Функция file( ) загружает все содержимое файла в индексируемый массив. Каждый элемент массива соответствует одной строке файла. Синтаксис функции filе ( ):
array file (string файл [, int включение_пути])
Если необязательный третий параметр включение_пути равен 1, то путь к файлу определяется по отношению к каталогу включаемых файлов, указанному в файле php.ini (см. главу 1). В листинге 7.5 функция file( ) используется для загрузки файла pastry.txt (см. листинг 7.1).
Листинг 7.5.
Загрузка файла pastry.txt функцией file( )
<?
$file_array = file( "pastry.txt" );
while ( list( $line_num. $line ) = eacht($file_array ) ):
Line 2: 3/4 stick (6 tablespoons) unsalted butter, chopped
Line 3: 2 tablespoons vegetable shortening
Line 4: 1/4 teaspoon salt
Line 5: 3 tablespoons water
Чтение из файла
Несомненно, чтение является самой главной операцией, выполняемой с файлами. Ниже описаны некоторые функции, повышающие эффективность чтения из файла. Синтаксис этих функций практически точно копирует синтаксис аналогичных функций записи.
is_readable( )
Функция i s_readable( ) позволяет убедиться в том, что файл существует и для него разрешена операция чтения. Возможность чтения проверяется как для файла, так и для каталога. Синтаксис функции is_readable( ):
boo! is_readable (string файл]
Скорее всего, РНР будет работать под идентификатором пользователя, используемым web-сервером (как правило, «nobody»), поэтому для того чтобы функция is_readable( ) возвращала TRUE, чтение из файла должно быть разрешено всем желающим. Следующий пример показывает, как убедиться в том, что файл существует и доступен для чтения:
if ( is_readable($filename) ) :
// Открыть файл и установить указатель текущей позиции в конец файла
$fh = fopen($filename, "r");
else :
print "$filename is not readable!";
endif;
fread( )
Функция fread( ) читает из файла, заданного файловым манипулятором, заданное количество байт. Синтаксис функции fwrite( ):
int fread(int манипулятор, int длина)
Манипулятор должен ссылаться на открытый файл, доступный для чтения (см. описание функции is_readable( )). Чтение прекращается после прочтения заданного количества байт или при достижении конца файла. Рассмотрим текстовый файл pastry.txt, приведенный в листинге 7.1. Чтение и вывод этого файла в браузере осуществляется следующим фрагментом:
$fh = fopen('pastry.txt', "r") or die("Can't open file!");
$file = fread($fh, filesize($fh));
print $file;
fclose($fh);
Используя функцию fllesize( ) для определения размера pastry.txt в байтах, вы гарантируете, что функция fread( ) прочитает все содержимое файла.
2 tablespoons vegetable shortening 1/4 teaspoon salt
3 tablespoons water
fgetc( )
Функция fgetc( ) возвращает строку, содержащую один символ из файла в текущей позиции указателя, или FALSE при достижении конца файла. Синтаксис функции fgetc( ):
string fgetc (int манипулятор)
Манипулятор должен ссылаться на открытый файл, доступный для чтения (см. описание функции is_readable( ) ранее в этой главе). В следующем примере продемонстрированы посимвольное чтение и вывод файла с использованием функции fgetc( ):
$fh = fopen("pastry.txt", "r"); while (! feof($fh)) :
$char = fgetc($fh):
print $char; endwhile;
fclose($fh);
fgets( )
Функция fgets( ) возвращает строку, прочитанную от текущей позиции указателя в файле, определяемом файловым манипулятором. Файловый указатель должен ссылаться на открытый файл, доступный для чтения (см. описание функции is_readable( ) ранее в этой главе). Синтаксис функции fgets( ):
string fgets (int манипулятор, int длина)
Чтение прекращается при выполнении одного из следующих условий:
из файла прочитано длина — 1 байт;
из файла прочитан символ новой строки (включается в возвращаемую строку);
из файла прочитан признак конца файла (EOF).
Если вы хотите организовать построчное чтение файла, передайте во втором параметре значение, заведомо превышающее количество байт в строке. Пример построчного чтения и вывода файла:
$fh = fopen("pastry.txt", "r");
while (! feof($fh));
$line = fgets($fh, 4096);
print $line. "<br>";
endwhile;
fclose($fh):
fgetss( )
Функция fgetss( ) полностью аналогична fgets( ) за одним исключением — она пытается удалять из прочитанного текста все теги HTML и РНР:
string fgetss (Int манипулятор, int длина [, string разрешенные_теги])
Прежде чем переходить к примерам, ознакомьтесь с содержимым листинга 7.2 — этот файл используется в листингах 7.3 и 7.4.
Листинг 7.2.
Файл science.html
<html>
<head>
<title>Breaking News - Science</title>
<body>
<h1>Alien lifeform discovered</h1><br>
<b>August 20. 2000</b><br>
Early this morning, a strange new form of fungus was found growing in the closet of W. J. Gilmore's old apartment refrigerator. It is not known if powerful radiation emanating from the tenant's computer monitor aided in this evolution.
</body>
</html>
Листинг 7.З.
Удаление тегов из файла HTML перед отображением в браузере
<?
$fh = fopen("science.html", "r");
while (! feof($fh)) :
print fgetss($fh, 2048);
endwhile;
fclose($fh);
?>
Результат приведен ниже. Как видите, из файла science.html были удалены все теги HTML, что привело к потере форматирования:
Breaking News - Science Alien lifeform discovered August 20. 2000 Early this morning, a strange new form of fungus was found growing in the closet of W. J. Gilmore's old apartment refrigerator. It is not known if powerful radiation emanating from the tenant's computer monitor aided in this evolution.
В некоторых ситуациях из файла удаляются все теги, кроме некоторых — например, тегов разрыва строк <br>. Листинг 7.4 показывает, как это делается.
Листинг 7.4.
Выборочное удаление тегов из файла HTML
<?
$fh = fopenC'science.html", "r");
$allowable = "<br>";
while (! feof($fh)) :
print fgetss($fh. 2048, $allowable);
endwhile;
fclose($fh);
?>
Результат:
Breaking News - Science Alien lifeform discovered August 20. 2000 Early this morning, a strange new form of fungus was found growing in the closet of W. J. Gilmore's old apartment refrigerator. It is not known if powerful radiation emanating from the tenant's computer monitor aided in this evolution.
Как видите, функция fgetss( ) упрощает преобразование файлов, особенно при наличии большого количества файлов HTML, отформатированных сходным образом.
В этой главе были представлены
В этой главе были представлены многие средства РНР, предназначенные для работы с файлами. В частности, мы рассмотрели следующие вопросы:
проверку существования файлов;
открытие и закрытие файлов и потоков ввода/вывода;
запись в файл и чтение из него;
перенаправление файла в выходной поток;
запуск внешних программ;
операции с файловой системой.
Материал этой главы подготовил почву для следующей главы, «Строки и регулярные выражения», поскольку при разработке web-приложений обработка строк и операции ввода/вывода очень тесно связаны.
Копирование и переименование файлов
К числу других полезных системных функций, которые могут выполняться в сценариях РНР, относятся копирование и переименование файлов на сервере. Эти операции выполняются двумя функциями: сору( ) и rename( ).
сору( )
Скопировать файл в сценарии РНР ничуть не сложнее, чем при помощи команды UNIX ср. Задача решается функцией РНР сору( ). Синтаксис функции сору( ):
int copy (string источник, string приемник)
Функция сору( ) пытается скопировать файл источник в файл приемник; в случае успеха возвращается TRUE, а при неудаче — FALSE. Если файл приемник не существует, функция сору( ) создает его. Следующий пример показывает, как создать резервную копию файла при помощи функции сору( ):
$data_file = "datal.txt";
copy($data_file. $data_file'.bak') or die("Could not copy $data_file");
rename ( )
Функция rename( ) переименовывает файл. В случае успеха возвращается TRUE, a при неудаче — FALSE. Синтаксис функции rename( ):
bool rename (string старое_имя, string новое_имя)
Пример переименования файла функцией rename( ):
$data_file = "datal.txt";
rename($data file, $datafile'.old') or die ("Could not rename $data file");
Обратные апострофы
Существует и другой способ выполнения системных команд, не требующий вызова функций, — выполняемая команда заключается в обратные апострофы (` `), а результаты ее работы отображаются в браузере. Пример:
$output = `ls`;
print "<pre>$output</pre>";
Этот фрагмент выводит в браузер содержимое каталога, в котором находится сценарий.
Внутренний параметр ping -с 5 (-п 5 в системе Windows) задает количество опросов сервера.
Если вы хотите просто вернуть неформатированные результаты выполнения команды, воспользуйтесь функцией passthru( ), описанной ниже.
passthru( )
Функция passthru( ) работает почти так же, как ехес( ), за одним исключением — она автоматически выводит результаты выполнения команды. Синтаксис функции passthru( ):
void passthru(string команда [, int возврат])
Если при вызове passthru( ) передается необязательный параметр возврат, этой переменной присваивается код возврата выполненной команды.
escapeshellcmd( )
Функция escapeshellcmd( ) экранирует все потенциально опасные символы, которые могут быть введены пользователем (например, на форме HTML), для выполнения команд exec( ), passthru( ), system( ) или рореn( ). Синтаксис:
string escapeshellcmd (string команда)
К пользовательскому вводу всегда следует относиться с определенной долей осторожности, но даже в этом случае пользователи могут вводить команды, которые будут исполняться функциями запуска системных команд. Рассмотрим следующий фрагмент:
$user_input = `rm -rf *`; // Удалить родительский каталог и все его подкаталоги
ехес($user_input); // Выполнить $user_input !!!
Если не предпринять никаких мер предосторожности, такая команда приведет к катастрофе. Впрочем, можно воспользоваться функций escapeshellcmd( ) для экранирования пользовательского ввода:
$user_input = `rm - rf *`; // Удалить родительский каталог и все его подкаталоги
Функция escapeshellcmd( ) экранирует символ *, предотвращая катастрофические последствия выполнения команды.
Безопасность является одним из важнейших аспектов программирования в среде Web, поэтому я посвятил целую главу этой теме и ее отношению к программированию РНР. За дополнительной информацией обращайтесь к главе 16.
Открытие файлового манипулятора процесса
popen( )
Наряду с обычными файлами можно открывать файловые манипуляторы для взаимодействия с процессами на сервере. Задача решается функцией рореn( ), которая имеет следующий синтаксис:
int popen (string команда, string режим)
Параметр команда определяет выполняемую системную команду, а параметр режим описывает режим доступа:
<?
// Открыть файл "spices.txt" для записи
$fh = fopen("spices.txt","w");
// Добавить несколько строк текста
fputs($fh, "Parsley, sage, rosemary\n");
fputs($fh, "Paprika, salt, pepper\n");
fputs($fh, "Basil, sage, ginger\n");
// Закрыть манипулятор
fclose($fh);
// Открыть процесс UNIX grep для поиска слова Basil в файле spices.txt
$fh - popen("grep Basil < spices.txt", "r");
// Вывести результат работы grep
fpassthru($fh);
?>
Результат выглядит так:
Basil, sage, ginger
Функция fpassthru( ) является аналогом функции passthru( ), рассматриваемой в разделе «Запуск внешних программ» этой главы.
pclose( )
После выполнения всех операций файл или процесс необходимо закрыть. Функция pclose( ) закрывает соединение с процессом, заданным манипулятором, по аналогии с тем, как функция fclose( ) закрывает файл, открытый функцией fopen( ). Синтаксис функции pclose( ):
int pclose (int манипулятор}
В параметре манипулятор передается манипулятор, полученный ранее при успешном вызове рореn( ).
