Создание связывающих таблиц для
Отношения "многие-ко-многим", как уже упоминалось в предыдущих лекциях, не могут быть в подавляющем большинстве случаев непосредственно реализованы в реляционных базах данных без создания промежуточных таблиц, иначе называемых связывающими таблицами (junction tables). Связывающая таблица является базовой таблицей (дочерней) базы данных, которая представляет отношение связи между двумя таблицами (родительскими), находящимися в отношении "многие-ко-многим". Процедура представления отношения "многие-ко-многим" с помощью связывающей таблицы на языке проектировщика базы данных носит название разрешение взаимосвязи (или связи) "многие-ко-многим". Эта задача может быть частично решена на стадии логического проектирования реляционной базы данных. На этой стадии требуется аккуратное воплощение решения этой задачи в операторах SQL.
Алгоритм задачи разрешения взаимосвязи следующий:
- Создать связывающую таблицу (новую таблицу базы данных). Обычно проектировщики баз данных имеют такую таблицу конкатенацией имен двух связываемых таблиц.
- Добавить колонки в связывающую таблицу, как описано в предыдущем разделе. Обязательно добавляются колонки первичных ключей связываемых таблиц, которые образуют первичный составной ключ связывающей таблицы. Убедитесь, что все части составного ключа связываемой таблицы добавлены в связывающую таблицу!
- Определить первичный ключ связывающей таблицы и внешние ключи для связываемых таблиц. Внешним ключом будет часть первичного ключа родительской таблицы, которая ссылается назад к родительской таблице.
Этот алгоритм решает задачу разрешения отношения "многие-ко-многим". Однако можно подумать об атрибутах (колонках), которые могут существовать у связи (ее представляет связывающая таблица). Такие колонки могут быть помещены в связывающую таблицу. Это могут быть колонки, общие для связываемых таблиц.
Рассмотрим пример. Используемая схема базы данных учебного примера не позволяет использовать одного служащего в нескольких проектах (реализовано отношение "много (служащих) к одному (проекту)").
На практике обычно каждый служащий работает над несколькими проектами (отношение "многие-ко-многим"). Чтобы реализовать такое отношение, необходимо модернизировать структуру физической базы данных. Определим отношение "многие-ко-многим" через создание новой таблицы EMP_PRJ
CREATE TABLE EMP_PRJ ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREIGN KEY (EMPNO) REFERENCES EMPLOYEE, FOREIGN KEY (PROJNO) REFERENCES PROJECT, );
которая будет служить для распределения служащих по проектам. В этой таблице каждому служащему отвечает столько строк, сколько проектов он выполняет. Схема базы данных примет теперь вид как на рис. 9.1. Колонка PROJNO таблицы EMPLOYEE при этом потеряла свой семантический смысл. Ee следует удалить из таблицы EMPLOYEE за ненадобностью.
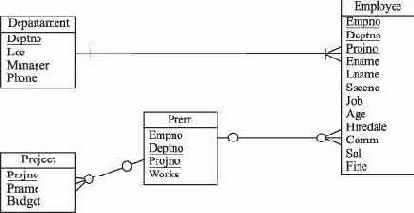
Рис. 9.1. Логическая структура учебной базы данных после разрешения отношения "многие-ко-многим"
Как работать с ограничением внешнего ключа, будет показано далее в соответствующем подразделе.
