взаимодействовать со службой проведения сделок Cybercash. Учитывая это обстоятельство, пользователи РНР обычно интегрируют Cybercash со своими сайтами одним из следующих способов:
Используя библиотеку cyberlib.php, включенную в поставку РНР. Этот вариант предоставляет в ваше распоряжение все необходимое для проведения транзакций (рекомендуется).
Взаимодействуя со службой Cybercash при помощи готовых сценариев Perl и С и вызывая их из сценариев РНР (рекомендуется).
Переписывая готовые сценарии Perl и С на РНР (не рекомендуется).
Для использования средств Cybercash РНР необходимо откомпилировать с ключом -with-cybercash[=DIR].
Как и в случае с Verisign, помните, что включение поддержки Cybercash при компиляции РНР еще не означает, что вы можете пользоваться этой службой! Услуги Cybercash не бесплатны и могут обойтись довольно дорого (подключение к службе Cybercash Commerce Cash Register в настоящее время стоит $495, ежемесячная оплата составляет $20, а каждая сделка стоит $0,20). Тем не менее, невзирая на все расходы, многие разработчики РНР считают, что Cybercash является одним из лучших решений.
Прежде чем оплачивать услуги Cybercash, вы можете протестировать свой сценарий при помощи тестового входа (эту услугу Cybercash предлагает бесплатно). Бесплатное тестирование сценариев избавит вас от лишних расходов в процессе отладки программ. Дополнительную информацию можно получить на сайте Cybercash.
Ресурсы Интернета, посвященные Cybercash:
http://www.cybercash.com;
http://www.php.net/manual/ref.cybercash.php.
Disable_functions
В этом параметре через запятую перечисляются имена функций, выполнение которых требуется запретить. Обратите внимание — этот параметр никак не связан с safe_mode. Например, чтобы запретить вызовы функций fopen( ), popen( ) и file( ), достаточно включить в конфигурационный файл следующую строку:
disable_functions = fopen, popen.file
Doc_root
Параметру присваивается путь к корневому каталогу для файлов РНР. Если значение doc_root представляет собой пустую строку, оно игнорируется и сценарии РНР выполняются в полном соответствии с URL. Если безопасный режим включен, а параметр doc_root содержит непустое значение, то сценарии РНР за пределами этого каталога выполняться не будут.
Дополнительная информация
В этом разделе описаны лишь те средства, которые в той или иной степени интегрируются в РНР. Впрочем, этим ваши возможности не ограничиваются. Помните о том, что при помощи функций рореn( ) или ехес( ) можно работать с любыми технологиями шифрования, разработанными независимыми фирмами, — например, PGP (http://www.pgpi.org) или GPG (http://www.gnupg.org).
Ниже перечислены некоторые ресурсы Интернета, посвященные криптографии и информационной безопасности:
В завершение этого раздела я хочу лишний раз напомнить об осторожности. Прежде чем включать поддержку шифрования данных в критические приложения, потратьте немного времени на изучение механики шифрования. В мире безопасности данных неведение всегда приводит к печальным результатам. Если вы слабо разбираетесь в этой теме, обязательно ознакомьтесь с приведенными ссылками — они дают превосходное представление о многих аспектах шифрования и безопасности данных.
PHP 4 на практике
Безопасность
Non sum qualis eram
(Я не такой, каким был раньше).
Гораций
Когда-то, наткнувшись на эту цитату из Горация, я подумал, что она очень точно отражает суть сетевой безопасности, и сохранил ее где-то в недрах своего жесткого диска на будущее.
Конечно, читатель недоумевает — какое отношение древнеримский поэт Гораций имеет к сетевой безопасности? Безопасность — одна из тем, порождающих нескончаемый поток информации и вечно меняющихся в соответствии с новыми технологическими веяниями. Короче говоря, она в любой момент «не такая, какой была раньше». Вы никогда не можете полагаться на свои познания в этой области, поскольку в момент выхода на широкий рынок любая технология либо устаревает, либо обречена на устаревание в ближайшем будущем. Чтобы добиться относительной безопасности при построении серверных приложений, вам придется постоянно следить за последними достижениями в этой области или нанять кого-нибудь, кто это будет делать за вас.