Открытие и закрытие файлов
Прежде чем выполнять операции ввода/вывода с файлом, необходимо открыть его функцией fopen( ).
fopen( )
Функция fopen( ) открывает файл (если он существует) и возвращает целое число — так называемый файловый манипулятор (file handle). Синтаксис функции fopen( ):
int fopen (string файл, string режим [, int включение_пути])
Открываемый файл может находиться в локальной файловой системе, существовать в виде стандартного потока ввода/вывода или представлять файл в удаленной системе, принимаемой средствами HTTP или FTP.
Параметр файл может задаваться в нескольких формах, перечисленных ниже:
Если параметр содержит имя локального файла, функция fopen( ) открывает этот файл и возвращает манипулятор.
Если параметр задан в виде php://stdin, php://stdout или php://stderr, открывается соответствующий стандартный поток ввода/вывода.
Если параметр начинается с префикса http://, функция открывает подключение HTTP к серверу и возвращает манипулятор для указанного файла.
Если параметр начинается с префикса ftp://, функция открывает подключение FTP к серверу и возвращает манипулятор для указанного файла. В этом случае следует обратить особое внимание на два обстоятельства: если сервер не поддерживает пассивный режим FTP, вызов fopen( ) завершается неудачей. Более того, FTP-файлы открываются либо для чтения, либо для записи.
При работе в пассивном режиме сервер ЯР ожидает подключения со стороны клиентов. При работе в активном режиме сервер сам устанавливает соединение с клиентом. По умолчанию обычно используется активный режим.
Параметр режим определяет возможность выполнения чтения и записи в файл. В табл. 7.1 перечислены некоторые значения, определяющие режим открытия файла.
Таблица 7.1.
Режимы открытия файла
Режим
Описание
r
Только чтение. Указатель текущей позиции устанавливается в начало файла
r+
Чтение и запись. Указатель текущей позиции устанавливается в начало файла
w
Только запись. Указатель текущей позиции устанавливается в начало файла, а все содержимое файла уничтожается. Если файл не существует, функция пытается создать его
w+
Чтение и запись. Указатель текущей позиции устанавливается в начало файла, а все содержимое файла уничтожается. Если файл не существует, функция пытается создать его
a
Только запись. Указатель текущей позиции устанавливается в конец файла. Если файл
не существует, функция пытается создать его
a+
Чтение и запись. Указатель текущей позиции устанавливается в конец файла. Если файл не существует, функция пытается создать его
<
/p>
Если необязательный третий параметр включение_пути равен 1, то путь к файлу определяется по отношению к каталогу включаемых файлов, указанному в файле php.ini (см. главу 1).
Ниже приведен пример открытия файла функцией fopen( ). Вызов die( ), используемый в сочетании с fopen( ), обеспечивает вывод сообщения об ошибке в том случае, если открыть файл не удастся:
$file = "userdata.txt"; // Некоторый файл
$fh = fopen($file, "a+") or die("File ($file) does not exist!");
Следующий фрагмент открывает подключение к сайту РНР (http://www.php.net):
$site = "http://www.php.net": // Сервер, доступный через HTTP
$sh = fopen($site., "r"); //Связать манипулятор с индексной страницей Php.net
После завершения работы файл всегда следует закрывать функцией fclose( ).
fclose ( )
Функция fclose( ) закрывает файл с заданным манипулятором. При успешном закрытии возвращается TRUE, при неудаче — FALSE. Синтаксис функции fclose( ):
int fclose(int манипулятор)
Функция fclose( ) успешно закрывает только те файлы, которые были ранее открыты функциями fopen( ) или fsockopen( ). Пример закрытия файла:
$file = "userdata.txt";
if (file_exists($file)) :
$fh = fopen($file, "r");
// Выполнить операции с файлом
fclose($fh);
else :
print "File Sfile does not exist!";
endif;
Открытие соединения через сокет
РНР не ограничивается взаимодействием с файлами и процессами — вы также можете устанавливать соединения через сокеты. Сокет (socket) представляет собой программную абстракцию, позволяющую устанавливать связь с различными службами другого компьютера.
fsockopen( )
Функция fsockopen( ) устанавливает сокетное соединение с сервером в Интернете
через протокол TCP или UDP. Синтаксис функции fsockopen( ):
int fsockopen (string узел, int порт [, int код_ошибки [, string текст_ошибки [, int тайм-аут]]])
Необязательные параметры код_ошибки и текст_ошибки содержат информацию, которая будет выводиться в случае неудачи при подключении к серверу. Оба параметра должны передаваться по ссылке. Третий необязательный параметр, тайм-аут, задает продолжительность ожидания ответа от сервера (в секундах). В листинге 7.6 продемонстрировано применение функции fsockopen( ) для получения информации о сервере. Однако перед рассмотрением листинга 7.6 необходимо познакомиться еще с одной функцией — socket_set_blocking( ).
UDP (User Datagram Protocol) — коммуникационный протокол, не ориентированный на соединение.
socket_set_blocking( )
Функция socket_set_b1ocki ng( ) позволяет установить контроль над тайм-аутом для операций с сервером:
Параметр манипулятор задает открытый ранее сокет, а параметр режим выбирает режим, в который переключается сокет (TRUE для блокирующего режима, FALSE для неблокирующего режима). Пример использования функций fsockopen( ) и socket_set_blocking( ) приведен в листинге 7.6.
Листинг 7.6.
Использование функции fsockopen() для получения информации о сервере
Функция pfsockopen( ) представляет собой устойчивую (persistent) версию fsockopen( ). Это означает, что соединение не будет автоматически разорвано по завершении сценария, в котором была вызвана функция. Синтаксис функции pfsockopen( ):
int pfsockopen (string узел, int порт [, int код_ошибки [, string текст _ошибки [, int тайм-аут]]])
В зависимости от конкретных целей вашего приложения может оказаться удобнее использовать pfsockopen( ) вместо fsockopen( ).
Отображение и изменение характеристик файлов
У каждого файла в системах семейства UNIX есть три важные характеристики:
принадлежность группе;
владелец;
разрешения (permissions).
Все эти характеристики можно изменить при помощи соответствующих функций РНР. Функции, описанные в этом разделе, не работают в системах семейства Windows.
Если у вас нет опыта работы в операционных системах UNIX, информацию о характеристиках файловой системы UNIX можно получить по адресу http://sunsite.auc.dk/linux-newbie/FAQ2.htm. Темы принадлежности группе, владения и разрешений рассматриваются в разделе 3.2.6.
chgrp( )
Функция chgrp( ) пытается сменить группу, которой принадлежит заданный файл. Синтаксис функции chgrp( ):
int chgrp (string имя_файла, mixed группа)
filegroup( )
Функция filegroup( ) возвращает идентификатор группы владельца файла с заданным именем или FALSE в случае ошибки. Синтаксис функции filegroup( ):
int filegroup (string имя_файла)
chmod( )
Функция chmod( ) изменяет разрешения файла с заданным именем. Синтаксис функции chmod( ):
int chmod (string имя_файла, int разрешения)
Разрешения задаются в восьмеричной системе. Специфика задания параметра функции chmod ( ) продемонстрирована в следующем примере:
chmod("data_file.txt", g+r); // He работает
chmod("data_file.txt", 766); // Не работает
chmod("data_file.txt", 0766); // Работает
fileperms( )
Функция fileperms( ) возвращает разрешения файла с заданным именем или FALSE в случае ошибки. Синтаксис функции fileperms( ):
int fileperms (string имя_файла)
chown( )
Функция chown( ) пытается сменить владельца файла. Право изменения владельца файла предоставляется только привилегированному пользователю. Синтаксис функции chown( ):
int chown (string имя_файла, mixed пользователь)
fileowner( )
Функция fileowner( ) возвращает идентификатор пользователя для владельца файла с заданным именем. Синтаксис функции fileowner( ):
int fileowner (string имя_файла)
Перенаправление файла в стандартный выходной поток
Функция readfile( ) читает содержимое файла и направляет его в стандартный вывод (в большинстве случаев — в браузер). Синтаксис функции readfile( ):
int readfile (string файл [, int включение_пути])
Функция возвращает количество прочитанных байтов. Файл может находиться в локальной файловой системе, существовать в виде стандартного потока ввода/вывода или представлять файл в удаленной системе, принимаемой средствами HTTP или FTP. Параметр файл задается по тем же правилам, что и в функции fopen( ).
Предположим, у вас имеется файл latorre.txt, содержимое которого вы хотите вывести в браузере:
Restaurant "La Тоrrе." located in Nettuno, Italy, offers an eclectic blend of style. history, and fine seafood cuisine. Within the walls of the medieval borgo surrounding the city, one can dine while watching the passersby shop in the village boutiques. Comfort coupled with only the freshest seafare make La Torre one of Italy's finest restaurants.
При выполнении следующего фрагмента все содержимое latorre.txt направляется в стандартный выходной поток:
<?
$restaurant_file = "latorre.txt";
// Направить весь файл в стандартный выходной поток
readfile($restaurant_filе);
?>
Проект 1: простой счетчик обращений
Сценарий, представленный в этом разделе, подсчитывает количество обращений к странице, в которой он находится. Прежде чем переходить к программному коду в листинге 7.9, просмотрите алгоритм, написанный на псевдокоде:
Присвоить переменной $access имя файла, в котором будет храниться значение счетчика.
Использовать функцию filе( ) для чтения содержимого $access в массив $visits. Префикс @ перед именем функции подавляет возможные ошибки (например, отсутствие файла с заданным именем).
Присвоить переменной $current_visitors значение первого (и единственного) элемента массива $visits.
Увеличить значение $current_visitors на 1.
Открыть файл $access для записи и установить указатель текущей позиции в начало файла.
Записать значение $current_visitors в файл $access.
Закрыть манипулятор, ссылающийся на файл $access.
Листинг 7.9.
Простой счетчик обращений
<?
// Сценарий: простой счетчик обращений
// Назначение: сохранение количества обращений в файле
$access = "hits.txt"; // Имя файла выбирается произвольно
$visits = @file($access); // Прочитать содержимое файла в масссив
$current_visitors = $visits[0]; // Извлечь первый (и единственный) элемент
++$current_visitors; // Увеличить счетчик обращений
$fh = fopen($access. "w"); // Открыть файл hits.txt и установить
// указатель текущей позиции в начало файла
@fwrite($fh, $current_visitors);// Записать новое значение счетчика
Сценарий, приведенный в листинге 7.10, строит карту сайта — иерархическое изображение всех папок и файлов на сервере, начиная с заданного каталога. При вычислении отступов элементов, из которых состоит карта сайта, используются функции, определенные в этой и предыдущих главах. Прежде чем переходить к программе, просмотрите алгоритм, написанный на псевдокоде:
Объявить служебные переменные для хранения родительского каталога, имени графического файла с изображением папки, названия страницы и флага серверной ОС (Windows или другая система).
Объявить функцию display_directory( ), которая читает содержимое каталога и форматирует его для вывода в браузере.
Построить путь к каталогу объединением имени, передаваемого в переменной $dir1, с $dir.
Открыть каталог и прочитать его содержимое. Отформатировать имена каталога и файлов и вывести их в браузере.
Если текущий файл является каталогом, рекурсивно вызвать функцию display_di rectory( ) и передать ей имя нового каталога для вывода. Вычислить отступ, используемый при форматировании вывода.
Если файл не является каталогом, он форматируется для отображения в виде гиперссылки (а также вычисляется отступ, используемый при форматировании).
Листинг 7.10.
Программа sitemap.php
// Файл: sitemap.php
// Назначение: построение карты сайта
// Каталог, с которого начинается построение карты
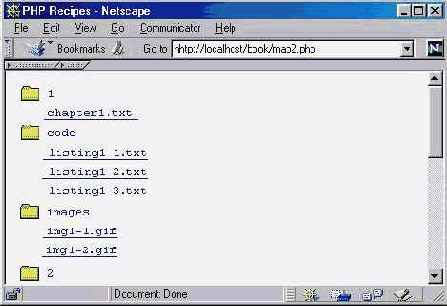
На рис. 7.1 изображен результат выполнения сценария для каталога с несколькими главами этой книги.