CREATE TABLE DEPARTAMENT ( DEPNO integer NOT NULL, DNAME char(20), LOC char(20), MANAGER char(20), PHONE char(15), PRIMARY KEY (DEPNO) определение первичного ключа );
CREATE TABLE EMPLOYEE ( EMPNO integer NOT NULL, ENAME char(25), LNAME char(10), DEPNO int, SSECNO char(10), JOB char(25), AGE date, HIREDATE date NOT NULL WITH DEFAULT, SAL dec(9,2), COMM dec(9,2), FINE dec(9,2), PRIMARY KEY (EMPNO) ); CREATE TABLE PROJECT ( PROJNO char(8) NOT NULL, PNAME char(25), BUDGET dec(9,2), PRIMARY KEY (PROJNO) );
CREATE TABLE EMP_PRJ ( EMPNO integer NOT NULL, PROJNO char(8) NOT NULL, WORKS number, PRIMARY KEY (EMPNO, PROJNO), FOREIGN KEY (EMPNO) REFERENCES EMPLOYEE, FOREIGN KEY (PROJNO) REFERENCES PROJECT );
Таким образом, в результате описанных выше действий был получен скрипт для создания базовых таблиц учебного примера. Этот скрипт можно выполнить, чтобы создать базовые таблицы. Но обычно проектировщики баз данных не спешат, а продолжают далее совершенствовать полученный скрипт.
Будем считать разработанный скрипт первой итерацией в создании внутренней схемы базы данных - создании базовых таблиц.
Дальнейшими задачами проектировщика базы данных будут задачи усовершенствования и доработки разработанного скрипта в следующих направлениях:
- добавления ограничений в спецификации колонок (требования непротиворечивости и целостности данных);
- добавление ссылочной целостности (требования целостности данных);
- добавление представлений, синонимов и ряда других опциональных объектов базы данных (требования по разграничению доступа пользователей, частичное обеспечение требований безопасности);
- обеспечение требований производительности базы данных методами, предоставляемыми выбранной СУБД;
- определение пользователей, их авторизация и разграничение полномочий (требования безопасности базы данных).
Первые три направления деятельности носят опциональный характер и определяются особенностями конкретного ИТ-проекта и вкусами руководителя данного проекта, а также требованиями к базе данных и бизнес-правилами предметной области, если они представлены в исходной документации. Часто, особенно при использовании объектно-ориентированной парадигмы в разработке приложений базы данных, эти три направления деятельности проектировщика базы данных могут быть переданы разработчикам приложений базы данных. Поэтому мы подчеркиваем здесь их необязательный характер. Как может решать такие задачи проектировщик базы данных, будет рассмотрено в других разделах этой лекции. Четвертое направление деятельности очень желательно. Его следует выполнять, если априорно имеются данные о возможном поведении данных в системе во времени. Обычно борьба за производительность относится к задачам обратного влияния, когда становятся известными параметры эксплуатации системы. Это направление деятельности будет рассматриваться в двух последу ющих лекциях.
Последнее направление деятельности носит обязательный характер для обеспечения функционирования базы данных, эта задача в большей степени является задачей администратора базы данных - лица, ответственного за эксплуатацию базы данных в организации.
Как решаются такие задачи, будет рассмотрено в следующей лекции.
Ниже приведен типичный синтаксис некоторых команд SQL.
Синтаксис оператора CREATE TABLE:
CREATE TABLE имя_таблицы (имя_колонки тип_данных [NOT NULL | NOT NULL WITH DEFAULT] [, имя колонки ѕ] [PRIMARY KEY (имя_колонки [,имя_колонки ѕ]] [FOREIGN KEY [имя_ключа] (имя_колонки [, имя_колонки ѕ ]) REFERENCES имя_таблицы_родителя [ON DELETE [RESTRICT | CASCADE | SET NULL]]] ) [IN [имя_базы_данных] имя_области_табличного_пространства | IN DATABASE имя_базы_данных] [PCTFREE целочисленная_константа]
Примечание. Здесь и ниже опции операторов SQL, которые не объясняются в настоящем разделе книги, поясняются далее, там, где логика изложения требует их детального обсуждения. Подчеркивание ключевого слова обозначает значение, принятое по умолчанию.
Синтаксис оператора CREATE INDEX:
CREATE [UNIQUE] [CLUSTERED HASHED] INDEX имя_индекса ON имя_таблицы (имя_колонки [ASC | DESC] [, имя_колонки ѕ]) [PCTFREE целочисленная_константа] [SIZE целочисленное_значение [ROWS | BUCKETS]]