Применительно к РНР тема безопасности выглядит многогранной, причем некоторые ее аспекты связаны с безопасностью самого сервера. Ведь безопасность сервера во многих отношениях определяет безопасность данных, обрабатываемых сценариям РНР. Я настоятельно рекомендую собрать как можно больше информации о вашем web-сервере и постоянно следить за всеми обновлениями и исправлениями. Вероятно, большинство читателей работает с сервером Apache, поэтому я советую почаще посещать сайт Apache (http://www.apache.org) и замечательный сайт Apache Week (http://www.apacheweek.org). Впрочем, безопасностью сервера дело не ограничивается — РНР также в определенной степени влияет на безопасность системы за счет правильного выбора параметров конфигурации и защищенного программирования.
Последняя глава этой книги состоит из пяти разделов:
Проблемы конфигурации.
Проблемы программирования.
Шифрование данных.
Электронная коммерция.
Аутентификация пользователей.
Хотя ни один из этих разделов не содержит ответов на все вопросы, относящиеся к построению защищенных приложений на базе РНР, по крайней мере, они закладывают основу для дальнейших самостоятельных исследований.
Эта глава была посвящена разнообразным
Эта глава была посвящена разнообразным вопросам, связанным с системой безопасности. Как говорилось ранее, безопасность приложений РНР обеспечивается правильной настройкой web-сервера и РНР в сочетании с приемами защищенного программирования, предотвращающими нарушение работы системы из-за пользовательского ввода. Важная роль в системе безопасности также отводится шифрованию данных, проверке кредитных карт и аутентификации пользователей. В частности, были рассмотрены следующие темы:
проблемы конфигурации РНР;
безопасный режим;
проблемы программирования;
шифрование данных;
технологии электронной коммерции;
аутентификация пользователей.
В завершение я хочу подчеркнуть, что правильное планирование уровня безопасности ваших приложений РНР окажется успешным лишь при столь же (если не более) тщательном планировании других аспектов. Общая структура средств безопасности всегда должна определяться до начала непосредственного программирования. В конечном счете это сэкономит ваше время и поможет ликвидировать потенциальные недочеты в системе безопасности вашего приложения.
Электронная коммерция
Появление электронной коммерции вызвало настоящий ажиотаж во всем мире. Бесспорно, она обладает многочисленными достоинствами и открывает массу новых возможностей. К счастью, читатели, занимающиеся разработкой собственных коммерческих сайтов, могут воспользоваться надежными коммерческими технологиями, легко интегрируемыми в сценарии РНР. В этом разделе кратко описаны самые популярные из этих технологий.
Маскировка файлов данных и конфигурационных файлов
Этот раздел посвящен процедуре, которая играет очень важную роль независимо от используемого языка программирования. На примере сервера Apache я покажу, как легко нарушить вашу систему безопасности, если вы не предпримете необходимых шагов для «маскировки» файлов, не предназначенных для внешних пользователей.
В конфигурационном файле Apache httpd.conf присутствует параметр DocumentRoot. С его помощью устанавливается путь к каталогу, который рассматривается сервером как общедоступный каталог HTML. Считается, что любой файл в этом каталоге может быть передан в пользовательский браузер, даже если расширение этого файла не опознано. Пользователи не могут просматривать файлы, находящиеся за пределами этого каталога. Следовательно, конфигурационные файлы никогда
не следует хранить в каталоге DocumentRoot!
Для примера создайте файл и введите в нем какой-нибудь «секретный» текст. Сохраните этот файл в общедоступном каталоге HTML с именем secrets и каким-нибудь экзотическим расширением типа .zkgjg. Разумеется, сервер не распознает это расширение, но все равно попытается передать запрошенные данные. Теперь запустите браузер и введите URL со ссылкой на этот файл. Интересно, правда? К счастью, у этой проблемы существует два простых решения.
Хранение файлов за пределами корневого каталога документов
В первом варианте вы просто сохраняете все файлы, которые не должны просматриваться пользователями, вне корневого каталога документов и в дальнейшем включаете их в сценарии РНР директивой include( ). Допустим, параметр DocumentRoot настроен следующим образом:
DocumentRoot C:\Program Files\Apache Group\Apache\htdocs # Windows
DocumentRoot /www/apache/home # Другие системы
Предположим, у вас имеется файл с атрибутами доступа (хост, имя пользователя, пароль) к базе данных MySQL. Конечно, этот файл не должен попадаться на глаза посторонним, поэтому вы сохраняете его вне корневого каталога документов. Например, в системе Windows можно воспользоваться каталогом C:/Program FHes/mysecretdata, а в UNIX — каталогом /usr/local/mysecretdata.