Рис. 7.1.
Вывод структуры каталога на сервере с использованием сценария sitemap.php
Проверка существования и размера файла
Прежде чем пытаться работать с файлом, желательно убедиться в том, что он существует. Для решения этой задачи обычно используются две функции:
file_exists( ) и is_file( ).
file_exists( )
Функция f ilе_ехists ( ) проверяет, существует ли заданный файл. Если файл существует, функция возвращает TRUE, в противном случае возвращается FALSE. Синтаксис функции file_exists( ):
bool file_exists(string файл)
Пример проверки существования файла:
if (! file_exists ($filename)) :
print "File $filename does not exist!";
endif:
is_file( )
Функция is_file( ) проверяет существование заданного файла и возможность выполнения с ним операций чтения/записи. В сущности, is_file( ) представляет собой более надежную версию file_exists( ), которая проверяет не только факт существования файла, но и то, поддерживает ли он чтение и запись данных:
bool is_file(string файл)
Следующий пример показывает, как убедиться в существовании файла и возможности выполнения операций с ним:
$file = "somefile.txt";
if (is_file($file)) :
print "The file $file is valid and exists!";
else :
print "The file $file does not exist or it is not a valid file!";
endif:
Убедившись в том, что нужный файл существует и с ним можно выполнять различные операции чтения/записи, можно переходить к следующему шагу — открытию файла.
filesize( )
Функция filesize( ) возвращает размер (в байтах) файла с заданным именем или FALSE в случае ошибки. Синтаксис функции filesize( ):
int filesize(string имя_файла)
Предположим, вы хотите определить размер файла pastry.txt. Для получения нужной информации можно воспользоваться функцией filesize( ):
$fs = filesize("pastry.txt"); print "Pastry.txt is $fs bytes.";
Выводится следующий результат:
Pastry.txt is 179 bytes.
Прежде чем выполнять операции с файлом, необходимо открыть его и связать с файловым манипулятором, а после завершения работы с файлом его следует закрыть. Эти темы рассматриваются в следующем разделе.
Работа с файловой системой
В РНР существуют функции для просмотра и выполнения различных операций с файлами на сервере. Информация об атрибутах серверных файлов (местонахождение, владелец и привилегии) часто бывает полезной.
basename( )
Функция basename( ) выделяет имя файла из переданного полного имени. Синтаксис функции basename( ):
string basename(string полное_имя)
Выделение базового имени файла из полного имени происходит следующим образом:
Фактически эта функция удаляет из полного имени путь и оставляет только имя файла.
getlastmod( )
Функция getlastmod( ) возвращает дату и время последней модификации страницы, из которой вызывается функция. Синтаксис функции getlastmod( ):
int getlastmod(void)
Возвращаемое значение соответствует формату даты/времени UNIX, и для его форматирования можно воспользоваться функцией date( ). Следующий фрагмент выводит дату последней модификации страницы:
В этом примере я воспользовался конструкцией list () для присваивания имен каждому возвращаемому значению. Конечно, с таким же успехом можно вернуть массив, в цикле перебрать элементы и вывести всю необходимую информацию. Как видите, функция stat ( ) позволяет получить различные полезные сведения о файле.
Работа с каталогами
Функции РНР позволяют просматривать содержимое каталогов и перемещаться по ним. В листинге 7.8 изображена типичная структура каталогов в системе UNIX.
Листинг 7.8.
Типичная структура каталогов
drwxr-xr-x 4 root wheel 512 Aug 13 13:51 book/
drwxr-xr-x 4 root wheel 512 Aug 13 13:51 code/
-rw-r--r-- 1 root wheel 115 Aug 4 09:53 index.html
drwxr-xr-x 7 root wheel 1024 Jun 29 13:03 manual/
-rw-r--r-- 1 root wheel 19 Aug 12 12:15 test.php
dirname( )
Функция dirname( ) дополняет basename( ) — она извлекает путь из полного имени файла. Синтаксис функции dirname( ):
string dirname (string путь)
Пример использования dirname( ) для извлечения пути из полного имени:
Функция dirname( ) иногда используется в сочетании с переменной $SCRIPT_FILENAME для получения полного пути к сценарию, из которого выполняется команда:
$dir - dirname($SCRIPT_FILENAME);
is_dir( )
Функция is_dir( ) проверяет, является ли файл с заданным именем каталогом:
bool is_dir (string имя_файла)
В следующем примере используется структура каталогов из листинга 7.8:
Функция mkdir( ) делает то же, что и одноименная команда UNIX, — она создает новый каталог. Синтаксис функции mkdir( ):
int mkdir (string путь, int режим)
Параметр путь определяет путь для создания нового каталога. Не забудьте завершить параметр именем нового каталога! Параметр режим определяет разрешения, назначаемые созданному каталогу.
opendir( )
Подобно тому как функция fopen( ) открывает манипулятор для работы с заданным файлом, функция opendir( ) открывает манипулятор для работы с каталогом. Синтаксис функции opendir( ):
int opendir (string путь)
closedir( )
Функция closedir( ) закрывает манипулятор каталога, переданный в качестве параметра. Синтаксис функции closedir( ):
void closedir(int манипулятор_каталога)
readdir( )
Функция readdir( ) возвращает очередной элемент заданного каталога. Синтаксис:
string readdir(int манипулятор_каталога)
С помощью этой функции можно легко вывести список всех файлов и подкаталогов, находящихся в текущем каталоге:
$dh = opendir(' . );
while ($file = readdir($dh)) :
print "$file <br>"; endwhile;
closedir($dh);
chdir( )
Функция chdir( ) работает так же, как команда UNIX cd, — она осуществляет переход в каталог, заданный параметром. Синтаксис функции chdir( ):
int chdir (string каталог)
В следующем примере мы переходим в подкаталог book/ и выводим его содержимое:
$newdir = "book";
chdir($newdir) or die("Could not change to directory ($newdir)"); $dh = opendir(' . ');
print "Files:";
while ($file = readdir($dh)) ;
print "$file <br>";
endwhile;
closedir($dh);
rewinddir( )
Функция rewlnddir( ) переводит указатель текущей позиции в начало каталога, открытого функцией opendir( ). Синтаксис функции rewinddir( ):
void rewinddir (int нанипулятор_каталога)
Удаление файлов
unlink( )
Функция unlink( ) удаляет файл с заданным именем. Синтаксис:
int unlink (string файл)
Если вы работаете с РНР в системе Windows, при использовании этой функции иногда возникают проблемы. В этом случае можно воспользоваться описанной выше функцией system( ) и удалить файл командой DOS del:
system ("del filename.txt");
Запись в файл
С открытыми файлами выполняются две основные операции — чтение и запись.
is_writeable( )
Функция is_writeable( ) позволяет убедиться в том, что файл существует и для него разрешена операция записи. Возможность записи проверяется как для файла, так и для каталога. Синтаксис функции is_writeable( ):
bool is_writeable (string файл)
Одно важное обстоятельство: скорее всего, РНР будет работать под идентификатором пользователя, используемым web-сервером (как правило, «nobody»). Пример использования is_writeable( ) приведен в описании функции fwrite( ).
fwrite ( )
Функция fwrite( ) записывает содержимое строковой переменной в файл, заданный файловым манипулятором. Синтаксис функции fwrite( ):
int fwrite(int манипулятор, string переменная [, int длина])
Если при вызове функции передается необязательный параметр длина, запись останавливается либо после записи указанного количества символов, либо при достижении конца строки. Проверка возможности записи в файл продемонстрирована в следующем примере:
// Открыть файл и установить указатель текущей позиции в конец файла
$fh = fopen($filename, "a+");
// Записать содержимое $data в файл
$success - fwrite($fh, $data);
// Закрыть файл
fclose($fh); else :
print "Could not open Sfilename for writing";
endif;
?>
Функция fputs( ) является псевдонимом fwrite( ) и может использоваться всюду, где используется fwrite( ).
fputs( )
Функция fputs( ) является псевдонимом fwrite( ) и имеет точно такой же синтаксис. Синтаксис функции fputs( ):
int fputs(int манипулятор, string переменная [, int длина])
Лично я предпочитаю использовать fputs( ). Следует помнить, что это всего лишь вопрос стиля, никак не связанный с какими-либо различиями между двумя функциями.
Запуск внешних программ
Сценарии РНР также могут выполнять программы, находящиеся на сервере. Такая возможность особенно часто используется при администрировании системы через web-браузер, а также для более удобного получения сводной информации о системе.
ехес( )
Функция ехес( ) запускает заданную программу и возвращает последнюю строку ее выходных данных. Синтаксис функции ехес( ):
string exec (string команда [, string массив [, int возврат]])
Обратите внимание: функция ехес( ) только выполняет команду, не выводя результатов ее работы. Все выходные данные команды можно сохранить в необязательном параметре массив. Кроме того, если при заданном параметре массив также задается переменная возврат, последней присваивается код возврата выполненной команды.
Листинг 7.7 показывает, как использовать функцию ехес( ) для выполнения системной функции UNIX ping.
Листинг 7.7.
Проверка связи с сервером с применением функции ехес( )
<?
exec("ping -с 5 www.php.net", $ping);
// В Windows - exec("ping -n 5 www.php.net. $ping);
for ($i=0; $i< count($ping);$i++) :
print "<br>$ping[$i]";
endfor;
?>
Результат:
PING www.php.net (208.247.106.187): 56 data bytes
64 bytes from 208.247.106.187: icmp_seq=0 ttl=243 time=66.602 ms
64 bytes from 208.247.106.187: icmp_seq=1 ttl=243 time=55.723 ms
64 bytes from 208.247.106.187: icmp_seq=2 ttl=243 time=70.779 ms
64 bytes from 208.247.106.187: icmp_seq=3 ttl=243 time=55.339 ms
64 bytes from 208.247.106.187: icmp_seq=4 ttl=243 time=69.865 ms
-- www.php.net ping statistics --
5 packets transmitted. 5 packets received. 0% packet loss
round-trip min/avg/max/stddev - 55.339/63.662/70.779/6.783 ms
Дополнение и сжатие строк
В процессе форматирования часто возникает необходимость в изменении длины строки посредством дополнения или удаления символов. В РНР существует несколько функций, предназначенных для решения этой задачи.
chop ( )
Функция chop( ) возвращает строку после удаления из нее завершающих пропусков и символов новой строки. Синтаксис функции chop( ):
string chop(string строка)
В следующем примере функция chop( ) удаляет лишние символы новой строки:
$header = "Table of Contents\n\n";
$header = chop($header);
// $header = "Table of Contents"
str_pad( )
Функция str_pad( ) выравнивает строку до определенной длины заданными символами и возвращает отформатированную строку. Синтаксис функции str_pad( ):
string str_pad (string строка, int длина_дополнения [, string дополнение [, int тип_дополнения]])
Если необязательный параметр дополнение не указан, строка дополняется пробелами. В противном случае строка дополняется заданными символами. По умолчанию строка дополняется справа; тем не менее, вы можете передать в параметре тип_дополнения константу STR_PAD_RIGHT, STR_PAD_LEFT или STR_PAD_BOTH, что приведет к дополнению строки в заданном направлении. Пример демонстрирует дополнение строки функцией str_pad( ) с параметрами по умолчанию:
// В браузере выводится строка =+=+= Таbе of Contents=+=+="
trim ( )
Функция trim( ) удаляет псе пропуски с обоих краев строки и возвращает полученную строку. Синтаксис функции trim( ):
string trim (string страна]
К числу удаляемых пропусков относятся и специальные символы \n, \r, \t, \v и \0.
ltrim( )
Функция lrim( ) удаляет все пропуски и специальные символы с левого края строки и возвращает полученную строку. Синтаксис функции ltrim( ):
string ltrim (string строка)
Функция удаляет те же специальные символы, что и функция trim( ).
