Индекс со структурой B-Tree
Индекс на основе сбалансированной иерархической структуры, или индекс B-Tree (Balanced Tree structured object), используется как индекс по умолчанию в СУБД Oracle. Эта структура напоминает дерево (если смотреть снизу вверх), в котором сначала считывается самый верхний блок - корневой узел (root), затем блок на следующем уровне - блок-ветвь (branch) и так до тех пор, пока не будет извлечен блок-лист (leaf) с идентификатором строки. Значения ключа сохраняются в индексе (рис. 11.1). Такая структура позволяет сократить до минимума число операций ввода/вывода. Для получения идентификатора строки обычно требуется одно посещение блок-листа, т.е. физической страницы базы данных, отведенной под индекс.
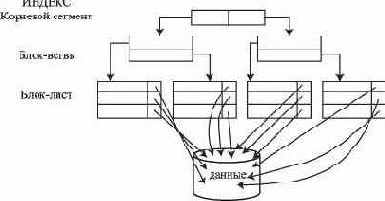
Рис. 11.1. Концептуальная организация B-Tree индекса
Замечание. Следует отметить два случая, когда после выборки идентификатора строки из индекса может понадобиться несколько посещений физической страницы индекса: 1) когда строка имеет длину более одной физической страницы, так называемая расщепленная строка; 2) когда строка за время своего существования в базе данных увеличилась и была перемещена из исходной страницы в другую, так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree - это физический объект реляционной базы данных, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree.
- Количество операций ввода/вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавление новых данных, СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.
- Корневой узел и узлы - ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений.
Узлы-листья содержат полное значение ключа. - Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
- Индекс можно использовать для поиска и точного соответствия, и для диапазона значений.
- Индексы могут быть построены для нескольких колонок таблицы (так называемый составной индекс). СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа. Например, составной индекс {Ename, Job} для обработки запроса SELECT * FROM EMPLOYEE WHERE Job='Инженер'; применяться не будет.
- СУБД обычно само принимает решение, использовать индекс или нет.
- Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться примерять его в некоторых операциях, например ORDER BY.
Индексы создаются командой SQL CREATE INDEX. В предыдущих лекциях мы уже создавали индексы на основе B-Tree. При создании индекса опционально можно задать ряд параметров. Для получения полного списка параметров следует обратиться к документации по СУБД. Применение некоторых параметров будет показано в следующих разделах.
Пример. В нашей учебной базе создадим для таблицы EMPLOYEE составной индекс по колонкам Ename и Job. При этом проектировщик базы данных не уверен, что этот индекс будет использоваться эффективно, поэтому он задал опцию для сбора статистики для этого индекса.
CREATE INDEX emp_ndx2 ON EMPLOYEE (Ename, Job) COMPUTE STATISTICS;
В этом подразделе мы рассмотрели наиболее часто используемый тип индексов. В последующих подразделах и разделах мы рассмотрим другие типы индексов реляционных баз данных.