Чтобы воспользоваться атрибутами доступа в сценарии, достаточно включить эти файлы с указанием полного пути. Пример для Windows:
Конечно, при отключении безопасного режима (см. предыдущий раздел) это не помешает другим пользователям, которые могут выполнять сценарии РНР, включить этот файл в свои сценарии. Следовательно, в многопользовательской среде эту меру безопасности желательно сочетать с включением безопасного режима.
Настройка файла httpd.conf
Во втором варианте доступ к файлам с конфиденциальной информацией ограничивается по расширению файла, при этом используется параметр FILES файла httpd.conf. Допустим, вы хотите запретить пользователям доступ к файлам с расширением .inc. Для этого достаточно включить в файл httpd.conf следующий фрагмент:
<Files *.inc>
Order allow, deny
Deny from all
</Files>
После редактирования файла перезапустите сервер Apache, после этого все попытки запросить любой файл с расширением .inc в браузере отклоняются сервером. Впрочем, эти файлы все равно могут включаться в сценарии РНР. Кстати говоря, при просмотре файла httpd.conf вы увидите, что этот способ применяется для ограничения доступа к файлам .htaccess. Эти файлы используются для парольной защиты каталогов и рассматриваются в конце главы.
Max_execution_time
Параметр указывает максимальную продолжительность выполнения сценария (в секундах). По истечении указанного срока сценарий автоматически завершается, что помогает бороться с чрезмерными затратами процессорного времени на выполнение пользовательских сценариев. По умолчанию параметр равен 30 секундам. Если присвоить ему 0, время выполнения сценариев не ограничивается.
Memory_limit
Параметр определяет максимальный объем памяти (в байтах), используемой сценарием. По умолчанию параметр равен 8 Мбайт (8 388 608 байт).
Обработка пользовательского ввода
Хотя обработка данных, введенных пользователем, является важной частью практически любого нормального приложения, необходимо постоянно помнить о возможности передачи неправильных данных (злонамеренной или случайной). В web-приложениях эта опасность выражена еще сильнее, поскольку пользователи могут выполнять системные команды при помощи таких функций, как system( ) или ехес( ).
Простейший способ борьбы с потенциально опасным пользовательским вводом — обработка полученных данных стандартной функцией escapeshellcmd( ).
escapeshellcmd( )
Функция escapeshellcmd( ) экранирует все сомнительные символы в строке, которые могут привести к выполнению потенциально опасной системной команды:
string escapeshellcmd(string команда)
Чтобы вы лучше представили, к каким последствиям может привести бездумное использование полученных данных, представьте, что вы предоставили пользователям возможность выполнения системных команд — например, `ls -l`. Но если пользователь введет команду `rm -rf *` и вы используете ее для эхо-вывода или вставите в вызов ехес( ) или system( ), это приведет к рекурсивному удалению файлов и каталогов на сервере! Проблемы можно решить предварительной «очисткой» команды при помощи функции escapeshel lcmd( ). В примере `rm -rf *` после предварительной обработки функцией escapeshellcmd( ) строка превращается в \ `rm -rf *\`.
Обратные апострофы (backticks) представляют собой оператор РНР, который пытается выполнить строку, заключенную между апострофами. Результаты выполнения направляются прямо на экран или присваиваются переменной.
При обработке пользовательского ввода возникает и другая проблема — возможное внедрение тегов HTML. Особенно серьезные проблемы возникают при отображении введенной информации в браузере (как, например, на форуме). Присутствие тегов HTML в отображаемом сообщении может нарушить структуру страницы, исказить ее внешний вид или вообще помешать загрузке. Проблема решается обработкой пользовательского ввода функцией strip_tags( ).
strip_tags( )
Функция strip_tags( ) удаляет из строки все теги HTML. Синтаксис:
Первый параметр определяет строку, из которой удаляются теги, а второй необязательный параметр определяет теги, остающиеся в строке. Например, теги курсивного начертания (<1 >...</ 1>) не причинят особого вреда, но лишние табличные теги (например, <td>...</td>) вызовут настоящий хаос. Пример использования функции strip_tags( ):
$input = "I <i>really</i> love РНР!";
$input = strip_tags($input);
// Результат: $input = "I really love PHP!";
На этом завершается краткое знакомство с двумя функциями, часто используемыми при обработке пользовательского ввода. Следующий раздел посвящен шифрованию данных, причем особое внимание, как обычно, уделяется стандартным функциям РНР.