Другие строковые функции
Кроме функций для работы с регулярными выражениями, описанными в первой части этой главы, в РНР существует более 70 функций для выполнения практически всех мыслимых операций со строками. Подробное перечисление и описание всех функций выходит за рамки этой книги и приведет к обычному повторению информации, приведенной в документации РНР. По этой причине я превратил оставшуюся часть главы в своего рода список FAQ из вопросов, часто встречающихся во многих электронных конференциях РНР и на многих сайтах этой тематики. На мой взгляд, этот способ позволяет гораздо эффективнее описать общие принципы громадной библиотеки строковых функций РНР.
Функции РНР для работы с регулярными выражениями (POSIX-совместимые)
В настоящее время РНР поддерживает семь функций поиска с использованием регулярных выражений в стиле POSIX:
еrеg( );
еrеg_rерlасе( );
eregi( );
eregi_replace( );
split( );
spliti( );
sql_regcase( ).
Описания этих функций приведены в следующих разделах.
ereg( )
Функция еrеg( ) ищет в заданной строке совпадение для шаблона. Если совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE. Синтаксис функции ereg( ):
int ereg (string шаблон, string строка [, array совпадения])
Поиск производится с учетом регистра алфавитных символов. Пример использования ereg( ) для поиска в строках доменов .соm:
$is_com - ereg("(\.)(com$)", $email):
// Функция возвращает TRUE, если $email завершается символами ".com"
// В частности, поиск будет успешным для строк
// "www.wjgilmore.com" и "someemail@apress.com"
Обратите внимание: из-за присутствия служебного символа $ регулярное выражение совпадает только в том случае, если строка завершается символами .com. Например, оно совпадет в строке "www.apress.com", но не совпадет в строке "www.apress.com/catalog".
Необязательный параметр совпадения содержит массив совпадений для всех подвыражений, заключенных в регулярном выражении в круглые скобки. В листинге 8.1 показано, как при помощи этого массива разделить URL на несколько сегментов.
Листинг 8.1.
Вывод элементов массива $regs
$url = "http://www.apress.com";
// Разделить $url на три компонента: "http://www". "apress" и "com"
if ($www_url) : // Если переменная $www_url содержит URL
echo $regs[0]; // Вся строка "http://www.apress.com"
print "<br>";
echo $regs[l]; // "http://www"
print "<br>";
echo $regs[2]; // "apress"
print "<br>";
echo $regs[3]; // "com" endif;
При выполнении сценария в листинге 8.1 будет получен следующий результат:
В РНР существует пять функций поиска по шаблону с использованием Perl-совместимых регулярных выражений:
preg_match( );
preg_match_all( );
preg_replace( );
preg_split( );
preg_grep( ).
Эти функции подробно описаны в следующих разделах.
preg_match( )
Функция pregjnatch( ) ищет в заданной строке совпадение для шаблона. Если совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE. Синтаксис функции pregjnatch( ):
int pregjnatch (string шаблон, string строка [, array совпадения})
При передаче необязательного параметра совпадения массив заполняется совпадениями различных подвыражений, входящих в основное регулярное выражение. В следующем примере функция preg_match( ) используется для проведения поиска без учета регистра:
$linе = "Vi is the greatest word processor ever created!";
// Выполнить поиск слова "Vi" без учета регистра символов:
if (preg_match("/\bVi\b\i", $line, $matcn)) :
print "Match found!";
endif;
// Команда if в этом примере возвращает TRUE
preg_match_all( )
Функция preg_match_all( ) находит все совпадения шаблона в заданной строке.
Синтаксис функции preg_match_all( ):
Int preg_match_all (string шаблон, string строка, array совпадения [, int порядок])
Порядок сохранения в массиве совпадения текста, совпавшего с подвыражениями, определяется необязательным параметром порядок. Этот параметр может принимать два значения:
PREG_PATTERN_ORDER — используется по умолчанию, если параметр порядок не указан. Порядок, определяемый значением PREG_PATTERN_ORDER, на первый взгляд выглядит не совсем логично: первый элемент (с индексом 0) содержит массив совпадений для всего регулярного выражения, второй элемент (с индексом 1) содержит массив всех совпадений для первого подвыражения в круглых скобках и т. д.;
PREG_SET_ORDER — порядок сортировки массива несколько отличается от принятого по умолчанию. Первый элемент (с индексом 0) содержит массив с текстом, совпавшим со всеми подвыражениями в круглых скобках для первого найденного совпадения. Второй элемент (с индексом 1) содержит аналогичный массив для второго найденного совпадения и т. д.
http://www.apress.com http://www apress com
ereg_replace( )
Функция ereg_replace( ) ищет в заданной строке совпадение для шаблона и заменяет его новым фрагментом. Синтаксис функции ereg_replace( ):
Функция ereg_replace( ) работает по тому же принципу, что и ereg( ), но ее возможности расширены от простого поиска до поиска с заменой. После выполнения замены функция возвращает модифицированную строку. Если совпадения
отсутствуют, строка остается в прежнем состоянии. Функция ereg_replace( ), как и еrеg( ), учитывает регистр символов. Ниже приведен простой пример, демонстрирующий применение этой функции:
У средств поиска с заменой в языке РНР имеется одна интересная возможность — возможность использования обратных ссылок на части основного выражения, заключенные в круглые скобки. Обратные ссылки похожи на элементы необязательного параметра-массива совпадения функции еrеg( ) за одним исключением: обратные ссылки записываются в виде \0, \1, \2 и т. д., где \0 соответствует всей строке, \1 — успешному совпадению первого подвыражения и т. д. Выражение может содержать до 9 обратных ссылок. В следующем примере все ссылки на URL в тексте заменяются работающими гиперссылками:
Функция eregi( ) ищет в заданной строке совпадение для шаблона. Синтаксис функции eregi( ):
int eregi (string шаблон, string строка [, array совпадения])
Поиск производится без учета регистра алфавитных символов. Функция eregi( ) особенно удобна при проверке правильности введенных строк (например, паролей). Использование функции eregi( ) продемонстрировано в следующем примере:
$password = "abc";
if (! eregi("[[:alnum:]]{8.10}, $password) :
print " Invalid password! Passwords must be from 8 through 10 characters in length.";
endif;
// В результате выполнения этого фрагмента выводится сообщение об ошибке.
// поскольку длина строки "abc" не входит в разрешенный интервал
// от 8 до 10 символов.
eregi_replace( )
Функция eregi_replасе( ) работает точно так же, как ereg_replace( ), за одним исключением: поиск производится без учета регистра символов. Синтаксис функции ereg_replace( ):
Функция split( ) разбивает строку на элементы, границы которых определяются по заданному шаблону. Синтаксис функции split( ):
array split (string шаблон, string строка [, int порог])
Необязательный параметр порог определяет максимальное количество элементов, на которые делится строка слева направо. Если шаблон содержит алфавитные символы, функция spl it( ) работает с учетом регистра символов. Следующий пример демонстрирует использование функции split( ) для разбиения канонического IP-адреса на триплеты:
$ip = "123.345.789.000"; // Канонический IP-адрес
$iparr = split ("\.", $ip) // Поскольку точка является служебным символом.
// ее необходимо экранировать.
print "$iparr[0] <br>"; // Выводит "123"
print "$iparr[1] <br>"; // Выводит "456"
print "$iparr[2] <br>"; // Выводит "789"
print "$iparr[3] <br>"; // Выводит "000"
spliti( )
Функция spliti( ) работает точно так же, как ее прототип split( ), за одним исключением: она не учитывает регистра символов. Синтаксис функции spliti( ):
array spliti (string шаблон, string строка [, int порог])
Разумеется, регистр символов важен лишь в том случае, если шаблон содержит алфавитные символы. Для других символов выполнение spliti( ) полностью аналогично split( ).
sql_regcase( )
Вспомогательная функция sql_regcase( ) заключает каждый символ входной строки в квадратные скобки и добавляет к нему парный символ. Синтаксис функции sql_regcase( ):
string sql_regcase (string строка)
Если алфавитный символ существует в двух вариантах (верхний и нижний регистры), выражение в квадратных скобках будет содержать оба варианта; в противном случае исходный символ повторяется дважды. Функция sql_regcase( ) особенно удобна при использовании РНР с программными пакетами, поддерживающими регулярные выражения в одном регистре. Пример преобразования строки функцией sql_regcase( ):
$version = "php 4.0";
print sql_regcase($version);
// Выводится строка [Pp][Hh][Pp][ ][44][..][00]
Следующий пример показывает, как при помощи функции preg_match_al( ) найти весь текст, заключенный между тегами HTML <b>...</b>:
Функция preg_repl ace( ) работает точно так же, как и ereg_replасе( ), за одним исключением — регулярные выражения могут использоваться в обоих параметрах, шаблон и замена. Синтаксис функции preg_replace( ):
Необязательный параметр порог определяет максимальное количество замен в строке. Интересный факт: параметры шаблон и замена могут представлять собой масивы. Функция preg_replace( ) перебирает элементы обоих массивов и выполняет замену по мере их нахождения.
preg_split( )
Функция preg_spl it( ) аналогична split( ) за одним исключением — параметр шаблон может содержать регулярное выражение. Синтаксис функции preg_split( ):
array preg_split (string шаблон, string строка [, int порог [, int флаги]])
Необязательный параметр порог определяет максимальное количество элементов, на которые делится строка. В следующем примере функция preg_split( ) используется для выборки информации из переменной.
Функция preg_grep( ) перебирает все элементы заданного массива и возвращает все элементы, в которых совпадает заданное регулярное выражение. Синтаксис функции preg_grep():
array preg_grep (string шаблон, array массив)
Пример использования функции preg_grep( ) для поиска в массиве слов, начинающихся на р:
В этой главе был изложен довольно обширный материал. Какой прок от языка программирования, если в нем нельзя работать с текстом? Мы рассмотрели следующие темы:
общие сведения о регулярных выражениях в стилях POSIX и Perl;
стандартные функции РНР для работы с регулярными выражениями;
изменение длины строки;
определение длины строки;
альтернативные функции РНР для обработки строковой информации;
преобразование простого текста в HTML и наоборот;
изменение регистра символов в строках.
Следующая глава открывает вторую часть книги — кстати, мою любимую. В ней мы начнем знакомиться со средствами РНР, ориентированными на Web, рассмотрим процесс динамического создания содержимого, включение файлов и построение общих шаблонов. В дальнейших главах части 2 рассматриваются работа с формами HTML, базы данных, отслеживание данных сеанса и нетривиальные средства работы с шаблонами. Держитесь — начинается самое интересное!
Метасимволы
Одной из интересных особенностей Perl является использование метасимволов при поиске. Метасимвол
[Следует отметить, что авторское толкование термина «метасимвол» противоречит не только всем традициям, по и официальной документации РНР. — Примеч. перев.] представляет собой алфавитный символ с префиксом \ — признаком особой интерпретации следующего символа. Например, метасимвол \d может использоваться при поиске денежных сумм:
/([d]+)000/
Комбинация \d обозначает любую цифру. Конечно, в процессе поиска часто возникает задача идентификации алфавитно-цифровых символов, поэтому в Perl для них был определен метасимвол \w:
/<([\w]+)>/
Этот шаблон совпадает с конструкциями, заключенными в угловые скобки, — например, тёгами HTML. Кстати, метасимвол \W имеет прямо противоположный смысл и используется для идентификации символов, не являющихся алфавитно-цифровыми.