Общие функции шифрования
Шифрование данных в Web имеет смысл только в том случае, если сценарии, в которых используются средства шифрования, работают на защищенном сервере. Почему? Поскольку РНР является сценарным языком, работающим на стороне сервера, перед шифрованием данные должны быть отправлены на сервер в простом текстовом формате. Если данные передаются через незащищенное соединение, существует немало способов перехвата этой информации в процессе ее пересылки от пользователя на сервер. За дополнительными сведениями о защите сервера Apache обращайтесь на сайт http://www.apache-ssl.org. Читателям, работающим с другими web-серверами, следует обращаться к документации. Скорее всего, для этих серверов существует хотя бы одно (а может, и больше) решение области безопасности.
md5( )
Хэширующий алгоритм MD5 используется (в частности) для создания цифровых подписей, позволяющих однозначно идентифицировать отправителя. В РНР для этого алгоритма существует специальная функция
string md5(string строка)
MD5 является алгоритмом «одностороннего» хэширования; это означает, что данные, хэшируемые функцией md5(), восстановить уже невозможно.
Алгоритм MD5 также применяется при проверке паролей. Поскольку теоретически невозможно восстановить исходную строку, обработанную алгоритмом MD5, можно хэшировать пароль функцией md5( ) и затем сравнивать зашифрованный пароль с результатом обработки пароля, введенного пользователем при попытке получения доступа к конфиденциальной информации.
Допустим, у нас имеется некоторый секретный пароль toystore с хэш-кодом 745e2abd7c52eeldd7cl4aeOd71b9d76. Хэшированное значение сохраняется на сервере и сравнивается с хэш-эквивалентом пароля, введенного пользователем. Даже если злоумышленник получит доступ к зашифрованному паролю, это ни на что не повлияет, поскольку он (теоретически) не сможет восстановить по нему оригинал. Пример хэширования строки:
В следующем раздеяе я представлю другой способ шифрования данных, в котором используется одна из стандартных функций РНР.
crypt( )
Функция crypt( ) является удобным средством для одностороннего шифрования данных. Под «односторонним шифрованием» я подразумеваю, что данные могут только шифроваться — алгоритмы для расшифровки данных, обработанных функцией crypt( ), пока неизвестны. Синтаксис:
string cкypt(string строке [, детерминант])
Первый параметр определяет строку, шифруемую функцией crypt( ). Необязательный второй параметр определяет алгоритм, используемый при шифровании. Точнее, тип алгоритма определяется длиной детерминанта. Различные типы алгоритмов и длины их детерминантов перечислены в табл. 16.2.
Таблица 16.2.
Алгоритмы шифрования и длины их детерминантов
Алгоритм
Длина
CRYPT_STD_DES
2
CRYPT_EXT_OES
9
CRYPT_MD5
12
CRYPT BLOWFISH
16
В листинге 16.1 продемонстрировано использование функции crypt( ) для создания и сравнения зашифрованных паролей.
Листинг 16.1.
Применение функции crypt (STD_DES) для хранения и сравнения паролей <?
<?
$user_pass = "123456";
// Выделить первые два символа $user_pass
// и использовать их в качестве детерминанта.
$salt = substr($user_pass. 0, 2);
// Зашифровать и сохранить пароль.
$crypt1 = crypt($user_pass, ;salt);
// $crypt1 = "12tir.zIbWQ3c"
//... пользователь вводит пароль
$entered_pass = "123456";
// Получить первые два символа хранящегося пароля
$salt1 = substr($crypt, 0, 2);
// Зашифровать $entered_pass, используя $saltl в качестве детерминанта.
$crypt2 = crypt($entered_pass, $salt1);
// $crypt2 = "12tir.zIbWQ3c";
// Следовательно. $cryptl = $crypt2
?>
Если вы выбираете между crypt( ) и md5() для шифрования данных на сайте, рекомендую остановиться на md5( ) — эта функция обеспечивает лучшую защиту.
Как видно из листинга 16.1, $crypt совпадает с $crypt2, но только потому, что мы правильно использовали первые два символа $crypt1 в качестве детерминанта для шифрования $entered_pass. Поэкспериментируйте с этим примером, попробуйте использовать различные значения, и вы убедитесь, что $crypt1 совпадает с $crypt2 лишь при использовании этой процедуры.
mhash( )
Функция mhash( ) поддерживает несколько алгоритмов хэширования, которые позволяют разработчикам использовать контрольные суммы и разнообразные цифровые подписи в приложениях РНР. Хэши также используются для хранения паролей. Подключение модуля mhash в РНР выполняется очень просто:
Зайдите на сайт http://mhash.sourceforge.net
и загрузите пакет.
Распакуйте содержимое архива и выполните инструкции, приведенные в документе INSTALL.
Откомпилируйте РНР с ключом -with-mhash.
Как видите, ничего сложного. Впрочем, имеется одно обстоятельство, которое часто вызывает проблемы при компиляции mhash для комбинации РНР/Apache, — многим пользователям приходится конфигурировать mhash следующим образом: " ./configure -disable -pthreads" (вы поймете, о чем идет речь, если прочитаете документ INSTALL). Помните об этом в процессе компиляции.
После завершения установки в вашем распоряжении оказываются все функциональные возможности mhash. Алгоритмы хэширования, поддерживаемые в настоящее время mhash, перечислены в табл. 16.3.
Таблица 16.3.
Алгоритмы хэширования, поддерживаемые mhash( )
SHA1
RIPEMD160
MD5
GOST
TIGER
SNEFRU
HAVAL
CRC32
RIPEMD128
CRC32B
mcrypt( )
Mcrypt — популярный пакет шифрования данных в РНР, обеспечивающий возможность двустороннего шифрования (то есть собственно шифрование и расшифровку данных). Четыре режима шифрования, поддерживаемых модулем mcrypt, перечислены ниже.
CBC
Режим СВС (Cipher Block Chaining) является самым распространенным из всех четырех режимов mcrypt. В отличие от режима ЕСВ (см. ниже), СВС обеспечивает разное шифрование идентичных блоков текста, что затрудняет поиск закономерностей при попытке несанкционированной расшифровки. Если вы не знаете, какой из четырех режимов следует использовать, выбирайте СВС. Впрочем, перед принятием окончательного решения стоит ознакомиться со всеми четырьмя режимами.
СFВ
Режим СFВ (Cipher Feedback) обладает некоторыми характеристиками потоковых шифров, что избавляет от необходимости накопления блоков данных перед шифрованием. Данный режим используется очень редко.
ЕСВ
Режим ЕСВ (Electronic Code Book) шифрует каждый текстовый блок независимым блочным шифром, что несколько снижает его защищенность при шифровании относительно малых блоков обычного текста. Поскольку ЕСВ шифрует два блока простого текста одинаковым шифром, у злоумышленника появляется основа для расшифровки. Следовательно, если у вас нет веских доводов в пользу ЕСВ, вероятно, лучше воспользоваться режимом СВС.
OFB
По многим характеристикам режим OFB (Output Feedback) похож на режим СFВ. Как и СFВ, он используется относительно редко.
Чтобы воспользоваться средствами mcrypt необходимо предварительно принять па-кет по адресу ftp://argeas.cs-net.gr/pub/unix/mcrypt.
Проблемы конфигурации
Сразу же после установки РНР следует уделить внимание некоторым аспектам конфигурации, влияющим на безопасность вашей системы. Конечно, выбор зависит от конкретной ситуации. Например, если программированием на РНР будете заниматься только вы и ваши коллеги, то конфигурация системы безопасности будет выглядеть совсем не так, как если бы программирование сценариев РНР, работающих на сервере, разрешалось всем клиентам. Независимо от ситуации, следует внимательно проанализировать все параметры конфигурации и разрешить только то, что действительно необходимо. Параметры конфигурации РНР определяются в файле php.ini.
Safe_mode
При включении безопасного режима (safe_mode) ограничивается использование некоторых потенциально опасных возможностей РНР. Для включения или выключения безопасного режима параметру safe_mode присваивается значение on или off. Механизм ограничения основан на сравнении идентификатора пользователя (UID) выполняющегося сценария с идентификатором пользователя того файла, к которому этот сценарий пытается обратиться. Если идентификаторы совпадают, функция выполняется; в противном случае попытка завершается неудачей.
Безопасный режим не может использоваться в том случае, если РНР откомпилирован в виде модуля Apache. Дело в том, что при работе РНР в режиме модуля Apache все сценарии РНР работают под тем же идентификатором, что и Apache, что не позволяет различать владельцев разных сценариев. За дополнительной информацией обращайтесь к разделу «Безопасный режим и работа РНР в режиме модуля Apache».