Еще один полезный метасимвол, \b, совпадает с границами слов:
/sa\b/
Поскольку метасимвол границы слова расположен справа от текста, этот шаблон совпадет в строках salsa и lisa, но не в строке sand. Противоположный метасимвол, \В, совпадает с чем угодно, кроме границы слова:
/sa\B/
Шаблон совпадает в таких строках, как sand и Sally, но не совпадает в строке salsa.
Модификаторы
Модификаторы заметно упрощают работу с регулярными выражениями. Впрочем, модификаторов много, и в табл. 8.1 приведены лишь наиболее интересные из них. Модификаторы перечисляются сразу же после регулярного выражения — например, /string/i.
Таблица 8.1.
Примеры модификаторов
Модификатор
Описание
m
Фрагмент текста интерпретируется как состоящий из нескольких «логических строк». По умолчанию специальные символы ^ и $ совпадают только в начале и в конце всего фрагмента. При включении «многострочного режима» при помощи модификатора m^ и $ будут совпадать в начале и в конце каждой логической строки внутри фрагмента
s
По смыслу противоположен модификатору m — при поиске фрагмент интерпретируется как одна строка, а все внутренние символы новой строки игнорируются
i
Поиск выполняется без учета регистра символов
Вводный курс получился очень кратким, поскольку полноценное описание по регулярным выражениям выходит за рамки этой книги и требует нескольких глав вместо нескольких страниц. За дополнительной информацией о синтаксисе регулярных выражений обращайтесь к следующим ресурсам Интернета:
Обработка строковых данных без применения регулярных выражений
При обработке больших объемов информации функции регулярных выражений сильно замедляют выполнение программы. Эти функции следует применять лишь при обработке относительно сложных строк, в которых регулярные выражения действительно необходимы. Если же анализ текста выполняется по относительно простым правилам, можно воспользоваться стандартными функциями РНР, которые заметно ускоряют обработку. Все эти функции описаны ниже.
strtok( )
Функция strtok( ) разбивает строку на лексемы по разделителям, заданным вторым параметром. Синтаксис функции strtok( ):
string strtok (string строка, string разделители)
У функции strtok( ) есть одна странность: чтобы полностью разделить строку, функцию необходимо последовательно вызвать несколько раз. При очередном вызове функция выделяет из строки следующую лексему. При этом параметр строка задается всего один раз — функция отслеживает текущую позицию в строке до тех пор, пока строка не будет полностью разобрана на лексемы или не будет задан новый параметр строка. Следующий пример демонстрирует разбиение строки по нескольким разделителям:
// Обратите внимание: при последующих вызовах strtok
// первый аргумент не передается
$tokenized = strtok($tokens);
endwhile;
Результат:
Element = WJGilmore
Element = wjgilmore@hotmail.com
Element = Columbus
Element = Ohio
parse_str( )
Функция parse_str( ) выделяет в строке пары «переменная-значение» и присваивает значения переменных в текущей области видимости. Синтаксис функции parse_str( ):
void parse_str (string строка)
Функция parse_str( ) особенно удобна при обработке URL, содержащих данные форм HTML или другую расширенную информацию. В следующем примере анализируется информация, переданная через URL. Строка представляет собой стандартный способ передачи данных между страницами либо откомпилированных в гиперссылке, либо введенных в форму HTML:
$url = "fname=wj&lname=gilmore&zip=43210";
parse_str($url);
// После выполнения parse_str( ) доступны следующие переменные:
// $fname = "wj":
// $lname = "gilmore";
// $zip = "43210"
Поскольку эта функция создавалась для работы с URL, она игнорирует символ амперсанд (&).
Работа с формами HTML в РНР описана в главе 10.
explode ( )
Функция explode( ) делит строку на элементы и возвращает эти элементы в виде массива. Синтаксис функции explode( ):
array explode (string разделитель, string строка [, int порог])
Разбиение происходит по каждому экземпляру разделителя, причем количество полученных фрагментов может ограничиваться необязательным параметром порог. Разделение строки функцией explode( ) продемонстрировано в следующем примере:
$info = "wilson | baseball | indians";
$user = explode("|", $info);
// $user[0] = "wilson";
// $user[1] = "baseball";
// $user[2] = "Indians";
Функция explode( ) практически идентична функции регулярных выражений POSIX split( ), описанной выше. Главное различие заключается в том, что передача регулярных выражений в параметрах допускается только при вызове split( ).
implode ( )
Если функция explode( ) разделяет строку на элементы массива, то ее двойник — функция implode( ) - объединяет массив в строку. Синтаксис функции implode( ):
Функция strpos( ) находит в строке первый экземпляр заданной подстроки. Синтаксис функции strpos( ):
int strpos (string строка, string подстрока [, int смещение])
Необязательный параметр offset задает позицию, с которой должен начинаться поиск. Если подстрока не найдена, strpos( ) возвращает FALSE (0).
В следующем примере определяется позиция первого вхождения даты в файл журнала:
$log = "
206.169.23.11:/www/:2000-08-10
206.169.23.11:/www/logs/:2000-02-04
206.169.23.11:/www/img/:1999-01-31";
// В какой позиции в журнале впервые встречается 1999 год?
$pos = strpos($log, "1999");
// $pos = 95. поскольку первый экземпляр "1999"
// находится в позиции 95 строки, содержащейся в переменной $log
strrpos( )
Функция strrpos( ) находит в строке последний экземпляр заданного символа. Синтаксис функции strrpos( ):
int strpos (string строка, char символ)
По возможностям эта функция уступает своему двойнику — функции strpos( ), поскольку она позволяет искать только отдельный символ, а не всю строку. Если во втором параметре strrpos( ) передается строка, при поиске будет использован только ее первый символ.
str_replace( )
Функция str_replace( ) ищет в строке все вхождения заданной подстроки и заменяет их новой подстрокой. Синтаксис функции str_replace( ):
Функция substr_replace( ), описанная ниже в этом разделе, позволяет провести заме ну лишь в определенной части строки. Ниже показано, как функция str_replace( ) используется для проведения глобальной замены в строке.
Если подстрока ни разу не встречается в строке, исходная строка не изменяется:
$favorite_food = "My favorite foods are ice cream and chicken wings";
Функция substr( ) возвращает часть строки, начинающуюся с заданной начальной позиции и имеющую заданную длину. Синтаксис функции substr( ):
string substr (string строка, int начало [, int длина])
Если необязательный параметр длина не указан, считается, что подстрока начинается с заданной начальной позиции и продолжается до конца строки. При использовании этой функции необходимо учитывать четыре обстоятельства:
если параметр начало положителен, возвращаемая подстрока начинается с позиции строки с заданным номером;
если параметр начало отрицателен, возвращаемая подстрока начинается с позиции (длина строки - начало);
если параметр длина положителен, в возвращаемую подстроку включаются все символы от позиции начало до позиции начало+длина. Если последняя величина превышает длину строки, возвращаются символы до конца строки;
если параметр длина отрицателен, возвращаемая подстрока заканчивается на заданном расстоянии от конца строки.
Помните о том, что параметр начало определяет смещение от первого символа строки; таким образом, возвращаемая строка в действительности начинается с символа с номером (начало + 1).
Следующий пример демонстрирует выделение части строки функцией substr( ):
$car = "1944 Ford"; Smodel = substr($car, 6);
// Smodel = "Ford"
Пример с положительным параметром длина:
$car = "1944 Ford";
$model = substr($car, 0, 4);
// $model = "1944"
Пример с отрицательным параметром длина:
$car = "1944 Ford";
$model = substr($car, 2, -5);
// $model = "44"
substr_count( )
Функция substr_count( ) возвращает количество вхождений подстроки в заданную строку. Синтаксис функции substr_count( ):
int substr_count (string строка, string подстрока)
В следующем примере функция substr_count( ) подсчитывает количество вхождений подстроки ain:
$tng_twist = "The rain falls mainly on the plains of Spain";
$count = substr_count($tng_twist, "ain");
// $count = 4
substr_replace( )
Функция substr_replace( ) заменяет часть строки, которая начинается с заданной позиции. Если задан необязательный параметр длина, заменяется фрагмент заданной длины; в противном случае производится замена по всей длине заменяющей строки. Синтаксис функции substr_replace( ):
string substr_replace (string строка, string замена, int начало [, int длина])
Параметры начало и длина задаются по определенным правилам:
если параметр начало положителен, замена начинается с заданной позиции;
если параметр начало отрицателен, замена начинается с позиции (длина строки -начало);
если параметр длина положителен, заменяется фрагмент заданной длины;
если параметр длина отрицателен, замена завершается в позиции (длина строки -длина).
Простая замена текста функцией substr_replace( ) продемонстрирована в следующем примере:
$favs = " 's favorite links";
$name = "Alessia";
// Параметры "0, 0" означают, что заменяемый фрагмент начинается
// и завершается в первой позиции строки.
$favs - substr_replace($favs, $name, 0, 0);
print $favs:
Результат:
Alessia's favorite links
Определение длины строки
Длину строки в символах можно определить при помощи функции strlen( ). Синтаксис .функции strlen( ):
int strlen (string строка)
Следующий пример демонстрирует определение длины строки функцией strlen( ):
$string = "hello";
$length = strlen($string);
// $length = 5
Преобразование HTML в простой текст
Иногда возникает необходимость преобразовать файл в формате HTML в простой текст. Функции, описанные ниже, помогут вам в решении этой задачи.
strip_tags( )
Функция strip_tags( ) удаляет из строки все теги HTML и РНР, оставляя в ней только текст. Синтаксис функции strip_tags( ):
Необязательный параметр разрешенные_теги позволяет указать теги, которые должны пропускаться в процессе удаления.
Ниже приведен пример удаления из строки всех тегов HTML функцией strip_tags( ):
$user_input = "I just <b>love</b> РНР and <i>gourment</i> recipes!";
$stripped_input = strip_tags($user_input);
// $stripped_input = "I just love PHP and gourmet recipes!";
В следующем примере удаляются не все, а лишь некоторые теги:
$input = "I <b>love</b> to <a href = \"http://www.eating.com\">eat!</a>!";
$strip_input = strip_tags ($user_input, "<a>");
// $strip_input = "I love to <a href = \"http://www.eating.com\">eat!</a>!";
Удаление тегов из текста также производится функцией fgetss( ), описанной в главе 7.
get_meta_tags( )
Хотя функция get_meta_tags( ) и не имеет прямого отношения к преобразованию текста, зто весьма полезная функция, о которой следует упомянуть. Синтаксис функции get_meta_tags( ):
array get_meta_tags (string имя_файла/URL [, int включение_пути])
Функция get_meta_tags( ) предназначена для поиска в файле HTML тегов МЕТА.
Теги МЕТА содержат информацию о странице, используемую главным образом поисковыми системами. Эти теги находятся внутри пары тегов <head>...</head>. Применение тегов МЕТА продемонстрировано в следующем фрагменте (назовем его example.html, поскольку он будет использоваться в листинге 8.2):
<meta name="description" content=" PHP Recipes provides savvy readers with the latest in PHP
programming and gourmet cuisine!">
<meta name="author" content="WJ Gilmore">
</head>
Функция get_meta_tags( ) ищет в заголовке документа теги, начинающиеся словом МЕТА, и сохраняет имена тегов и их содержимое в ассоциативном массиве. В листинге 8.2 продемонстрировано применение этой функции к файлу example.html.
Листинг 8.2.
Извлечение тегов МЕТА из файла HTML функцией get_meta_tags( )
$meta_tags = get_meta_tags("example.html"):
// Переменная $meta_tags содержит массив со следующей информацией:
// $meta_tags["description"] = "PHP Recipes provides savvy readers with the latest in PHP
programming and gourmet cuisine";
// $meta_tags["author"] = "WJ Gilmore";
Интересная подробность: данные тегов МЕТА можно извлекать не только из файлов, находящихся на сервере, но и из других URL.