В частности, при включении безопасного режима действуют следующие ограничения:
Функции ввода/вывода (в частности, fopen ( ), filе( ) и include ( )) работают только с файлами, принадлежащими владельцу сценария. Предположим, в безопасном режиме сценарий, принадлежащий пользователю Мэри, вызывает функцию fopen( ). Если функция попытается открыть файл, принадлежащий Джону, ее вызов завершится неудачей. Но если Мэри принадлежит как сценарий, вызывающий fopen( ), так и открываемый файл, все будет нормально.
Запуск внешних сценариев функциями popen( ), system( ) или ехес( ) разрешается лишь в том случае, если запускаемый сценарий находится в каталоге, определяемом параметром safe_mode_exec_dir (см. далее).
Новые файлы создаются только в каталогах, принадлежащих владельцу сценария.
Аутентификация HTTP становится более жесткой, поскольку в ней также учитывается UID аутентифицирующего сценария. Механизм аутентификации пользователей рассматривается в одном из разделов этой главы.
Имя пользователя, использованное при подключении к серверу MySQL, должно совпадать с именем владельца файла, вызывающего mysql_connect( ).
В табл. 16. 1 приведен полный список функций, на которые распространяется безопасный режим.
Таблица 16.1.
Функции, выполнение которых ограничивается в безопасном режиме
chgrp
include
require
chmod
link
rmdir
chown
passthru
symlink
exec
popen
system
fopen
readfile
unlink
file
rename
К сожалению, документация РНР по безопасному режиму не обновлялась с версии 2.0, хотя функциональность безопасного режима практически не изменилась. Документация находится по адресу http://www.php.net/manual/phpfi2.html.
Safe_mode_exec_dir
Параметр определяет каталог для размещения системных программ, запускаемых такими функциями, как system( ), exec( ) или passthru( ). Параметр используется лишь при включенном безопасном режиме.
Шифрование данных
Шифрованием
называется процесс преобразования данных в формат, в котором они могут быть прочитаны (во всяком случае, теоретически) только предполагаемым
получателем сообщения. Получатель расшифровывает данные при помощи ключа или секретного пароля. РНР поддерживает несколько алгоритмов шифрования. Наиболее важные из этих алгоритмов описаны ниже.
Sql.safe_mode
При включении параметра sql .safejnode игнорируется вся информация, передаваемая функциям mysql_connect( ) и mysql_pconnect( ), а подключения разрешаются только для UID, под которым работает web-сервер.
User_dir
Параметр определяет имя подкаталога в домашнем каталоге пользователя, в котором должны находиться исполняемые сценарии РНР. Например, если параметру user_dir присвоено значение scripts и пользователь с именем Alessia хочет выполнить сценарий somescript.php, он должен создать в своем домашнем каталоге подкаталог с именем scripts и поместить сценарий в этот каталог. К сценарию можно обратиться по URL http://www.yoursite.com/~alessia/somescript.php. Обратите внимание — каталог scripts в URL не включается. Как правило, этот параметр используется в сочетании с параметром конфигурации Apache UserDi г.
Verisign
Компания Verisign, Inc. (http://www.verisign.com) предоставляет широкий ассортимент коммерческих продуктов и услуг. В РНР предусмотрена поддержка взаимодействия со службой Verisign Payflow Pro.
Для использования средств Verisign РНР необходимо откомпилировать с ключом -with-pfproC-DIR]. Кроме того, в файле php.ini имеется несколько конфигурационных параметров, относящихся к Payflow Pro.
Поддержка Payflow Pro в РНР очень проста в использовании, а непосредственное проведение сделок требует минимальных времени и знаний. Однако простое включение поддержки Verisign при компиляции РНР вовсе не означает, что вы можете пользоваться услугами Verisign! Для этого необходимо предварительно зарегистрироваться на сайте Verisign и принять пакет Verisign SDK. На момент написания книги за подключение к Payflow Pro взимался разовый взнос $249, а также ежемесячная оплата $59.95 (если ежемесячное количество сделок не превышает 5000) или $995 (при неограниченном количестве сделок).
И еще одно замечание: прежде чем оплачивать услуги Verisign, вы можете протестировать свой сценарий при помощи тестового входа (эту услугу Verisign предлагает бесплатно). Бесплатное тестирование сценариев избавит вас от лишних расходов в процессе отладки программ. Дополнительную информацию можно получить на сайте Verisign.