Теги МЕТА и их использование превосходно описаны в статье Джо Берна (Joe Burn) «So, You Want a Meta Command, Huh?» на сайте HTML Goodies: http://htmlgoodies.earthweb.com/tutors/meta.html.
Преобразование строк и файлов к формату HTML и наоборот
Преобразовать строку или целый файл к формату, подходящему для просмотра в web-браузере (или наоборот), проще, чем может показаться на первый взгляд. В РНР для этого существуют специальные функции.
Преобразование текста в HTML
Быстрое преобразование простого текста к формату web-браузера — весьма распространенная задача. В ее решении вам помогут функции, описанные в этом разделе.
nl2br( )
Функция nl2br( ) заменяет все символы новой строки (\n) эквивалентными конструкциями HTML <br>.
Синтаксис функции nl2br( ):
string nl2br (string строка)
Символы новой строки могут быть как видимыми (то есть явно включенными в строку), так и невидимыми (например, введенными в редакторе). В следующем примере текстовая строка преобразуется в формат HTML посредством замены символов \n разрывами строк:
// Текстовая строка, отображаемая в редакторе.
$text_recipe = "
Party Sauce recipe:
1 can stewed tomatoes
3 tablespoons fresh lemon juice
Stir together, server cold.";
// Преобразовать символы новой строки в <br>
$htinl_recipe = nl2br($text_recipe)
При последующем выводе $html_recipe браузеру будет передан следующий текст в формате HTML:
Party Sauce recipe:<br>
1 can stewed tomatoes<br>
3 tablespoons fresh lemon juice<br>
Stir together, server cold.<br>
htmlentities( )
Функция htmlentities( ) преобразует символы в эквивалентные конструкции HTML. Синтаксис функции htmlentities:
string htmlentities (string строка)
В следующем примере производится необходимая замена символов строки для вывода в браузере:
$user_input = "The cookbook, entitled Cafe Francaise' costs < $42.25.";
$converted_input = htmlentities($user_input);
// $converted_input = "The cookbook, entitled 'Cafè
// Fracçiaise' costs < 42.25.";
Функция htmlentities( ) в настоящее время работает только для символов кодировки ISO-8559-1 (ISO-Latin-1). Кроме того, она не преобразует пробелы в , как следовало бы ожидать.
htmlspecialchars( )
Функция htmlspecialchars( ) заменяет некоторые символы, имеющие особый смысл в контексте HTML, эквивалентными конструкциями HTML. Синтаксис функции htmlspecialchars( ):
string htmlspecialchars (string строка)
Функция html special chars( ) в настоящее время преобразует следующие символы:
& преобразуется в &; " " преобразуется в ";
< преобразуется в <; > преобразуется в >.
В частности, эта функция позволяет предотвратить ввод пользователями разметки HTML в интерактивных web-приложениях (например, в электронных форумах). Ошибки, допущенные в разметке HTML, могут привести к тому, что вся страница будет формироваться неправильно. Впрочем, у этой задачи существует и более эффективное решение — полностью удалить теги из строки функцией strip_tags( ).
Следующий пример демонстрирует удаление потенциально опасных символов функцией htmlspeclalchars( ):
$user_input = "I just can't get «enough» of PHP & those fabulous cooking recipes!";
$conv_input = htmlspecialchars($user_input);
// $conv_input = "I just can't <<enough>> of PHP & those fabulous cooking
recipes!"
Если функция htmlspecialchars( ) используется в сочетании с nl2br( ), то последнюю следует вызывать после htmlspecialchars( ). В противном случае конструкции <br>, сгенерированные при вызове nl2br( ), преобразуются в видимые символы.
get_html_translation_table ( )
Функция get_html_translation_table( ) обеспечивает удобные средства преобразования текста в эквиваленты HTML Синтаксис функции get_htrril_translation_table( ):
string get_html_translation_table (int таблица)
Функция get_html_translation_table( ) возвращает одну из двух таблиц преобразования (определяется параметром таблица), используемых в работе стандартных функций htmlspecialchars( ) и htmlentities( ). Возвращаемое значение может использоваться в сочетании с другой стандартной функцией, strtr( ) (см. далее), для преобразования текста в код HTML.
Параметр таблица принимает одно из двух значений:
HTML_ENTITIES;
HTML_SPECIALCHARS.
В следующем примере функция get_html_translation_table( ) используется при преобразовании текста в код HTML:
$string = "La pasta e il piatto piu amato in Italia";
// Специальные символы преобразуются в конструкции HTML
// и правильно отображаются в браузере.
Кстати, функция array_flip( ) позволяет провести преобразование текста в HTML в обратном направлении и восстановить исходный текст. Предположим, что вместо вывода результата strtr( ) в предыдущем примере мы присвоили его переменной $translated string.
В следующем примере исходный текст восстанавливается функцией array_flip( ):
$translate = array_flip($translate);
$translated_string - "La pasta é il piatto piú amato in Italia";
// $original_string = "La pasta e il piatto piu amato in Italia";
strtr( )
Функция strtr( ) транслирует строку, то есть заменяет в ней все символы, входящие в строку источник, соответствующими символами строки приемник. Синтаксис функции strtr( ):
Если строки источник и приемник имеют разную длину, длинная строка усекается до размеров короткой строки.
Существует альтернативный синтаксис вызова strtr( ) с двумя параметрами; в этом случае второй параметр содержит ассоциативный массив, ключи которого соответствуют заменяемым подстрокам, а значения — заменяющим подстрокам. В следующем примере теги HTML заменяются XML-подобными конструкциями:
// Выводится строка "<title>Today in PHP-Powered News</title>"
Преобразование строки к верхнему и нижнему регистру
В РНР существует четыре функции, предназначенных для изменения регистра строки:
strtolower( );
strtoupper( );
ucfirst( );
ucwords( ).
Все эти функции подробно описаны ниже.
strtolower( )
Функция strtolower( ) преобразует все алфавитные символы строки к нижнему регистру. Синтаксис функции strtolower( ):
string strtolower(string строка)
Неалфавитные символы функцией не изменяются. Преобразование строки к нижнему регистру функцией strtolower( ) продемонстрировано в следующем примере:
$sentence = "COOKING and PROGRAMMING PHP are my TWO favorite pastimes!";
$sentence = strtolower($sentence);
// После вызова функции $sentence содержит строку
// "cooking and programming php are my two favorite pastimes!"
strtoupper( )
Строки можно преобразовывать не только к нижнему, но и к верхнему регистру. Преобразование выполняется функцией strtoupper( ), имеющей следующий синтаксис:
string strtoupper (string строка)
Неалфавитные символы функцией не изменяются. Преобразование строки к верхнему регистру функцией strtoupper( ) продемонстрировано в следующем примере:
$sentence = "cooking and programming PHP are my two favorite pastimes!";
$sentence = strtoupper($sentence);
// После вызова функции $sentence содержит строку
// "COOKING AND PROGRAMMING PHP ARE MY TWO FAVORITE PASTIMES!"
ucfirst( )
Функция ucfirst( ) преобразует к верхнему регистру первый символ строки — при условии, что он является алфавитным символом. Синтаксис функции ucfirst( ):
string ucfirst (string строка)
Неалфавитные символы функцией не изменяются. Преобразование первого символа строки функцией ucfirst( ) продемонстрировано в следующем примере:
&sentence = "cooking and programming PHP are my two favorite pastimes!";
$sentence = ucfirst($sentence);
// После вызова функции $sentence содержит строку
// "Cooking and programming PHP are mу two favorite pastimes!"
ucwords( )
Функция ucwords( ) преобразует к верхнему регистру первую букву каждого слова в строке. Синтаксис функции ucwords( ):
string ucwords (string строка")
Неалфавитные символы функцией не изменяются. «Слово» определяется как последовательность символов, отделенная от других элементов строки пробелами. В следующем примере продемонстрировано преобразование первых символов слов функцией ucwords( ):
$sentence = "cooking and programming PHP are my two favorite pastimes!";
$sentence = ucwords($sentence);
// После вызова функции $sentence содержит строку
// "Cooking And Programming PHP Are My Two Favorite Pastimes!"
Проект: идентификация браузера
Каждый программист, пытающийся создать удобный web-сайт, должен учитывать различия в форматировании страниц при просмотре сайта в разных браузерах и операционных системах. Хотя консорциум W3 (http://www.w3.org) продолжает публиковать стандарты, которых должны придерживаться программисты при создании web-приложений, разработчики браузеров любят дополнять эти стандарты своими маленькими «усовершенствованиями», что в конечном счете вызывает хаос и путаницу. Разработчики часто решают эту проблему, создавая разные страницы для каждого типа браузера и операционной системы — при этом объем работы значительно увеличивается, но зато итоговый сайт идеально подходит для любого пользователя. Результат — хорошая репутация сайта и уверенность в том, что пользователь посетит его снова.
Чтобы пользователь мог просматривать страницу в формате, соответствующем специфике его браузера и операционной системы, из входящего запроса на получение страницы извлекается информация о браузере и платформе. После получения необходимых данных пользователь перенаправляется на нужную страницу.
Приведенный ниже проект (sniffer.php) показывает, как использовать функции РНР для работы с регулярными выражениям с целью получения информации по запросам. Программа определяет тип и версию браузера и операционной системы, после чего выводит полученную информацию в окне браузера. Но прежде чем переходить к непосредственному анализу программы, я хочу представить один из главных ее компонентов — стандартную переменную РНР $HTTP_USER_AGENT. В этой переменной в строковом формате хранятся различные сведения о браузере и операционной системе пользователя — именно то, что нас интересует. Эту информацию можно легко вывести на экран всего одной командой:
<?
echo $HTTP USER_AGENT;
?>
При работе в Internet Explorer 5.0 на компьютере с Windows 98 результат будет выглядеть так:
Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; DigExt)
Для Netscape Navigator 4.75 выводятся следующие данные:
Mozilla/4.75 (Win98; U)
Sniffer. php извлекает необходимые данные из $HTTP_USER_AGENT при помощи функций обработки строк и регулярных выражений. Алгоритм программы на псевдокоде:
Определить две функции для идентификации браузера и операционной системы: browser_info( ) и opsys_info( ). Начнем с псевдокода функции browser_info( ).
Определить тип браузера, используя функцию егед( ). Хотя эта функция работает медленнее упрощенных строковых функций типа strstr( ), в данном случае она удобнее, поскольку регулярное выражение позволяет определить версию браузера.
Воспользоваться конструкцией if/elseif для идентификации следующих браузеров и их версий: Internet Explorer, Opera, Netscape и браузер неизвестного типа.
Вернуть информацию о типе и версии браузера в виде массива.
Функция opsys_info( ) определяет тип операционной системы. На этот раз используется функция strstr( ), поскольку тип ОС определяется и без применения регулярных выражений.
Воспользоваться конструкцией if/elseif для идентификации следующих систем: Windows, Linux, UNIX, Macintosh и неизвестная операционная система.
Вернуть информацию об операционной системе.
Листинг 8.3.
Идентификация типа браузера и операционной системы клиента
<?
/*
Файл : sniffer.php
Назначение: Идентификация типа/версии браузера и платформы
Автор: В. Дж. Гилмор
Дата : 24 августа 2000 г.
*/
// Функция: browser_info
// Назначение: Возвращает тип и версию браузера
function browser_info ($agent) {
// Определить тип браузера
// Искать сигнатуру Internet Explorer
if (ereg('MSIE ([0-9].[0-9]{1,2})', $agent, $version))
// Если это не Internet Explorer, Opera или Netscape.
// значит, мы обнаружили неизвестный браузер,
else :
$browse_type = "Unknown";
$browse_version = "Unknown";
endif:
// Вернуть тип и версию браузера в виде массива
return array ($browse_type, $browse_version);
} // Конец функции browser_info
// Функция: opsys_info
// Назначение: Возвращает информацию об операционной системе пользователя
function opsys_info($agent) {
// Идентифицировать операционную систему
// Искать сигнатуру Windows
if ( strstr ($agent. 'win') ) :
$opsys = "windows";
// Искать сигнатуру Linux
elseif ( strstr($agent, 'Linux') ) :
$opsys = "Linux";
// Искать сигнатуру UNIX
elseif ( strstr (Sagent, 'Unix') ) :
$opsys = "Unix";
// Искать сигнатуру Macintosh
elseif ( strstr ($agent, 'Mac') ) :
$opsys = "Macintosh";
// Неизвестная платформа else :
$opsys = "Unknown";
endif;
// Вернуть информацию об операционной системе
return $opsys;
} // Конец функции opsys_info
// Сохранить возвращаемый массив в списке
list ($browse_type. $browse_version) = browser_info ($HTTP_USER_AGENT); Soperating_sys = opsysjnfo ($HTTP_USER_AGENT);
print "Browser Type: $browse_type <br>";
print "Browser Version: $browse_version <br>";
print "Operating System: $operating_sys <br>":
?>
Вот и все! Например, если пользователь работает в браузере Netscape 4.75 на компьютере с системой Windows, будет выведен следующий результат:
Browser Type: Netscape
Browser Version: 4.75
Operating System: Windows
В следующей главе вы научитесь осуществлять переходы между страницами и даже создавать списки стилей (style sheets) для конкретных операционной системы и браузера.
Регулярные выражения
Регулярные выражения
лежат в основе всех современных технологий поиска по шаблону. Регулярное выражение представляет собой последовательность простых и служебных символов, описывающих искомый текст. Иногда регулярные выражения бывают простыми и понятными (например, слово dog), но часто в них присутствуют служебные символы, обладающие особым смыслом в синтаксисе регулярных выражений, — например, <(?)>.*<\/.?>.
В РНР существуют два семейства функций, каждое из которых относится к определенному типу регулярных выражений: в стиле POSIX или в стиле Perl. Каждый тип регулярных выражений обладает собственным синтаксисом и рассматривается в соответствующей части главы. На эту тему были написаны многочисленные учебники, которые можно найти как в Web, так и в книжных магазинах. Поэтому я приведу лишь основные сведения о каждом типе, а дальнейшую информацию при желании вы сможете найти самостоятельно. Если вы еще не знакомы с принципами работы регулярных выражений, обязательно прочитайте краткий вводный курс, занимающий всю оставшуюся часть этого раздела. А если вы хорошо разбираетесь в этой области, смело переходите к следующему разделу.
Синтаксис регулярных выражений (POSIX)
Структура регулярных выражений POSIX чем-то напоминает структуру типичных математических выражений — различные элементы (операторы) объединяются друг с другом и образуют более сложные выражения. Однако именно смысл объединения элементов делает регулярные выражения таким мощным и выразительным средством. Возможности не ограничиваются поиском литерального текста (например, конкретного слова или числа); вы можете провести поиск строк с разной семантикой, но похожим синтаксисом — например, всех тегов HTML в файле.
Простейшее регулярное выражение совпадает с одним литеральным символом — например, выражение g совпадает в таких строках, как g, haggle и bag. Выражение, полученное при объединении нескольких литеральных символов, совпадает по тем же правилам — например, последовательность gan совпадает в любой строке, содержащей эти символы (например, gang, organize или Reagan).
Оператор | (вертикальная черта) проверяет совпадение одной из нескольких альтернатив. Например, регулярное выражение php | zend проверяет строку на наличие php или zend.
Квадратные скобки
Квадратные скобки ([ ]) имеют особый смысл в контексте регулярных выражений — они означают «любой символ из перечисленных в скобках». В отличие от регулярного выражения php, которое совпадает во всех строках, содержащих литеральный текст php, выражение [php] совпадает в любой строке, содержащей символы р или h. Квадратные скобки играют важную роль при работе с регулярными выражениями, поскольку в процессе поиска часто возникает задача поиска символов из заданного интервала. Ниже перечислены некоторые часто используемые интервалы:
[0-9] — совпадает с любой десятичной цифрой от 0 до 9;
[a-z] — совпадает с любым символом нижнего регистра от а до z;
[A-Z] — совпадает с любым символом верхнего регистра от А до Z;
[a -Z] — совпадает с любым символом нижнего или верхнего регистра от а до Z.
Конечно, перечисленные выше интервалы всего лишь демонстрируют общий принцип. Например, вы можете воспользоваться интервалом [0-3] для обозначения любой десятичной цифры от 0 до 3 или интервалом [b-v] для обозначения любого символа нижнего регистра от b до v. Короче говоря, интервалы определяются совершенно произвольно.
Квантификаторы
Существует особый класс служебных символов, обозначающих количество повторений отдельного символа или конструкции, заключенной в квадратные скобки. Эти служебные символы (+, * и {...}) называются квантификаторами. Принцип их действия проще всего пояснить на примерах:
р+ означает один или несколько символов р, стоящих подряд;
р* означает ноль и более символов р, стоящих подряд;
р? означает ноль или один символ р;
р{2} означает два символа р, стоящих подряд;
р{2,3} означает от двух до трех символов р, стоящих подряд;
р{2,} означает два и более символов р, стоящих подряд.
Прочие служебные символы
Служебные символы $ и ^ совпадают не с символами, а с определенными позициями в строке. Например, выражение р$ означает строку, которая завершается символом р, а выражение ^р — строку, начинающуюся с символа р.
Конструкция [^a-zA-Z] совпадает с любым символом, не входящим в указаные интервалы (a-z и A-Z).
Служебный символ . (точка) означает «любой символ». Например, выражение р.р совпадает с символом р, за которым следует произвольный символ, после чего опять следует символ р.
Объединение служебных символов приводит к появлению более сложных выражений. Рассмотрим несколько примеров:
^.{2}$ — любая строка, содержащая ровно два символа;
<b>(.*)</b> — произвольная последовательность символов, заключенная между <Ь> и </Ь> (вероятно, тегами HTML для вывода жирного текста);
p(hp)* — символ р, за которым следует ноль и более экземпляров последовательности hp (например, phphphp).
Иногда требуется найти служебные символы в строках вместо того, чтобы использовать их в описанном специальном контексте. Для этого служебные символы экранируются обратной косой чертой (\). Например, для поиска денежной суммы в долларах можно воспользоваться выражением \$[0-9]+, то есть «знак доллара, за которым следует одна или несколько десятичных цифр». Обратите внимание на обратную косую черту перед $. Возможными совпадениями для этого регулярного выражения являются $42, $560 и $3.
Стандартные интервальные выражения (символьные классы)
Для удобства программирования в стандарте POSIX были определены некоторые стандартные интервальные выражения, также называемые символьными классами (character classes). Символьный класс определяет один символ из заданного интервала — например, букву алфавита или цифру:
[[:alpha:]] — алфавитный символ (aA-zZ);
[[:digit:]]-цифра (0-9);
[[:alnum:]] — алфавитный символ (aA-zZ) или цифра (0-9);
[[:space:]] — пропуски (символы новой строки, табуляции и т. д.).
Синтаксис регулярных выражений в стиле Perl
Perl (http://www.perl.com) давно считается одним из самых лучших языков обработки текстов. Синтаксис Perl позволяет осуществлять поиск и замену даже для самых сложных шаблонов. Разработчики РHР сочли, что не стоит заново изобретать уже изобретенное, а лучше сделать знаменитый синтаксис регулярных выражений Perl доступным для пользователей РНР. Так появились функции для работы с регулярными выражениями в стиле Perl.
Диалект регулярных выражений Perl не так уж сильно отличается от диалекта POSIX. В сущности, синтаксис регулярных выражений Perl является отдаленным потомком реализации POSIX, вследствие чего синтаксис POSIX почти совместим с функциями регулярных выражений стиля Perl.
Оставшаяся часть этого раздела будет посвящена краткому знакомству с диалектом регулярных выражений Perl. Рассмотрим простой пример:
/food/
Обратите внимание: строка food заключена между двумя косыми чертами. Как и в стандарте POSIX, вы можете создавать более сложные шаблоны при помощи квантификаторов:
/fo+/
Этот шаблон совпадает с последовательностью fo, за которой могут следовать дополнительные символы о. Например, совпадения будут обнаружены в строках food, fool и fo4. Рассмотрим другой пример использования квантификатора:
/fo{2,4}/
Шаблон совпадает с символом f, за которым следуют от 2 до 4 экземпляров символа о. К числу потенциальных совпадений относятся строки fool , fooool и foosball .
В регулярных выражениях Perl могут использоваться все квантификаторы, упомянутые в предыдущем разделе для регулярных выражений POSIX.
Сравнение двух строк
Сравнение двух строк принадлежит к числу важнейших строковых операций любого языка. Хотя эту задачу можно решить несколькими разными способами, в РНР существуют четыре функции сравнения строк:
strcmp( );
strcasecmp( );
strspn( );
strcspn( ).
Все эти функции подробно описаны в следующих разделах.
strcmp( )
Функция strcmp( ) сравнивает две строки с учетом регистра символов. Синтаксис функции strcmp( ):
int strcmp (string строка1, string строка2)
После завершения сравнения strcmp( ) возвращает одно из трех возможных значений:
0, если строка1 и строка2 совпадают;
< 0, если строка1 меньше, чем строка2;
> 0, если строка2 меньше, чем строка1.
В следующем фрагменте сравниваются две одинаковые строки:
$sthng1 = "butter";
$string2 = "butter";
if ((strcmp($string1. $string2)) == 0) :
print "Strings are equivalent!"; endif;
// Команда if возвращает TRUE
strcasecmp( )
Функция strcasecmp( ) работает точно так же, как strcmp( ), за одним исключением — регистр символов при сравнении не учитывается. Синтаксис функции strcasecmp( ):
int strcasecmp (string cтpoкa1, string строка2)
В следующем фрагменте сравниваются две одинаковые строки:
$string1 = "butter";
$string2 = "Butter";
if ((strcmp($string1, $string2)) == 0) :
print "Strings are equivalent!";
endif;
// Команда if возвращает TRUE
strspn( )
Функция strspn( ) возвращает длину первого сегмента строки1, содержащего символы, присутствующие в строке2. Синтаксис функции strspn( ):
int strspn (string строка1, string строка2)
Следующий фрагмент показывает, как функция strspn( ) используется для проверки пароля:
$password = "12345";
if (strspn($password, "1234567890") != strlen($password)) :
print "Password cannot consist solely of numbers!";
endif:
strcspn( )
Функция strcspn( ) возвращает длину первого сегмента строки1, содержащего символы, отсутствующие в строке2. Синтаксис функции strcspn( ):
int strcspn (string строка1, string строка2)
В следующем фрагменте функция strcspn( ) используется для проверки пароля:
$password = "12345";
if (strcspn($password, "1234567890") == 0) :
print "Password cannot consist solely of numbers!";
endif;
Файловые компоненты (шаблоны)
Мы подошли к одной из моих любимых возможностей РНР. Шаблоном (применительно к web-программированию) называется часть web-документа, которую вы собираетесь использовать в нескольких страницах. Шаблоны, как и функции РНР, избавляют вас от лишнего копирования/вставки фрагментов содержания страницы и программного кода. С увеличением масштабов сайта значение шаблонов возрастает, поскольку они позволяют легко и быстро проводить модификации на уровне целого сайта. В этом разделе будут описаны некоторые возможности, которые открываются при использовании простейших шаблонов.
Как правило, общие фрагменты содержания/кода (то есть шаблоны) сохраняются в отдельных файлах. При построении web-документа вы просто «включаете» эти файлы в соответствующие места страницы. В РНР для этого существуют две функции: include( ) и require( ).
Функции
В РНР существуют четыре функции для включения файлов в сценарии РНР:
include( );
include_once( );
require( );
require_once( ).
Несмотря на сходство имен, эти функции решают разные задачи.
include( )
Функция include( ) включает содержимое файла в сценарий. Синтаксис функции include( ):
include (file файл]
У функции include( ) есть одна интересная особенность — ее можно выполнять условно. Например, если вызов функции включен в блок команды if. то файл включается в программу лишь в том случае, если условие i f истинно. Если функция includeO используется в условной команде, то она должна быть заключена в фигурные скобки или в альтернативные ограничители. Сравните различия в синтаксисе листингов 9.1 и 9.2.
Листинг 9.1.
Неправильное использование include( )
if (some_conditional)
include ('text91a.txt'); else
include ('text91b.txt');
Листинг 9.2.
Правильное использование include( )
if (some_conditional) :
include ('text91a.txt');
else :
include ('text91b.txt');
endif;
Весь код РНР во включаемом файле обязательно заключается в теги РНР. Не стоит полагать, что простое сохранение команды РНР в файле обеспечит ее правильную обработку:
print "this is an invalid include file";
Вместо этого необходимо заключить команду в соответствующие теги, как показывает следующий пример:
<?
print "this is an invalid include file";
?>
include_once( )
Функция include_once( ) делает то же, что и include( ), за одним исключением: прежде чем включать файл в программу, она проверяет, не был ли он включен ранее. Если файл уже был включен, вызов include_once( ) игнорируется, а если нет — происходит стандартное включение файла. Во всем остальном include_once( ) ничем не отличается от include( ). Синтаксис функции include_once( ):
include_once (file файл)
require ( )
В целом функция require( ) похожа на include( ) — она тоже включает шаблон в тот файл, в котором находится вызов require( ). Синтаксис функции require( ):
require (file файл)
Тем не менее, между функциями require( ) и include( ) существует одно важное различие. Файл, определяемый параметром require( ), включается в сценарий независимо от местонахождения require( ) в сценарии. Например, при вызове requi ге( ) в блоке if при ложном условии файл все равно будет включен в сценарий!
Во многих ситуациях бывает удобно создать файл с переменными и другой информацией, которая используется в масштабах сайта, и затем подключать его по мере необходимости. Хотя имя этого файла выбирается произвольно, я обычно называю его init.tpl (сокращение от «initializaion.template»). В листинге 9.3 показано, как выглядит очень простой файл init.tpl. В листинге 9.4 содержимое init.tpl включается в сценарий командой require( ).
Листинг 9.3.
Пример инициализационного файла <?
<?
$site_title = "РНР Recipes";
$contact_email = "wjgilmore@hotmail.com";
$contact_name = "WJ Gilmore";
?>
Листинг 9.4.
Использование файла init.tpl
<? require ('init.tpl ');?>
<html>
<head>
<title><? print $site_title; ?></title>
</head>
<body>
<? print "Welcome to $site_title. For questions, contact <a href =
Передача URL при вызове require( ) допускается лишь при включенном режиме «URL fopen wrappers» (этот режим включен по умолчанию).
С увеличением размеров сайта может оказаться, что некоторые файлы включаются в сценарий по несколько раз. Иногда это не вызывает проблем, но в некоторых случаях повторное включение файла приводит к сбросу значений изменившихся переменных. Если во включаемом файле определяются функции, могут возникнуть конфликты имен. Учитывая сказанное, мы приходим к следующей функции — require_once( ).
require_once( )
Функция require_once( ) гарантирует, что файл будет включаться в сценарий всего один раз. После вызова requi rе_оnсе( ) все дальнейшие попытки включения того же файла игнорируются. Синтаксис функции requiге_оnсе( ):
require_once(file файл)
Если не считать дополнительной проверки, в остальном эта функция аналогична
require( ).
Вероятно, вы станете чаще использовать функции включения файлов по мере того, как ваши web-приложения начнут увеличиваться в размерах. Эти функции часто встречаются в примерах данной книги, чтобы сократить избыточность программного кода. Первые примеры рассматриваются в следующем разделе, посвященном принципам построения базовых шаблонов.
Include( ) и require( )
Одним из самых выдающихся аспектов РНР является возможность построения шаблонов и программных библиотек и их последующей вставки в новые сценарии. Применение библиотек экономит время и усилия по использованию общих функциональных возможностей на разных web-сайтах. Читатели, обладающие
опытом программирования на других языках (например, С, C++ или Java), хорошо знакомы с концепцией библиотек функций и их использованием в программах для расширения функциональных возможностей.
Включение одного или нескольких файлов в сценарий осуществляется стандартными функциями РНР require( ) и include( ). Как будет показано в следующем разделе, каждая из этих функций применяется в определенной ситуации.
В этой главе вы познакомились
В этой главе вы познакомились с первоочередной задачей, для решения которой и создавался РНР, — динамическим построением web-страниц. Были рассмотрены следующие вопросы:
обработка URL;
построение динамического содержания;
включение и построение базовых шаблонов.
Глава завершается генератором страниц — программой, которая загружает статические страницы в шаблон и позволяет легко организовать поддержку большого количества статических страниц HTML.
Следующая глава посвящена использованию РНР в сочетании с формами HTML, заметно повышающими степень интерактивности вашего сайта. А потом — взаимодействие с базами данных! Вам предстоит узнать много интересного.
Обратите внимание на использование глобальной переменной $site_email в файле колонтитула. Значение этой переменной действует в масштабах всей страницы, а мы предполагаем, что файлы header.tpl и footer.tpl будут включены в одну итоговую страницу. Также обратите внимание на присутствие пути $site_path в ссылке Privacy (Конфиденциальность). Я всегда включаю в шаблоны полные пути ко всем ссылкам — если бы URL ссылки состоял из одного имени privacy.php, то файл колонтитула был бы жестко привязан к конкретному каталогу.
Оптимизация шаблонов
Во втором (на мой взгляд, более предпочтительном) варианте шаблоны оформляются в виде функций, находящихся в отдельном файле. Тем самым обеспечивается дополнительное структурирование ваших шаблонов. Я называю этот файл инициализационным файлом и храню в нем другую полезную информацию. Поскольку мы уже рассмотрели относительно длинные примеры заголовка и колонтитула, содержимое листингов 9.10 и 9.11 было слегка сокращено для наглядной демонстрации новой идеи.
// Содержимое основной части This is some body information
<?
// Вывести колонтитул Show_footer( );
?>
Основная часть
В основной части страницы подключается содержимое заголовка и колонтитула. В сущности, именно основная часть содержит информацию, интересующую посетителей сайта. Заголовок эффектно выглядит, колонтитул содержит полезные сведения, но именно ради основной части страницы пользователи снова и снова возвращаются на сайт. Хотя я не смогу предоставить каких-либо рекомендаций по поводу конкретной структуры страниц, шаблоны, подобные приведенному в листинге 9.7, основательно упрощают администрирование страниц.
Welcome to PHPRecipes. the starting place for PHP scripts, tutorials,
and information about gourmet cooking!
</td>
</tr>
</table>
Построение компонентов
При определении структуры типичной web-страницы я обычно разбиваю ее на три части: заголовок, основную часть и колонтитул. Как правило, в большинстве правильно организованных web-сайтов присутствует заголовок, который практически не изменяется; в основной части выводится запрашиваемое содержание сайта, поэтому она часто изменяется; наконец, колонтитул содержит информацию об авторских правах и навигационные ссылки. Колонтитул, как и заголовок, обычно остается неизменным. Не поймите меня превратно — я вовсе не пытаюсь подавлять ваши творческие устремления. Мне встречалось немало великолепных сайтов, не следовавших этим принципам. Я всего лишь пытаюсь выработать общую структуру, которая может послужить отправной точкой для дальнейшей работы.
Проект: генератор страниц
Хотя в большинстве созданных мною web-сайтов основное содержимое страниц формировалось на основании информации, прочитанной из базы данных, всегда найдется несколько страниц, которые практически не изменяются. В частности, на них могут выводиться сведения о команде разработчиков, контактные данные, реклама и т. д. Я обычно храню эту «статическую» информацию в отдельной папке и использую сценарий РНР для ее загрузки при поступлении запроса. Конечно, у вас возникает вопрос — если это статическая информация, для чего нужен сценарий РНР? Почему бы не загружать обычные страницы HTML? Преимущество РНР заключается в том, что вы можете использовать шаблоны и вставлять статические фрагменты по мере необходимости.
Ссылки для загрузки различных статических файлов строятся динамически. В обобщенной форме ссылка выглядит так:
Начнем с создания статических страниц. Для простоты я ограничусь тремя страницами, содержащими информацию о сайте (листинг 9.12), рекламу (листинг 9.13) и контактные данные (листинг 9.14).
Листинг 9.12.
Информация о сайте (about.html)
<h3>About PHPRecipes</h3>
What programmer doesn't mix all night programming with gourmet cookies. Here at PHPRecipes. hardly a night goes by without one of our coders mixing a little bit of HTML with a tasty plate of Portobello Mushrooms or even Fondue. So we decided to bring you the best of what we love most: PHP and food!
<p>
That's right, readers. Tutorials, scripts, souffles and more. <i>0nly</i> at PHPRecipes.
Листинг 9.13.
Рекламная информация (advert_info.html)
<h3>Advertising Information</h3>
Regardless of whether they come to learn the latest PHP techniques or for brushing up on how
to bake chicken, you can bet our readers are decision makers. They are the Industry
professionals who make decisions about what their company purchases.
For advertising information, contact <a href - "mailto:ads@phprecipes.com
">ads@phprecipes.com</a>.
Листинг 9.14.
Контактные данные (contact.html)
<h3>Contact Us</h3>
Have a coding tip? <br>
Know the perfect topping for candied yams?<br>
Let us know! Contact the team at <a href= "mailto:theteam@phprecipes.com">team@phprecipes.com</a>.
Переходим к построению страницы static.php, которая выводит запрашиваемую статическую информацию. В этот файл (см. листинг 9.15) включаются компоненты страниц нашего сайта и инициализационный файл site_init.tpl.
Если щелкнуть на любой из этих ссылок, в браузере загружается соответствующая статическая страница, внедренная в static.php!
Простые ссылки
По ссылкам пользователь может переходить как на обычные страницы HTML, так и на страницы, содержащие код РНР:
<а href = "date.php"><View today's date</a>
Если щелкнуть на ссылке, в браузере будет загружена страница с именем date.php. Просто, не правда ли? Развивая приведенный пример, можно воспользоваться переменной для построения динамической ссылки:
Вероятно, у вас возник вопрос — почему в коде ссылки перед кавычками (") ставится обратная косая черта (\)? Дело в том, что кавычки в РНР являются специальными символами и используются в качестве ограничителей строк. Следовательно, кавычки-литералы в строках должны экранироваться.
Если необходимость экранировать кавычки вас раздражает, просто включите режим magic_quotes_gpc в файле php.ini. В результате все апострофы, кавычки, обратные косые черты и нуль-символы. в тексте автоматически экранируются!
Разовьем приведенный пример. Для быстрого вывода списка ссылок в браузере можно воспользоваться массивом:
Довольно часто доступ к включаемым файлам со стороны посетителей ограничивается, особенно если эти файлы содержат конфиденциальную информацию (например, пароли). В Apache можно запретить просмотр некоторых файлов редактированием файлов http.conf или htaccess. Следующий пример показывает, как запретить просмотр всех файлов с расширением .tpl:
<Files "*.tpl">
Order allow,deny
Allow from 127.0.0.1
Deny from all
</Files>
РНР и проблемы безопасности сайтов подробно описаны в главе 16.